An ESP32 paired with ChatGPT works best when the microcontroller handles sensing, control, and connectivity, while the model handles language, interpretation, and planning. That split matters because it keeps firmware lean, reduces security risk, and makes IoT behaviour more predictable. I’ll show the architecture I would use, the hardware choices that matter, and the mistakes that usually waste the first few weeks of a prototype.
The practical version of this setup keeps intelligence off the board and control on the board
- Use the ESP32 as an edge controller: read sensors, trigger actions, and report events.
- Keep the AI layer remote: let the model interpret intent, summarise data, or decide between safe actions.
- Do not store secrets in firmware: API credentials belong on a backend or proxy, not on the device.
- Use HTTPS and certificate validation: plain HTTP is the wrong trade-off for anything connected to the cloud.
- Prefer streaming for slower replies: even a simple text stream feels far more responsive than a blocked request.
- Start with one sensor and one action: the cleanest prototypes are narrow, measurable, and easy to debug.
What the ESP32 should do, and what ChatGPT should do instead
I treat the ESP32 as a small, event-driven device, not as a chat client. Its job is to watch the physical world, send compact data, receive a bounded instruction, and execute that instruction safely. The model’s job is different: it can turn messy human language into structure, decide which action fits the context, and write explanations that a person can understand.
That division is important in IoT because most useful device interactions are not open-ended conversation. They are things like “raise the fan speed,” “explain why the reading changed,” or “turn this noisy sensor stream into a useful summary.” Once you frame the problem that way, the design becomes much simpler. I stop asking whether the board can “run AI” and start asking whether the board can capture events reliably and hand them to the right orchestration layer.
The first mistake I see is trying to make the microcontroller do too much. If the firmware is polling constantly, formatting huge prompts, waiting synchronously for a reply, and also driving actuators, the whole system becomes fragile. The better split is obvious once you say it out loud: the device senses and acts; the model interprets and plans. That leads directly into architecture choices.
The architecture I would choose for an IoT build
For a real project, I would not have the ESP32 call the model endpoint directly unless the demo is tiny and disposable. The better pattern is a small backend or proxy between the device and the model. That layer gives you a place to hide credentials, validate commands, rate-limit requests, enrich prompts with device context, and log what actually happened.
| Pattern | Best for | Strength | Weakness |
|---|---|---|---|
| Direct device-to-model | Very small demos | Simple wiring, fewer moving parts | Weak secret handling, poor policy control, awkward debugging |
| ESP32 to backend proxy to model | Most IoT products and serious prototypes | Secrets stay off the board, commands can be validated, logs are easy to add | One more service to maintain |
| Hybrid local rules plus cloud AI | Reliability-focused systems | Fast local actions, cloud only for interpretation or summary | More design work up front |
If I had to pick one default, I would choose the proxy pattern. It is the least glamorous and the most practical. The ESP32 sends a small JSON payload, the backend decides whether the request is safe and relevant, and the model only sees the data it needs. That gives you a cleaner security boundary and makes later changes much easier.
OpenAI’s Responses API is the interface I would reach for here because it fits stateful, structured interactions and supports streaming. In an IoT project, that matters more than people expect: the system feels better when the first tokens arrive quickly, even if the full answer still takes a moment.
The hardware and firmware choices that change the outcome
Not every ESP32-class board is equally comfortable in a ChatGPT-style project. A basic ESP32 is fine for sensor triggers, button presses, relay control, and simple text requests. If the project includes audio, a display, or heavier buffering, I would move up the stack. Espressif’s reference material for AI voice modules leans toward ESP32-S3 and ESP32-C5-class boards for richer voice interaction and smarter control.
For cloud connectivity, the important part is not the chip name alone but the networking and security stack around it. The ESP HTTP client supports HTTPS with mbedTLS, and that should be the baseline for any external AI call. I would also validate the server certificate chain, either with a CA certificate or a certificate bundle, instead of taking shortcuts just because the device is small.
