
Good IoT design is less about adding sensors and more about making the whole system work reliably in the field: device, connectivity, cloud, app, security, updates, and the people who have to support it. The best products are planned around the environment they will live in, not around the chipset that looks most impressive in a lab. In this article I focus on the practical decisions that matter most: architecture, connectivity, security, testing, and the mistakes that quietly drive up cost after launch.
The decisions that matter before the first device ships
- A connected product should be designed as a system, not as a gadget.
- Use-case constraints come first: power, environment, latency, data, and support horizon.
- Connectivity is a trade-off between range, throughput, power use, deployment complexity, and recurring cost.
- Security now has to include unique credentials, secure updates, logging, and a clear vulnerability process.
- The cheapest prototype is often the most expensive launch if failure modes are not tested early.
What robust connected-product design actually covers
When I break a connected product down, I stop thinking in terms of a single device and start thinking in layers. There is the hardware, the firmware, the radio or wired link, the backend, the mobile or web interface, and the operational layer that keeps the whole thing alive after deployment. If any one of those layers is treated as an afterthought, the product will feel fragile in production even if it looks polished on the bench.
The five layers I map first
- Device layer - the sensor, actuator, power system, memory, and processor that sit on the product itself.
- Connectivity layer - the radio, protocol, or cable that moves data in and out.
- Backend layer - the cloud services, APIs, databases, and automation rules.
- Experience layer - dashboards, mobile apps, alerts, installation flows, and customer support tools.
- Lifecycle layer - provisioning, updates, diagnostics, replacement, and end-of-life handling.
That lifecycle layer is where many projects quietly fail. A device is not truly finished when it first connects; it is finished when I can update it safely, identify it uniquely, diagnose it remotely, and retire it without creating a security problem. Once you look at the stack that way, the next question is no longer “what should I build?” It is “what problem am I solving, in what environment, and for how long?” That leads directly into scope and constraints.
Start with the use case and operating constraints
I always start with the real-world job the product has to do, because this is where the strongest design decisions come from. A motion sensor that sends a reading once every few minutes, a smart lock that must react instantly, and an industrial tracker that moves across sites are all “connected” products, but they need very different architecture, power budgets, and failure handling.
The questions I ask first
- Who uses the product, and what does a good outcome look like for them?
- Where will it be installed: home, office, outdoors, plant room, vehicle, or warehouse?
- How often does it need to connect, and what happens when the connection is lost?
- What data is essential, and what data is merely convenient?
- How long must the device remain supportable in the field?
- What regulations, certifications, or customer policies shape the design?
That last question matters more than teams often expect. In consumer products, the baseline is no longer “we will patch security later.” In the UK, the consumer connectable product security regime came into effect on 29 April 2024, so baseline security requirements belong in the plan from the start, not in the launch checklist. For enterprise or industrial deployments, the legal framework may differ, but the operational expectation is similar: the product should be supportable, updateable, and understandable from day one.
