
Network resilience is less about buying bigger gear and more about making sure one fault cannot take the whole service down. A network with no single point of failure is only useful if the backups are genuinely independent. In practice, that means thinking about routers, firewalls, circuits, power, DNS, identity, and the management plane as separate failure domains. In this article I break down what that means, where hidden risk usually sits in UK networks, how to design around it, and how to test whether the failover you paid for actually works.
The essentials of resilient network design
- Redundancy only counts when the backup path is physically and logically independent.
- The usual weak spots are circuits, power, edge devices, DNS, and shared cloud dependencies.
- Route diversity matters more than the number of boxes on the diagram.
- Failover has to be tested, not assumed, or it is just optimism with a purchase order.
- The real goal is graceful degradation, not pretending every failure can be eliminated.
What network resilience really means
When I talk about resilience, I am not talking about keeping every packet alive under every possible failure. I am talking about keeping the business usable when parts of the network fail, degrade, or are taken out for maintenance. That is a very different standard from simple uptime, and it is the distinction that usually gets missed.
These terms get blurred together, so I separate them early:
| Term | What it means | What it does not mean |
|---|---|---|
| Redundancy | There is more than one component or path available. | The backup is automatically independent or ready for every scenario. |
| High availability | The service stays reachable through normal failures and maintenance. | It will survive any site-wide or provider-wide incident. |
| Fault tolerance | The system keeps working while one part fails. | It will do so with zero impact or zero engineering trade-offs. |
| Resilience | The network absorbs failure, recovers quickly, and limits the blast radius. | It is immune to bad design, bad change control, or bad testing. |
I also keep recovery measures in view: RTO, or recovery time objective, is how long the business can live with disruption, while RPO, or recovery point objective, is how much data loss is acceptable. AWS Well-Architected guidance is right to insist that you track both and test recovery, because if you have never rehearsed a failover, you are guessing. That theory only becomes useful once you know where the real weak spots hide.
Where hidden failure points usually live
Most outages do not start as dramatic core-network collapses. They start in places people assumed were harmless because they were small, cheap, or boring. In my experience, those are exactly the places to inspect first.
- Access circuits and last-mile fibre can look redundant while still sharing the same duct, cabinet, exchange, or street works. Two services on paper are not two independent paths in reality.
- Edge firewalls and routers become a problem when both units depend on the same control link, the same config sync path, or the same power feed.
- Collapsed core switches are convenient until one chassis failure removes routing, switching, and sometimes management in one hit.
- Power infrastructure is often the real SPOF: one UPS, one PDU, one utility feed, or one rack circuit can take out a perfectly good network stack.
- DNS and identity services are easy to forget because they are not in the packet path, yet they can make the whole network feel dead if authentication, name resolution, or time sync disappears.
- Monitoring and remote access matter because if you cannot see the problem or reach the equipment when production is down, recovery gets slower and more fragile.
- Shared cloud or colocation dependencies can undo a lot of good work if two supposedly separate paths still terminate on one provider edge or one region.
The NCSC is clear that physical failure in the network is a continuity issue, not a minor inconvenience, and I think that is the right framing. Once you know the weak spots, the design question becomes simple: which dependencies deserve duplication, and which just need a safer fallback?
