
Connected products are won or lost long before the first firmware update ships. The hard part of designing for IoT is making power, connectivity, security, data flow, and support behave like one system once the device leaves the bench and enters real homes, offices, or industrial spaces. I focus on the decisions that keep a product reliable, supportable, and safe after installation, because that is where most IoT ideas either become durable services or turn into expensive prototypes.
The practical priorities that matter most before you build
- Start with the device’s job and define what should happen when it is offline, delayed, or tampered with.
- Choose connectivity from the environment backwards, using power, range, and latency as the real constraints.
- Make security structural: unique identities, signed updates, and a clear vulnerability-reporting path.
- Design telemetry, retention, and processing rules before you design the dashboard.
- Plan the update path, support window, and failure recovery before launch, not after.
Start with the job the device must actually do
I start by separating three product types: passive monitoring, active control, and safety-relevant intervention. A temperature logger can tolerate delay; a heating controller can tolerate a brief reconnect; an access system or alarm usually cannot. Once that distinction is clear, the architecture stops being abstract and becomes a set of explicit trade-offs.
The most useful question I ask is simple: what is the device allowed to get wrong? That answer tells me how much local intelligence I need, whether the cloud must be in the loop, and how aggressively I need to preserve state when connectivity drops. A good IoT design is rarely about adding more features. It is about making the core behaviour predictable under bad conditions.
Monitor, control, or intervene
Monitoring systems can usually buffer, retry, and summarise. Control systems need faster feedback and tighter state management. Intervention systems, especially anything that affects access, safety, or physical equipment, need a clear fallback mode and a much stricter error budget. I would not design those three categories the same way, even if they share the same radio or cloud backend.
Decide what happens when the network disappears
I always define offline behaviour early. Should the device cache readings, keep running locally, fail safe, or stop entirely? That choice affects storage, battery life, and the user experience far more than most teams expect. If you do not decide this up front, the product will decide for you later, usually in the worst possible way.
Once the use case is explicit, the next decision is how the device should move data reliably without wasting power or forcing the wrong architecture.
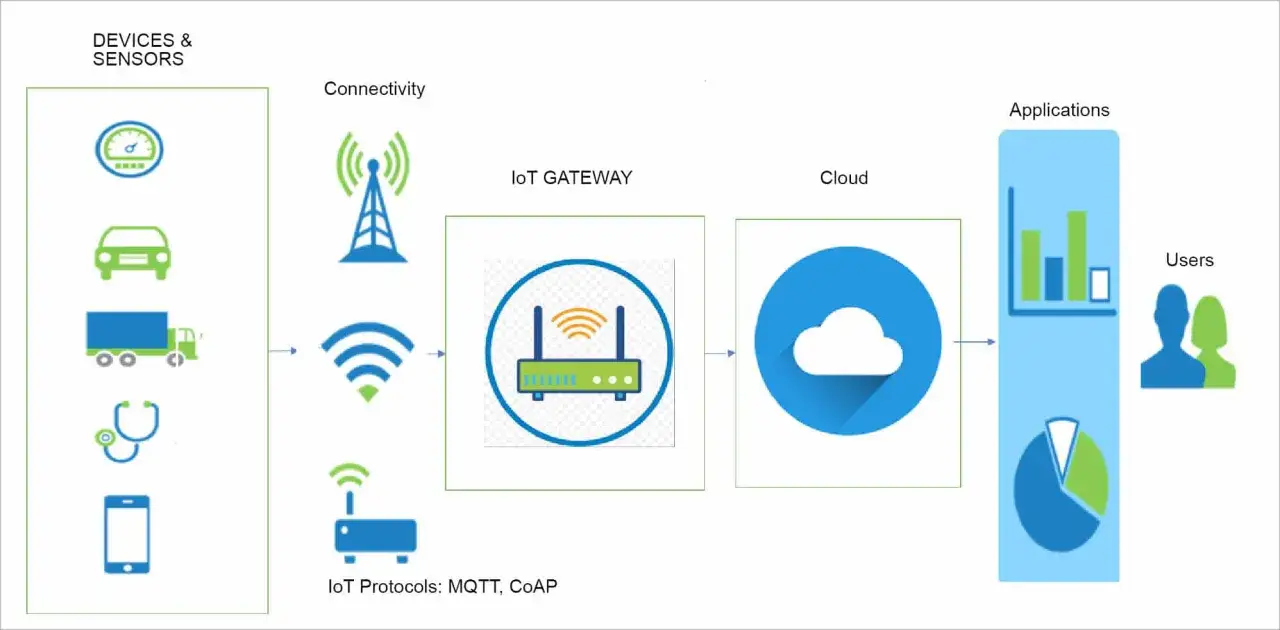
Build the architecture around power, connectivity, and latency
I usually choose the transport after I understand the power budget and the physical environment, not before. A mains-powered gateway can afford more radios and more chatter; a battery sensor often cannot. The right answer is rarely the most advanced network. It is usually the one that matches the device's duty cycle, range, and installation reality.