Once the use case is clear, the architecture usually becomes easier to choose, because the connectivity decision stops being abstract and starts being practical.
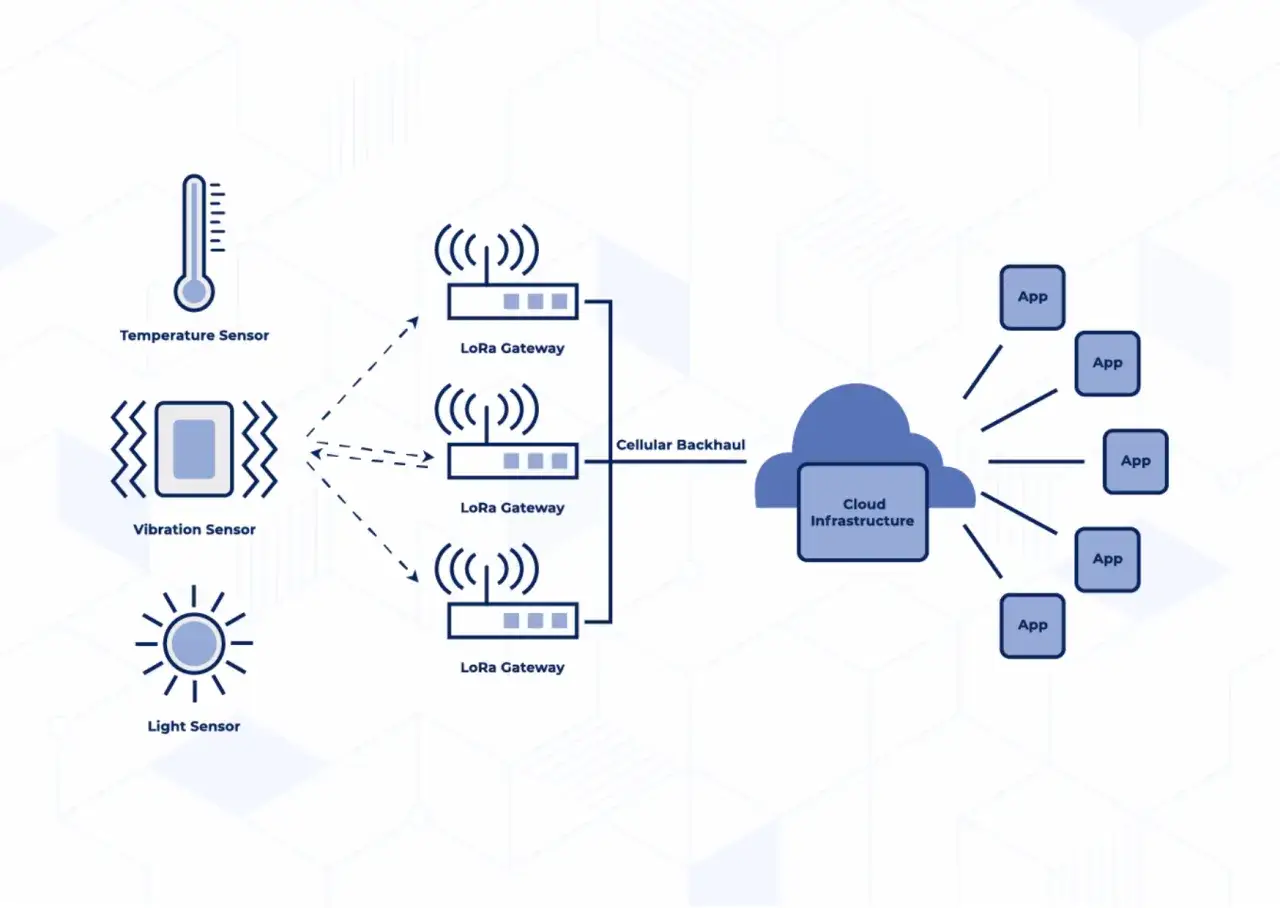
Choose architecture and connectivity that match the field
I usually compare connectivity options on five criteria: range, power use, throughput, installation effort, and recurring cost. The right answer is rarely the fastest protocol or the cheapest chip. It is the option that survives the real environment without constant intervention.
| Option | Best for | Strengths | Trade-offs |
|---|---|---|---|
| Wi-Fi | Mains-powered consumer or office devices | High throughput, familiar infrastructure, straightforward backend integration | Higher power draw, local network dependency, congestion in crowded environments |
| Bluetooth LE | Short-range onboarding, wearables, phone-assisted devices | Very low power, good for battery life, easy pairing flows | Limited range, usually needs a phone or gateway nearby |
| Zigbee or Thread | Homes, lighting, sensor networks, mesh deployments | Efficient for battery devices, mesh coverage can be resilient | More ecosystem complexity, gateway and interoperability planning required |
| LTE-M or NB-IoT | Remote assets, meters, field devices | Wide-area coverage, no local gateway required, managed cellular connectivity | SIM or carrier cost, coverage variability, data limits and network behaviour to plan for |
| Ethernet or PoE | Fixed commercial or industrial installs | Stable link, predictable latency, power and data over one cable | Cabling cost, less placement flexibility |
For many products, a hybrid architecture is the sensible choice. A local protocol can handle the device-to-gateway link, while the gateway uses Ethernet, Wi-Fi, or cellular backhaul to reach the cloud. I also look carefully at edge processing, which simply means some decisions are made on the device or local gateway instead of in the cloud. That matters when latency is critical, when connectivity is unreliable, or when privacy requirements make it unwise to ship raw data everywhere.
In the UK, that local planning is not just theoretical. Indoor coverage, thick walls, basements, plant rooms, and mixed-site deployments often change the answer more than any specification sheet does. If a device must remain safe while offline, I make sure it has store-and-forward behaviour, meaning it can queue data locally and sync later without losing state. If it can repeat messages safely, I prefer idempotent sync, which means sending the same message twice does not create duplicate state. Those details save a lot of support pain later, and they also set up the security work that has to happen next.
Build security and compliance into the blueprint
Security is not a separate workstream in a serious connected product. It is a design constraint. I treat it the same way I treat power or latency: if I ignore it until the end, I pay for it later in cost, delay, or both. The NCSC’s device security principles for manufacturers are a useful mental model here because they turn a vague idea like “secure by design” into practical controls: updates, authentication, data protection, integrity, logging, and device management. There are 13 principles in that framework, and the important point is not the count but the shape of the thinking.
The controls I would not defer
- Unique device identity - every unit should have its own credentials or cryptographic identity, not a shared password.
- Secure updates - over-the-air firmware updates should be signed, validated, and reversible if something goes wrong.