There are three hardware and firmware details I would pay attention to:
- Memory headroom: if you buffer audio, JSON, or streamed text, extra RAM and PSRAM reduce crashes and ugly edge cases.
- Secure key handling: if the design justifies it, a secure element such as ATECC608 gives you a stronger place to anchor TLS credentials.
- Wi-Fi mode: station mode is the normal choice for cloud calls; access-point mode is useful for setup, provisioning, or local fallback control.
The practical test is simple: if the board can survive a slow network, a dropped request, and a partial response without wedging itself, it is probably good enough for a first release. If it cannot, the model is not the real problem.
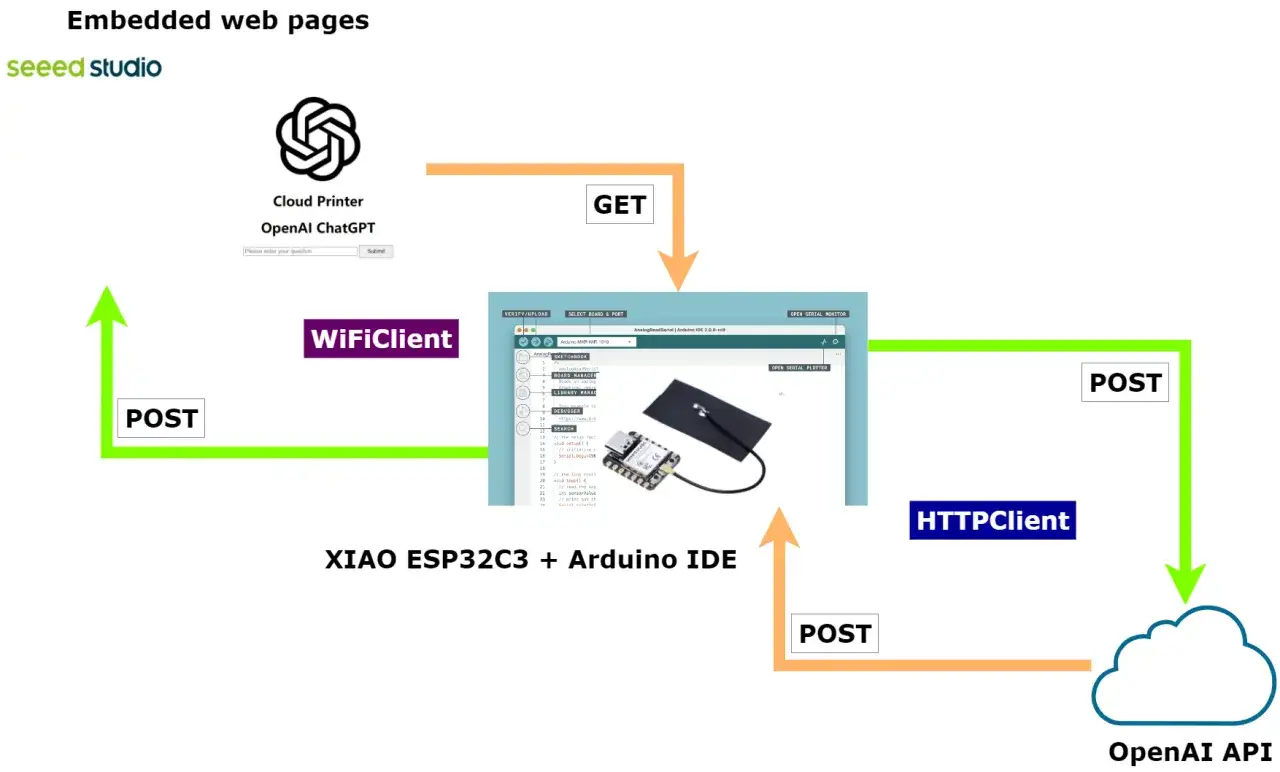
How I would wire the request flow
The safest flow is short and boring, which is exactly why it works. I would build it like this:
- The ESP32 detects an event, such as a button press, threshold crossing, motion trigger, or voice wake word.
