A useful network management definition is the discipline of keeping a network visible, secure, and reliable enough that people and applications can actually depend on it. In practice, that means watching performance, controlling configuration, handling faults quickly, and making sure changes do not create new risk. For a UK business running office Wi-Fi, cloud services, and remote work at the same time, it is the difference between a stable platform and constant firefighting.
Key takeaways at a glance
- Network management covers monitoring, configuration, fault handling, security, and performance.
- The classic FCAPS model still explains the job well, even in cloud-heavy environments.
- Modern teams rely on telemetry, logs, configuration control, and central visibility, not just manual checks.
- Good management reduces downtime, drift, and security blind spots.
- The best results come from clear ownership, disciplined change control, and fast recovery.
What network management actually covers
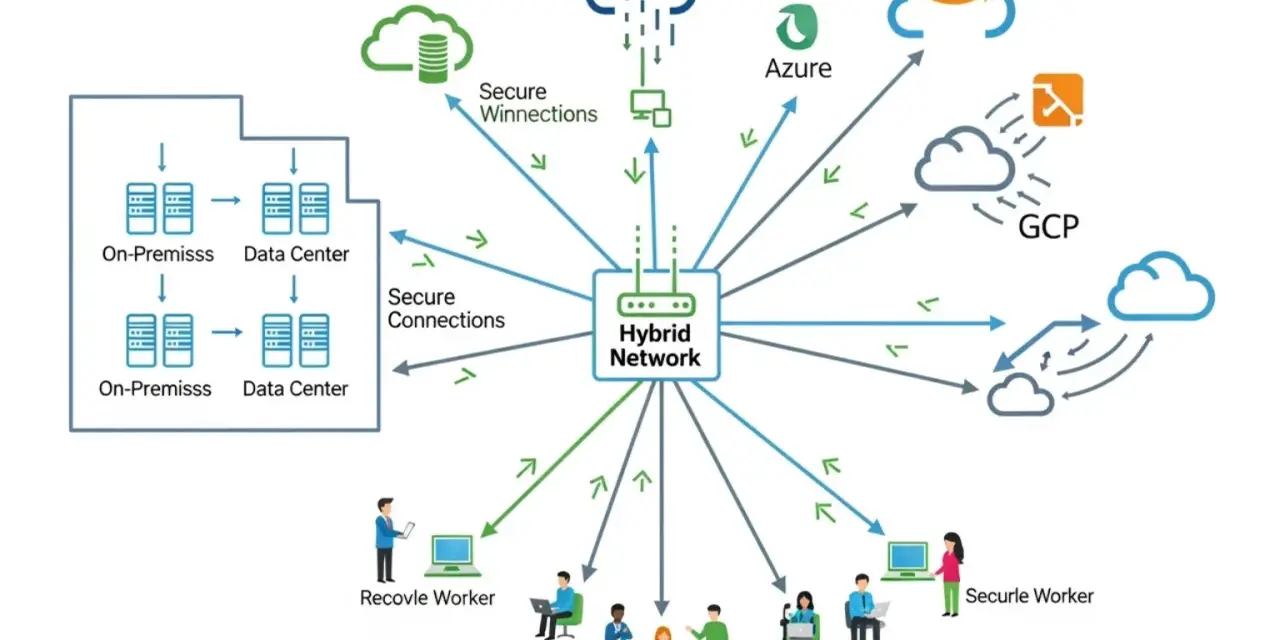
I like to separate network management from the broader idea of networking. Networking is about connecting devices and services; network management is the operational discipline that keeps those connections usable, predictable, and safe over time. It reaches across routers, switches, wireless access points, firewalls, SD-WAN links, VPNs, cloud connections, and the policies that tie them together.
In a practical sense, I would expect managed networks to have a clear inventory, stable configuration baselines, live performance monitoring, documented ownership, and a repeatable way to respond when something breaks. If those pieces are missing, the network may still function, but it is usually being run by memory and luck rather than by process.
For a UK retailer with branches in Manchester, Leeds, and Glasgow, for example, management is not just about keeping the internet up. It is about making sure card payments, voice traffic, guest Wi-Fi, and remote support all behave properly without one department accidentally disturbing another. That broader view becomes much easier to handle once you break the work into functional areas.
- Visibility shows what is connected and how it is behaving.
- Control keeps device settings, access, and policy aligned with intent.
- Assurance confirms the network is performing as expected under real load.
- Recovery gives you a fast path back when a change or fault causes trouble.
That is the point at which the classic management model becomes useful, because it gives structure to work that otherwise turns into a pile of disconnected tasks.
The five functional areas behind the job
The most durable way to explain network management is through FCAPS, the five functional areas used in the classic model. I still find it helpful because it stops teams from over-focusing on alarms while ignoring configuration drift, audit trails, or capacity planning. It also makes clear that security is not an isolated add-on. It touches everything else.
| Area | What it covers | Why it matters |
|---|---|---|
| Fault management | Detecting, isolating, notifying, and correcting failures or abnormal behaviour | Reduces downtime and shortens incident response |
| Configuration management | Tracking device settings, inventory, software versions, and approved changes | Prevents drift and makes rollback possible |
| Accounting management | Understanding resource usage, ownership, and sometimes chargeback or capacity allocation | Supports planning and fair use of infrastructure |
| Performance management | Measuring latency, loss, throughput, jitter, and service quality | Keeps the network usable for real workloads, not just in theory |
| Security management | Access control, segmentation, policy enforcement, and security monitoring | Limits exposure and helps detect abuse faster |
What I take from FCAPS is simple: a network is not well managed just because it is online. It is well managed when faults are handled quickly, changes are controlled, performance is measured honestly, and access is limited to the right people and systems. The next question is how you actually see all of that without drowning in noise.
