An effective IoT business strategy is not a gadget-buying exercise. It is a decision about which operational problems you want to see sooner, fix faster, or automate entirely, and which data you need to trust before you scale. In the UK, that matters even more because cyber risk, fragmented sites, and compliance pressure can erase the upside if the programme is treated as a side project. This article breaks down where IoT creates value, how to shape the architecture, what security must be built in, and how to test the economics before you commit to a full rollout.
The decisions that matter before you buy a single sensor
- Start from a business KPI, not a device catalogue.
- Pick use cases with short feedback loops, such as downtime, energy, shrink, or asset visibility.
- Match connectivity to environment, power, and data volume before you lock in a vendor.
- Design security, patching, and device retirement from day one.
- Use a pilot to prove one measurable outcome, then scale only if the operating model holds.
Start with a business outcome, not with the hardware
I like to begin every connected-device programme with one question: what business decision becomes easier because this data exists? If that sentence is vague, the project will drift. If it is sharp, the rest of the design becomes much easier to judge.
The strongest use cases usually sit where a process is already expensive, noisy, or hard to supervise in real time. That is where telemetry turns into value instead of noise.
| Business problem | What you instrument | Typical outcome |
|---|---|---|
| Unplanned downtime | Vibration, temperature, runtime, fault codes | Earlier intervention and fewer stoppages |
| Energy waste | Occupancy, meter data, HVAC status | Lower utility spend and better comfort control |
| Spoilage or shrink | Temperature, humidity, door events, location | Fewer losses and cleaner compliance evidence |
| Slow field response | Asset health, usage, location, service history | Fewer truck rolls and faster repairs |
| Poor auditability | Access logs, environmental history, maintenance traces | A stronger evidence trail for internal and external review |
The pattern is simple: if the data does not change a decision, the business case is weak. Once that is clear, it becomes much easier to decide which operational areas deserve connected devices first.
That naturally leads to the next question: where does IoT create the fastest and most believable payback?
Choose use cases where the payback is visible
Not every process deserves sensors. I would only prioritise a use case when it has recurring cost, a clear owner, and a visible operating pain that the team already feels.
Manufacturing and maintenance are often the clearest starting point. If a line stops unexpectedly, the cost is rarely just the repair; it is the idle labour, the missed order, and the restart chaos around it. Basic condition monitoring can deliver more value than a huge platform because the maintenance team can act on it immediately.
Logistics and cold chain operations benefit from simple telemetry that tells a better story than a spreadsheet ever will. Temperature, location, and door-open events are usually more useful than raw location alone because they connect directly to loss prevention and accountability. The business payoff is fewer disputes, fewer rejected goods, and less time spent reconstructing what happened after the fact.
Retail, hospitality, and property teams often get the quickest win from energy, occupancy, leak detection, and building controls. In these environments, the data is only useful if it feeds the people who already run the site. A live dashboard is not the point; a faster response to waste, comfort issues, and equipment faults is.
Utilities and field assets are a different case again. Remote equipment is expensive to inspect manually, which makes it a strong candidate for exception-based monitoring. IoT earns its keep when it reduces unnecessary visits or catches failures before a customer notices them.
The common thread is this: choose a use case with a measurable outcome and a person who owns that outcome. That brings us to the technical layer, where many projects go wrong for reasons that have nothing to do with the sensor itself.