- The firmware sends a compact payload to the backend over HTTPS, including device ID, event type, and a small amount of context.
- The backend adds system rules, device policy, and any relevant state before calling the model.
- The model returns either plain language, a structured command, or both.
- The backend validates the response, converts it into a safe action, and sends only the approved command back to the ESP32.
- The ESP32 executes the action, confirms the result, and updates local state.
That is the flow I trust because every boundary is explicit. The model can suggest a change, but it cannot directly touch hardware. If the device controls a heater, a lock, a pump, or anything with real-world risk, that separation is non-negotiable.
Function calling fits neatly into this flow. Instead of asking the model for free-form prose and trying to scrape meaning from it, I would define a small command set, such as `set_fan_speed`, `toggle_relay`, `report_status`, or `summarise_sensor_event`. That keeps the output bounded and easier to test. Streaming then becomes the UX layer on top: the user sees the assistant thinking and responding, rather than staring at a blank screen for several seconds.
Where this combination actually shines in IoT
The strongest use cases are the ones where language reduces friction. I would not use an ESP32 and a model together just because it sounds modern. I would use them where natural language genuinely helps.
- Smart home control: “Make the room warmer” is more forgiving than a rigid app UI, especially when people do not want to remember exact settings.
- Sensor narration: the board can collect readings all day, while the model turns the data into a short human explanation instead of a wall of numbers.
- Maintenance support: if a device is offline, overcurrent, or repeatedly rebooting, the model can generate a concise diagnosis checklist from the device logs.
- Voice front-ends: on ESP32-S3-class hardware, a wake word plus cloud reasoning can produce a surprisingly capable assistant for a workshop, kitchen, or office.
The weak use cases are just as important. I would not send every temperature reading, motion event, or power sample to the model. That wastes tokens, adds latency, and produces very little value after the first few examples. The model should sit at decision points, not at every point.
In a UK home or small workshop, that usually means focusing on utility rather than novelty: clearer alerts, simpler controls, and better explanations when something changes unexpectedly. That is where the combination earns its keep.
The mistakes that turn a good idea into a flaky prototype
I see the same failures again and again, and most of them are avoidable.
- Putting the API key in firmware: if the device can read it, someone else can too. Keep credentials on the server side.
- Blocking the main loop: if the ESP32 waits synchronously for a long cloud response, sensor timing and control logic suffer.
- Sending too much data: the model does not need every raw sample. Clean, compact prompts work better and cost less.
- Skipping timeouts and retries: cloud services fail, Wi-Fi drops, and DNS stalls. The firmware should expect that.
- Letting the model control unsafe actions directly: every critical command should pass through validation rules first.
- Ignoring a fallback mode: a useful IoT device still needs basic local behaviour when the internet is down.
The deeper problem underneath all of those mistakes is the same: people confuse intelligence with robustness. A clever response is not the same thing as a reliable system. For connected devices, the boring parts matter more than the flashy ones.
The build path I would ship first
If I were building this for a real prototype, I would start with one sensor, one action, and one backend proxy. I would log every request, every response, and every failure. Then I would measure three things: latency, command accuracy, and how often the device recovers cleanly after the network drops.
- Start with a narrow trigger, such as a button, motion event, or threshold crossing.
- Return one structured command instead of a long conversational reply.
- Use streaming so the user gets early feedback while the model is still generating.
- Keep unsafe or irreversible actions behind local rules and server-side validation.
- Add voice only after the text path is stable and easy to debug.
That sequence gives you a system that is easier to secure, easier to explain, and much more likely to survive real-world Wi-Fi, power, and latency problems. For an ESP32-based IoT build in 2026, that is the version I would trust first.