Transport is only half the story. For machine telemetry, MQTT, a lightweight publish/subscribe protocol, is still a sensible default for many constrained devices because it keeps messages small and reconnects predictable. I use HTTP when the device is not heavily constrained or when the integration surface is intentionally simple, but I never choose it blindly just because the development team already knows it.
| Connectivity option | Best fit | Strengths | Trade-offs |
|---|---|---|---|
| Wi-Fi | Mains-powered consumer devices, cameras, appliances | High throughput, familiar tooling, easy cloud access | Power-hungry, crowded spectrum, depends on local network quality |
| BLE | Phone-paired devices, setup flows, wearables | Very low power, good for commissioning and short bursts | Short range, usually needs a companion gateway or phone |
| Thread or Zigbee | In-building sensors, lighting, mesh networks | Low power, resilient mesh behaviour, good for dense installs | More commissioning complexity, careful network planning needed |
| LTE-M or NB-IoT | Remote assets, metering, outdoor telemetry | Wide-area reach, no local router required | Carrier dependency, recurring cost, variable latency |
| LoRaWAN | Low-throughput, long-range sensing | Long range, low energy use, efficient for sparse data | Low payloads, limited downlink, regional planning required |
| Ethernet | Fixed industrial or commercial installations | Stable, predictable, easy to power alongside data | Cabling cost, physical constraints, less flexible placement |
Thread and Matter can reduce fragmentation in home and light-commercial products, but they do not remove the need to design onboarding, fallback, and updates properly. I still treat the local network, the app, and the cloud as separate failure domains. That is the only way to keep a device useful when one layer fails.
When the connectivity choice is honest, the next question is whether the security model can survive contact with the real world.
Make security the baseline, not a feature
For consumer products sold in the UK, the baseline is no longer vague. The GOV.UK guidance for consumer connectable products, ETSI EN 303 645, and the NCSC's device security principles all point to the same fundamentals: no universal default passwords, a route for vulnerability reporting, and a clear update story. That is not a premium tier. It is the minimum sensible starting point.
Identity and keys
I never accept a fleet that shares a factory password or a single secret across devices. Each unit should have its own identity, and ideally its own certificate or key pair. A secure element, which is a small chip that stores cryptographic keys away from the main processor, is worth the extra cost when the device is exposed in the field.
That approach limits blast radius. If one device is compromised, the attacker should not automatically gain access to the rest of the fleet. I see that mistake more often in early prototypes than in mature systems, and it is one of the cheapest things to fix before production.
Read Also: ESP32 & ChatGPT IoT - Build Robust Systems, Avoid Pitfalls
Updates and disclosure
Signed firmware, secure boot, and rollback support should be present from the start. Secure boot means the device verifies trusted code before it runs it. Signed updates mean the device only installs firmware that can be authenticated. Rollback means a bad update does not strand the fleet. Without all three, OTA support is a liability disguised as a feature.
- Unique per-device credentials stop one compromise from spreading across the fleet.
- Signed updates with rollback let you patch safely and recover quickly.
- Least privilege keeps the device and cloud APIs from doing more than they need.
- Visible vulnerability handling makes it possible for researchers and customers to report issues without guesswork.
I treat security as a product capability because customers eventually judge the whole service by its weakest link. Once that baseline is in place, the data path becomes the next place where IoT projects either stay lean or become unnecessarily expensive.