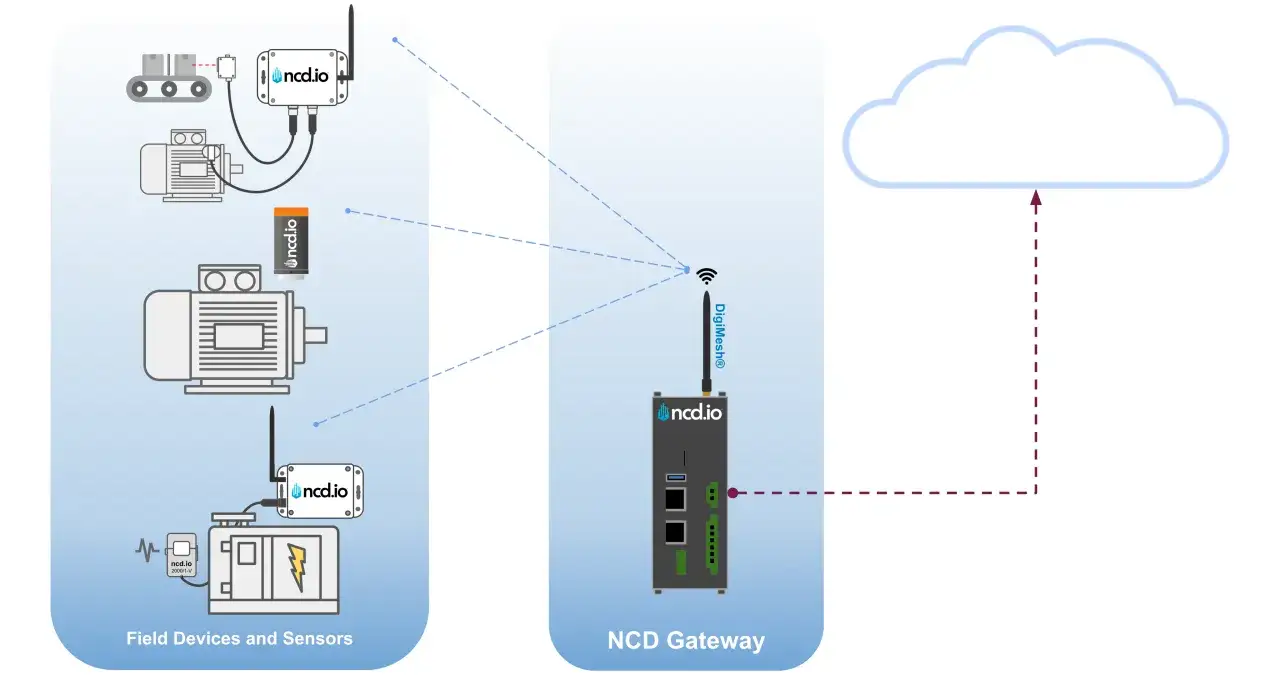
Build the architecture around the environment, not around the dashboard
Most IoT disappointments come from buying the dashboard before deciding where the data lives, how it travels, and who acts on it. I start with the flow: device, gateway or edge layer, connectivity, platform, analytics, and workflow. If any of those steps is fuzzy, the system will be fragile in production.
The connectivity choice should come from the site, not from the marketing deck. Different environments reward different trade-offs:
| Option | Best for | Strength | Trade-off |
|---|---|---|---|
| Wi-Fi | Offices, retail stores, indoor sensors | High throughput and familiar operations | Coverage gaps, congestion, and power use |
| Cellular | Mobile assets and dispersed sites | Wide coverage and managed service | Recurring SIM costs and variable latency |
| LPWAN / LoRaWAN | Battery sensors, campuses, estates | Long battery life and low per-device cost | Low bandwidth and gateway planning |
| Ethernet / PoE | Fixed equipment, cameras, industrial lines | Stable power and reliable links | Cabling cost and less flexibility |
| Private 5G | Factories, ports, large campuses | Control and segmentation | Higher capex and specialist skills |
I also separate edge and cloud early. Edge computing means processing data close to the device rather than sending everything to a remote platform first. I prefer it when latency matters, when bandwidth is limited, or when the site has to keep working if the link drops. Cloud still matters for fleet views, cross-site benchmarking, and long-term analytics. Most serious deployments use both.
Integration is the part that makes the system operational instead of decorative. If the output does not reach the CMMS, ERP, BMS, or workflow tool your team already trusts, it becomes another screen, not a better process. Once the architecture is grounded, the next gate is security, and that is where the real discipline starts.
Security and compliance are part of the business case
This is where many teams underinvest, then pay for it later. GOV.UK says the UK consumer connectable product security regime came into effect on 29 April 2024, and the government estimates cyber attacks cost UK businesses £14.7 billion a year. The baseline requirements are straightforward but non-negotiable: no universal default passwords, a way to report security issues, and a published minimum security update period. For enterprise-connected devices, the NCSC’s device security principles cover nine areas, from secure updates to robust device management. The practical lesson is clear: securing one component does not secure the whole system. You need the device, the network, the platform, and the operating model to line up.- Use unique credentials and role-based access, not shared logins.