How I would build redundancy into the critical path
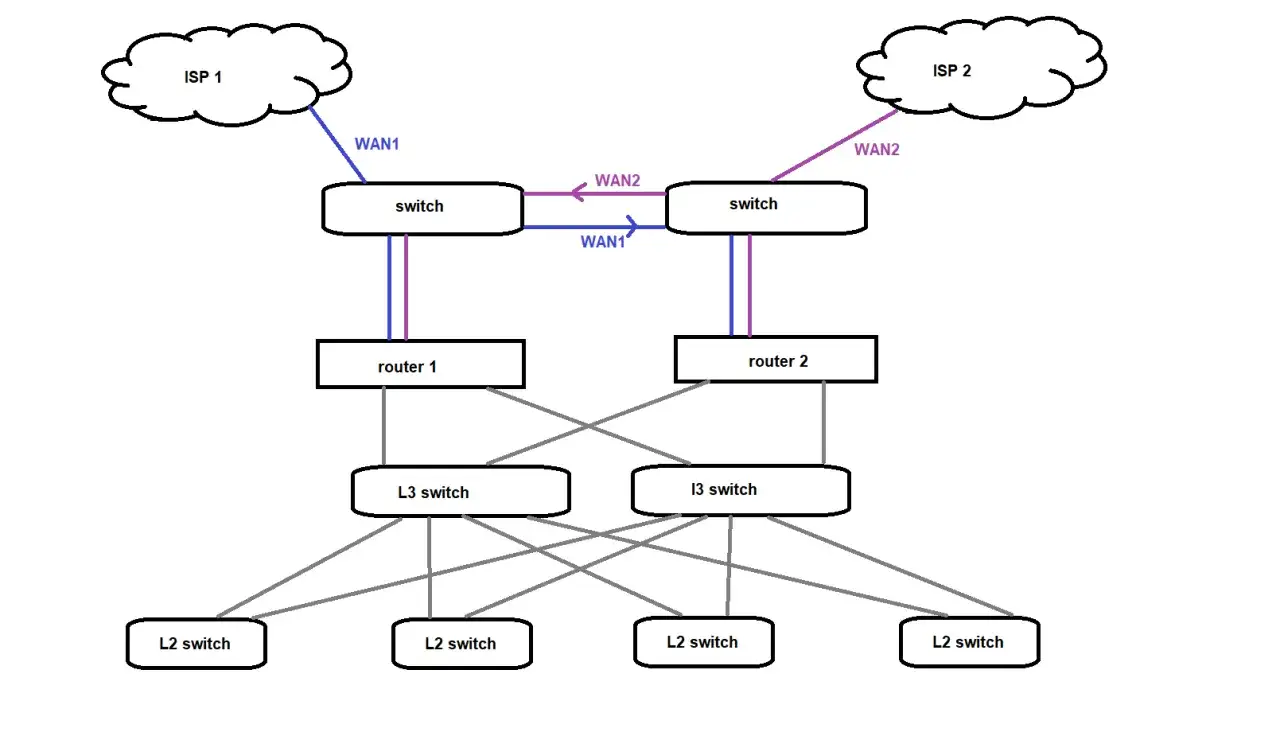
When I design for resilience, I start with the traffic path that matters most: how users get in, how services answer, and how I manage the network when something is already broken. I am not trying to duplicate everything blindly. I am trying to remove the dependency that would turn a local fault into a full outage.
| Layer | What I would duplicate | What I would verify |
|---|---|---|
| Access | Two WAN circuits from different carriers where possible | Separate physical routes, separate building entry points, and separate upstream handoff |
| Edge | A firewall or router pair with automatic failover | Independent power, tested state sync, and clean takeover under load |
| First hop | Gateway redundancy such as VRRP or an equivalent | Clients keep the same default gateway even when the active device changes |
| Core | Dual core switches or a split-core design | No single chassis or common backplane that can remove the whole core at once |
| Services | DNS, DHCP, authentication, and monitoring in secondary locations | Users can still resolve names, sign in, and be observed when a site is down |
| Power | Dual PSUs, UPS support, and ideally generator-backed runtime for critical sites | Separate feeds, realistic battery runtime, and a load test under real conditions |
| Management | Out-of-band access and configuration backup | I can still reach the gear when the production network is unavailable |
I also pay attention to routing behaviour. In larger networks, BGP multi-homing can give you more than one upstream path, but it only helps if the advertisements, timers, and monitoring are actually tuned and watched. For the LAN, equal-cost multipath can spread traffic across independent links, but it is not magic; it works best when the underlying paths are truly separate and the failure domains are cleanly defined.
Active-active and active-passive designs both have a place. Active-active makes better use of hardware and can improve performance, but it also demands more discipline around state, symmetry, and load balancing. Active-passive is simpler to operate, which is often the better answer for smaller teams, but it must still be tested under failure, not just during a clean maintenance window. The design is not complete until you ask where those duplicate paths actually travel.
Why route and supplier diversity matter more than box counts
In the UK, the biggest trap is assuming that two services equal two independent services. They often do not. Two broadband lines in the same building can still share the same underground route, the same street cabinet, the same exchange, or the same provider backhaul. That means your diagram looks resilient while your ductwork does not.
- Separate circuits are not enough if they share the same trench or entrance. I want proof of physical diversity, not just two order numbers.
- Different carriers help, but only if they do not converge too early in the network. The handoff point matters as much as the logo on the invoice.
- Geographic separation matters for core sites, especially if one building flood, power issue, or maintenance event can affect both ends of the link.