- Encrypted data flows - data should be protected in transit and, where appropriate, at rest.
- Trusted boot chain - secure boot checks that only approved firmware can run.
- Minimal privilege - each service or application should have only the access it needs.
- Logging and alerting - the system should show me when devices misbehave, fail to update, or drift out of policy.
- Clear support policy - customers should know the minimum security update period and how to report issues.
That last point is especially important in the UK. Government guidance now expects manufacturers, importers, and distributors of consumer connectable products to handle three baseline security requirements: no universal default passwords, published security issue reporting, and published minimum update periods. That is a design requirement as much as a compliance requirement, because the product has to be built in a way that makes those obligations realistic to meet.
For consumer IoT, ETSI EN 303 645 remains the cleanest baseline reference I would use for product security thinking, while NIST IR 8259r1, published in April 2026, is useful because it frames the job as both pre-market and post-market work. In plain English: the product must be securable before launch, and it must stay supportable after launch. That becomes obvious the moment you start testing failure modes instead of just checking features.
Prototype for failure, not just for function
Most early prototypes are built to prove that the happy path works. That is useful, but it is not enough. I want a prototype to answer a harder question: what happens when the network drops, the battery is weak, the firmware update fails, or the customer installs the device in a worse environment than the lab?
Read Also: No-Code IoT: Remove Plumbing, Not Responsibility
The failure modes I would simulate
- Wi-Fi or cellular dropouts during normal operation and during update delivery.
- Power loss in the middle of booting, provisioning, or writing data.
- Corrupted firmware images and rollback behaviour after a failed update.
- Sensor drift, noisy readings, and intermittent actuator response.
- Factory variation, which means two units from the same line do not behave identically.
- First-boot provisioning mistakes, such as missing certificates or mismatched identities.
I also test the onboarding path with people who have not seen the product before. That sounds obvious, but it is where good hardware projects often stumble. If setup requires perfect timing, hidden knowledge, or a support call, the customer experience will feel weaker than the engineering team expects. A decent deployment flow should survive retries, partial setup, and a poor mobile signal.
This is also where the distinction between a device and a fleet becomes real. A fleet is just many devices managed together, but that changes everything: configuration, status, diagnostics, and update coordination all need to work at scale. I have seen teams build a polished single-device demo and then discover they have no real fleet tooling, which means every issue becomes a manual intervention. That leads directly to the cost mistakes that catch people later.
The mistakes that make connected products expensive to own
The cheapest bill of materials is not the cheapest product. I have learned to look past the unit cost and ask what it will cost to support, update, monitor, and eventually retire the device. That wider view changes a lot of decisions that seem small during design.
| Mistake | Why it hurts | What I would do instead |
|---|---|---|
| Assuming always-on connectivity | The product fails in basements, rural sites, or crowded buildings | Design for offline storage, retry logic, and graceful degradation |
| No update strategy | Vulnerabilities become permanent, and support becomes manual | Build signed OTA updates, rollback, and version tracking from the start |
| Collecting too much data | Cloud, storage, privacy, and compliance costs rise without clear value | Collect only what the use case needs, then justify every extra field |
| No fleet tooling | Operations teams cannot see device health or act quickly | Plan dashboards, alerts, and remote configuration before launch |
| Ignoring support horizon | Customers outlive the product roadmap | State how long the device will receive security updates and replacement support |
| Over-optimising BOM cost | A cheaper chip can increase cloud, battery, or support costs later | Judge total cost of ownership, not just component price |
BOM means bill of materials, the component cost of one unit. I care about it, but I care just as much about cloud egress, support tickets, repair logistics, and remote diagnostics. A product that sends raw telemetry every few seconds may look simple to ship, yet it can become expensive to operate if that data is not actually needed. Likewise, a device that cannot be updated remotely often forces physical recalls or field visits, which usually cost far more than the saved hardware penny.
The strongest connected products are the ones that look boring after launch because the hard decisions were made early. That is the standard I use when I review a design: can it be installed, supported, updated, and eventually retired without drama?
The design choices that keep a connected product supportable
If I had to compress the whole topic into one principle, it would be this: design for the whole lifecycle, not just the launch. A product that works in the lab but cannot be updated safely, diagnosed remotely, or supported with a clear end-of-life policy is not finished in any meaningful sense.
That is why I always leave room for operational reality in the design brief. I want a clear update cadence, a vulnerability-response path, telemetry that respects privacy, and a decommissioning plan that includes data wipe and device retirement. I also want the support team to have documentation that tells them what healthy looks like, what degraded looks like, and what to do when a device drifts out of that range.
In 2026, the best connected systems are not the cleverest ones. They are the ones that stay trustworthy when connectivity is messy, hardware ages, standards tighten, and customers expect the product to keep working long after the first sale. That is the kind of discipline that turns IoT design into a durable product strategy instead of a one-off engineering exercise.