- Encrypt data in transit and at rest wherever the architecture allows.
- Segment sensor traffic from core business systems instead of flattening the network.
- Plan over-the-air patching with a real service-level target, not a best effort.
- Keep a vulnerability disclosure path and an incident contact in place.
- Maintain a device inventory, including ownership, support status, and retirement date.
If a device cannot be patched, identified, or retired cleanly, it is not production-ready. Once security is designed in, you can move to the pilot with far fewer surprises.
Run a pilot that tests the economics, not just the technology
I keep the first pilot small on purpose: one process, one owner, one vendor stack, and usually one or two sites. An 8- to 12-week window is enough to learn whether the system changes behaviour or just produces reports.
- Set a baseline before the hardware arrives. Capture current downtime, energy use, spoilage, or truck-roll volume for at least a few weeks.
- Pick one primary KPI and, at most, two secondary metrics. More than that usually blurs the decision.
- Define failure modes before launch. Ask what happens if the gateway drops, the sensor drifts, or the link goes dark.
- Train the people who will act on the alert. If an operator has to check a second system to understand it, response time gets worse.
- Write the scale rule in advance. Decide what result justifies rollout, what result means redesign, and what result means stop.
I am much less interested in whether the pilot looks impressive than whether it behaves honestly in real conditions. If it cannot survive the messiness of an ordinary week, it will not survive scale.
Once the pilot has proven value, the next job is governance. That is what turns a promising test into a durable capability.
Measure, govern, and keep the system useful
After launch, the hard part is keeping the system useful instead of merely deployed. The best teams measure both the business result and the health of the connected-device estate.
| Metric | Why it matters |
|---|---|
| Device uptime | Shows whether the fleet is stable enough to trust |
| Data completeness | Flags sensor drift, dead spots, and connectivity problems |
| False alert rate | Tells you whether operators still trust the alerts |
| Patch latency | Measures exposure after a vulnerability is discovered |
| Mean time to repair | Shows whether operations actually improved |
| Energy or cost per site | Confirms whether the business case still holds |
Ownership matters just as much as measurement. I would always name one operational owner, one security owner, and one person responsible for vendor management. If nobody owns the alert queue or the patch window, the project slowly becomes everyone’s problem and no one’s job.
Contract terms deserve the same attention. I want to see support periods, firmware update commitments, API access, data export rights, spare-part availability, and a clear end-of-life plan. A device that loses support is not an asset; it becomes a liability with a power cable.
After that, the final risk is organisational rather than technical: the mistakes that quietly kill the programme before it matures.
The mistakes that quietly kill IoT projects
I see the same failure pattern again and again. The technology works, but the business never really receives the benefit because the operating model was never designed around it.
- Starting with the device instead of the process.
- Automating a broken workflow and expecting a better result.
- Ignoring connectivity dead zones, battery limits, and power availability.
- Leaving cybersecurity for later, when it should be part of procurement.
- Deploying alerts without naming the person who must act on them.
- Locking into a platform without clear exit terms or data portability.
- Scaling before one site has proven the operating model.
The biggest mistake is usually not technical brilliance gone wrong. It is weak ownership: a pilot that impresses stakeholders but never lands inside operations. A short roadmap is the cleanest way to avoid that trap.
A 90-day roadmap that keeps the project honest
If I were introducing connected devices into a UK business right now, I would keep the first 90 days brutally practical.
- Days 1 to 30: choose one problem, baseline the current process, map the data you already have, and check the legal and security constraints that apply.
- Days 31 to 60: shortlist vendors, pick the connectivity model, define the architecture, and write the support, patching, and integration requirements.
- Days 61 to 90: deploy the pilot, train the operators, watch the metrics, and decide whether to scale, redesign, or stop.
The version of IoT that lasts is usually the calm one: one problem, one owner, one architecture, and one evidence trail. That is what turns connected devices into a real operating advantage rather than another expensive layer of software and hardware.