Design the data path before the dashboard
I have seen too many IoT projects treat the dashboard as the product and the data model as an afterthought. That usually leads to noisy telemetry, expensive storage, and reports that look impressive but answer the wrong questions. I want the data design nailed down early: what is collected, how often, where it is processed, how long it is kept, and who is allowed to see it.
Collect less, but collect better. A sensor that sends one meaningful event every 10 minutes and only transmits on change is often more useful than a device that streams every second. Less raw traffic means lower bandwidth cost, smaller battery drain, and a clearer operational picture. It also reduces the temptation to keep data forever just because storage is cheap.
- Edge filtering strips noise before the cloud pays to store it.
- Timestamp discipline matters because a device clock drifting by minutes can break audits, alarms, and correlation.
- Retention rules should separate raw telemetry, operational logs, and user-facing history.
- Privacy by design is easier when you minimise the data at collection time, not after the fact.
I also like to separate raw events from decision-ready data. Raw telemetry is useful for debugging and model tuning. Aggregated data is what most operators actually need day to day. If you blur those layers, the system becomes harder to secure, harder to query, and much harder to explain to users or auditors. Once the data path is disciplined, you can think about long-term support without building a maintenance trap.
Plan for updates, support, and graceful failure
If a device cannot be patched remotely, I treat it as a short-lived prototype, not a serious product. The same goes for products that can be updated but not rolled back. A bad firmware release is inevitable at scale; the real question is whether you can stop, recover, and keep the fleet useful.
I like to write the support model down as part of the product, not as a separate operations note. That means I want to know the update cadence, the support window, the dependencies on companion apps or gateways, and the exact point at which a device becomes end-of-life. NIST's IoT device guidance is helpful here because it forces you to document assumptions, capabilities, and recovery expectations instead of hoping the field team will improvise later.
- Staged rollout keeps new firmware away from the entire fleet until it has earned trust.
- Rollback paths let you reverse a bad update before it becomes a customer incident.
- Version pinning protects the relationship between device firmware, app versions, and cloud APIs.
- End-of-support dates should be visible to buyers before procurement, not hidden in a footnote.
Graceful failure matters just as much as graceful updates. A device should degrade in a way the user can understand: cached data, reduced functionality, clear alerts, and a recovery path that does not require guesswork. With support planned, the last real test is whether the product survives the building, the network, and the installer.
Test in the real world before you trust the lab
I trust a lab to prove that the electronics work. I trust a pilot to prove that the product works. The difference matters. A device can look perfect on a bench and still fail behind brick walls, inside metal cabinets, in a plant room, or in a crowded building with bad Wi-Fi and weak phone signal. That is not a corner case. For IoT, that is the environment.
My rule is simple: test the failures you expect to be ugly. I want to see how the device behaves after a reboot, a brownout, a signal drop, an app reinstall, and a week of intermittent connectivity. A pilot of 20 to 50 devices in the real environment is often enough to expose installation errors, battery surprises, and recovery bugs that a month of simulation will miss.
- Radio testing should happen where the device will actually live, not just in open space.
- Power testing should include worst-case reconnect behaviour, not only ideal sleep cycles.
- Installer testing should cover mispairing, partial setup, and user confusion.
- Recovery testing should prove that a device can survive reboot, power loss, and network churn.
This is where UK buildings can be especially unforgiving: thick walls, awkward retrofits, plant rooms, and mixed old-and-new infrastructure all punish optimistic assumptions. Once the field data is honest, the final job is to lock the product decisions that keep the first shipment from becoming a long support emergency.
What I lock in before the first shipment
Before I approve a first release, I want six things written down and agreed: the device's job, its offline behaviour, its connectivity assumptions, its update path, its security owner, and its end-of-support date. If any one of those is vague, the product will probably survive the demo and fail the fleet.
- One-sentence promise - what the device guarantees, and what it does not.
- Fallback mode - what happens when the cloud, app, or network is unavailable.
- Security ownership - who handles reports, patches, and key rotation.
- Telemetry contract - exactly what is collected and why.
- Exit path - how the customer resets, transfers, or decommissions the device.
That is the point where IoT design stops being a slide deck and becomes a product that can live in the field. I care less about cleverness at this stage than about the discipline that keeps the device useful, secure, and supportable for as long as you intend to stand behind it.