- Mobile backup is useful as a survivability layer, but I treat it as emergency transport, not a primary production path for heavy traffic.
- Cloud connectivity needs the same discipline as on-prem links. Private circuits, VPNs, and internet breakouts should not all collapse into one hidden dependency.
This is where supplier diversity earns its keep. A second line from the same provider can still be worthwhile, especially for failover capacity, but it is not the same as genuine path diversity. If the goal is continuity, I care less about the number of interfaces and more about whether a backhoe, a cabinet fault, or a provider incident can still take both paths down at once. That is why route diversity matters more than the number of boxes on the diagram.
How I would test failover before an outage does
Testing is the point where good intentions stop hiding. The best architecture in the world is only as strong as the last failover test, and if that sentence sounds harsh, it is because real outages are harsher. The simplest way to frame it is this: AWS Well-Architected guidance tells teams to track RTO and RPO, and I would add that they need to rehearse the recovery until it stops being theoretical.
| Availability target | Maximum downtime per year | What it usually implies |
|---|---|---|
| 99.9% | About 8 hours 46 minutes | Basic redundancy and some tolerance for manual intervention |
| 99.95% | About 4 hours 23 minutes | Stronger failover, tighter monitoring, and less room for operator delay |
| 99.99% | About 52 minutes | Automatic failover, tested recovery, and genuinely separate failure domains |
| 99.999% | About 5 minutes 15 seconds | Very mature operations, tightly controlled change management, and deeper site or path diversity |
- Pull one WAN circuit and watch whether traffic moves cleanly to the other path without user-visible collapse.
- Kill the primary firewall or router and measure how long sessions take to recover, not just whether the link comes back green.
- Remove one power feed to prove that dual PSUs and UPS design are real, not decorative.
- Test DNS failover with realistic TTL values. If critical records sit at 24 hours, your recovery will feel slow no matter how good the rest of the design is.
- Check management access during failure because emergency access that only works in the happy path is not useful.
- Simulate maintenance as well as failure because a network that only survives surprise outages but not planned change is still brittle.
If a design claims 99.99% availability but failover takes 20 minutes, something is off. The numbers and the runbooks should agree. Testing closes the loop, but it also exposes the trade-offs you still have to live with.
The trade-offs that keep resilient networks honest
Redundancy is valuable, but it is never free. I would rather have a slightly simpler design that the team can operate well than a beautifully redundant network that nobody trusts during an incident. The art is deciding where duplication gives real business value and where it just creates noise.
- Cost rises quickly because you are paying for extra circuits, licences, support contracts, rack space, and maintenance windows.
- Complexity rises too because every extra path needs monitoring, patching, documentation, and a tested runbook.
- Stateful systems can fail awkwardly if asymmetric routing, session tables, or config sync are not handled properly.
- Hidden shared dependencies remain if both paths still rely on the same identity service, DNS resolver, or cloud edge.
- Security becomes more demanding because management ports, sync links, and backup access paths now need the same protection as production traffic.
The most common mistake I see is spending money on extra hardware while leaving observability and operational discipline underfunded. Another one is assuming that more layers automatically mean more resilience. Sometimes the best answer is to remove a shared dependency first, then add one carefully chosen backup path. For a smaller UK business, that might mean dual WAN, a properly configured firewall pair, off-box configuration backups, and a tested failover policy rather than duplicating every switch in sight. That is how I keep the design realistic instead of ceremonial.
The checks I use before I trust the design
Before I would call a network robust, I run a short set of questions that force hidden assumptions into the open. If any answer is vague, I keep digging.
- Can one fault still take the network down? I look for any circuit, switch, firewall, power feed, or identity service that can still stop the business by itself.
- Are the backup paths truly independent? Different labels do not matter if the routes, ducts, racks, or backhaul still converge too early.
- How fast does failover really happen? I want a measured answer, not a hopeful one.
- Can I manage the network during an outage? If not, recovery will be slower than the diagram suggests.
- Have we tested the ugly cases? Link loss, device loss, power loss, maintenance windows, and configuration drift all deserve a rehearsal.
- Does the design still work after growth? A network that was resilient at 50 users can become fragile at 500 if the same assumptions are left untouched.
When I can answer those questions cleanly, I know I am close to a design with no single point of failure. More importantly, I know the network will behave sensibly under stress instead of only looking good on paper.