The tools and signals that keep a network visible
Visibility comes from collecting the right signals and putting them in a form operators can act on. In older environments, that often meant SNMP polling, syslog, and occasional manual checks. In 2026, most serious teams also use streaming telemetry, flow records, API feeds from cloud platforms, and configuration backups that can be compared over time.
I would not treat any single tool as a complete answer. A network management system gives you the control plane for the infrastructure, but it is only as useful as the data feeding it. Logs tell you what happened, telemetry tells you what is happening now, and configuration history tells you whether the current state matches what you expected.
| Signal | Best for | Trade-off |
|---|---|---|
| SNMP polling | Basic device status, interface counters, broad compatibility | Can be slower and less granular than newer methods |
| Streaming telemetry | Near real-time performance and health data | Needs more modern infrastructure and cleaner data handling |
| Syslog | Events, warnings, and troubleshooting trails | Useful only if messages are normalised and reviewed |
| Flow data | Traffic patterns, application paths, and capacity questions | Can be voluminous and needs careful interpretation |
| Config backups | Drift detection, rollback, and auditability | They help only if changes are stored, compared, and tested |
When those signals are stitched together properly, the network stops being a black box. That matters even more once security and resilience enter the picture, because modern infrastructure is expected to keep working under stress, not only during calm periods.
Why network management is now tied to security and resilience
I do not think network management can be separated cleanly from security anymore. The same devices that route traffic also enforce segmentation, inspect flows, and limit access. If configuration drifts, or if privileged access is too broad, the operational problem quickly becomes a security problem as well.
That is especially true in hybrid environments. A London office, a home worker in Edinburgh, a cloud workload in another region, and a branch firewall in Cardiff all rely on the same management discipline even if they sit on different platforms. If one segment fails, the real question is not just whether traffic can reroute. It is whether the business can still authenticate users, protect data, and keep critical applications alive.
- Security improves when changes are logged, segmented, and reviewed.
- Resilience improves when failover paths, backups, and rollback plans are tested before an incident.
- Compliance becomes easier when device ownership, access control, and audit trails are consistent.
- Incident response is faster when the network team can see traffic, identify drift, and isolate affected systems quickly.
This is why a modern management approach usually sits alongside zero trust thinking rather than around an old perimeter model. The network still matters, but it is managed as part of a wider control system. Once that is clear, the operational workflow becomes much easier to design.
A practical workflow for a modern network team
Good network management looks less like heroics and more like a disciplined loop. I prefer a workflow that makes ownership, visibility, and recovery obvious before the first real incident happens. That approach is boring in the best possible way, because it reduces the number of surprises.
- Build a complete inventory. Track devices, links, software versions, critical sites, cloud dependencies, and ownership.
- Set a baseline. Record normal latency, utilisation, error rates, and application behaviour so you know what “good” looks like.
- Standardise configuration. Use templates, version control, and approved change windows so every device does not become its own special case.
- Collect the right telemetry. Focus on the metrics that help you make decisions, not just the ones that look impressive on a dashboard.
- Tune alerts carefully. Alerts should point to action, not produce constant background noise that trains people to ignore them.
- Test recovery. Backups, rollback steps, and failover behaviour should be rehearsed before a real outage forces the issue.
- Review and improve. After incidents or major changes, update baselines, remove blind spots, and automate repeatable work where it actually saves time.
I find this sequence useful because it turns network management into an operating process rather than a dashboard habit. From here, the main danger is not lack of tools. It is the habits that quietly undermine the whole system.
Common mistakes that make the job harder
Most network pain is self-inflicted. The technology is rarely the only problem. The bigger issues are unclear ownership, weak change control, and a tendency to confuse activity with control. I see the same mistakes repeatedly, even in mature environments.
- Monitoring without management. A network can generate endless alerts and still have no disciplined process behind it.
- Ad hoc change making. Small undocumented tweaks are one of the fastest ways to create drift and surprise outages.
- Too much trust in manual checks. Human spot checks are useful, but they are not a substitute for automated visibility.
- No rollback plan. If a change cannot be reversed quickly, the team is taking unnecessary operational risk.
- Poor dependency mapping. When teams do not know which applications rely on which links or firewalls, incident response becomes guesswork.
- Alert noise. Too many low-value alerts push teams to miss the ones that matter.
The pattern behind all of these is the same: the organisation added complexity faster than it added control. That is why the next step is rarely to buy another platform. It is to stabilise the parts that matter most.
What I would stabilise before the next change
If I were tightening a network management programme in a UK organisation right now, I would focus on a short list of fundamentals before adding more sophistication. The goal is not to collect more data for its own sake. The goal is to make the infrastructure easier to trust.
- One reliable inventory. Know what exists, where it sits, and who owns it.
- Configuration control. Store backups, compare versions, and make rollback routine.
- Clear operational ownership. Every critical segment should have a named team and escalation path.
- Identity-aware access. Restrict privileged changes and log them consistently.
- Metrics that match business impact. Measure latency, loss, jitter, and availability around the services people actually use.
- Recovery rehearsals. Test how the network behaves when a link, controller, or site fails.
That is the practical meaning behind network management in 2026: not just watching packets move, but running the infrastructure as a controlled system that can absorb change, recover quickly, and support the business without drama. If you start with visibility, discipline, and recovery, the rest of the stack becomes much easier to scale.