Industrial IoT becomes useful when it stops being a technology project and starts solving expensive operational problems: unplanned downtime, hidden energy waste, quality drift, slow fault response, and poor visibility across assets. This article breaks down the most practical industrial IoT use cases, shows how the underlying data flow works, and explains where security and resilience can make or break the result. I am focusing on the decisions that matter in real plants, not on demo-room features.
The fast answer for teams that need value, not hype
- Start with one expensive problem, not a broad digital transformation slogan.
- Predictive maintenance, energy monitoring, asset tracking, quality drift, and worker safety are usually the first high-value applications.
- A hybrid edge-and-cloud setup is usually the most practical pattern in brownfield plants.
- ROI depends on alerts flowing into maintenance or operations workflows, not just dashboards.
- Security, identity, patching, and fallback modes need to be designed in from day one.
Where industrial IoT creates value first
In my experience, the best connected-factory projects do not start with sensors. They start with a cost bucket that everybody already understands: downtime, scrap, energy, missed deliveries, or safety incidents. Once that is clear, the technology choices become much easier to judge.
At a practical level, industrial IoT links sensors, PLCs, gateways, historians, and software so that operators can see a condition before it becomes a failure. That sounds obvious, but the real value is not more data. It is shorter reaction time, better scheduling, and fewer surprises on the line.
For UK sites, this matters especially in brownfield environments where new systems have to live alongside older machines, mixed vendors, and uneven network coverage. That is where a focused use case beats a broad platform rollout every time. The next step is deciding which applications deserve priority.
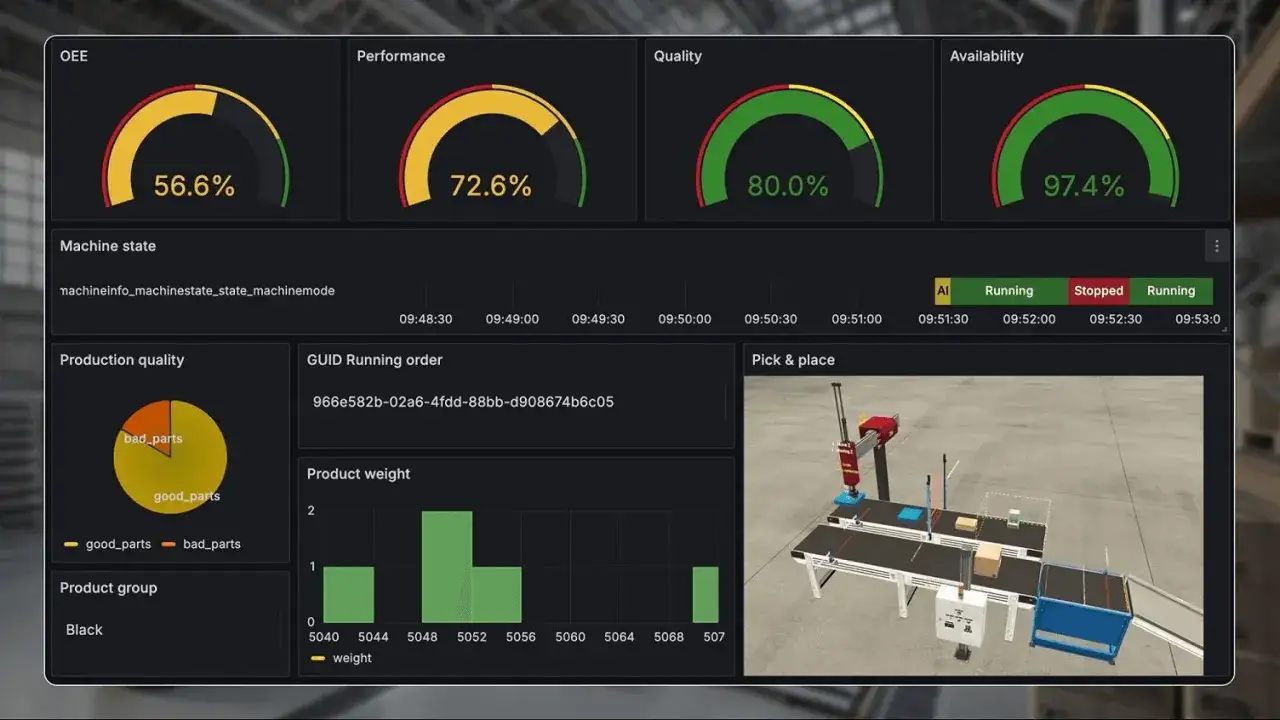
The industrial use cases that usually pay off first
If I had to narrow the field to the applications that most often justify themselves, I would start here. Each one maps to a measurable operational problem rather than a vague promise of digitalisation.
| Use case | Typical signals | Why it pays | Main risk |
|---|---|---|---|
| Predictive maintenance | Vibration, temperature, current draw, oil condition | Reduces unplanned stoppages and emergency call-outs | Instrumenting low-value assets first |
| Condition monitoring | Pressure, flow, noise, heat, run state | Helps teams catch wear before a breakdown spreads | Collecting alerts without a response owner |
| Energy monitoring | Power use, compressed air loss, idle time, peak demand | Lowers utility spend and exposes inefficient processes | Measuring totals without linking them to machines |
| Asset and WIP tracking | RFID, UWB, GPS, barcode events | Reduces search time, loss, and bottlenecks in flow | Tracking too many low-value items |
| Quality monitoring | Vision data, torque, humidity, temperature, process drift | Cuts scrap, rework, and hidden process variation | Finding defects after production is already finished |
| Worker safety | Gas detection, geofencing, wearables, machine proximity | Improves incident response and supports compliance | Turning safety tooling into surveillance |
| Remote operations | Tank level, valve position, pump status, field telemetry | Makes dispersed assets easier to supervise and service | Weak fallback when connectivity drops |
What stands out is that the winners all close a loop. They do not merely report that something happened; they help someone do something about it before cost builds up. That brings us to the technical question behind every good project: how the data gets where it needs to go.
How the data path works from sensor to action
Most industrial deployments have four layers. The device layer captures signals, the edge or gateway layer filters and translates them, the platform layer stores and correlates the data, and the application layer turns it into alerts, work orders, and decisions. I like this model because it keeps the conversation grounded in actual jobs to be done.
| Layer | What it does | Why it matters |
|---|---|---|
| Device layer | Sensors, PLCs, cameras, meters | Captures physical reality at the source |
| Edge or gateway layer | Buffers, translates, filters, applies local rules | Keeps latency low and survives weak connectivity |
| Platform layer | Historian, broker, data lake, analytics | Stores and correlates signals across assets or sites |
| Application layer | CMMS, MES, dashboards, notifications | Turns data into action and accountability |
For connectivity, OPC UA is a strong fit when you need structured, vendor-neutral industrial data. MQTT is useful when you want lightweight publish/subscribe messaging across constrained networks. In practice, most serious systems end up hybrid: critical logic stays close to the machine, while fleet analysis and reporting live higher up the stack.
That architecture choice matters because a system can look elegant on a whiteboard and still fail on a real site. Once the plumbing is clear, the bigger risk shifts to scope, ownership, and process discipline.
Why some projects never reach ROI
Most failures are not technical disasters. They are scope mistakes. The pilot is too broad, the metric is too fuzzy, or the alert has nowhere useful to land.
- Starting with a dashboard instead of a decision.
- Instrumenting the easiest asset instead of the most expensive failure mode.
- Collecting data without assigning ownership for the response.
- Sampling too slowly for the failure pattern you are trying to catch.
- Ignoring how false positives will affect operators after week two.
- Trying to standardise every site before proving value at one site.
My rule of thumb is simple: if the project cannot improve at least one of four metrics - downtime hours, scrap or rework, energy per unit, or response time - it is not yet specific enough. A useful pilot is usually something like one line, one asset class, one owner, and a 30 to 90 day learning window. That is an estimate, not a law, but it is a much better starting point than “connect everything”.
Once the business case is sharper, the next non-negotiable topic is security.
Security and resilience are part of the design
Connected machinery changes the threat model. In other words, once operational data can move more freely, so can mistakes, misconfigurations, and attacks if the network is not designed carefully. I would treat security as part of the use case, not as a later hardening exercise.
In the UK, the NCSC device security principles are a sensible baseline for connected hardware, especially when vendors and integrators are sharing responsibility. The goal is straightforward: strong identities, controlled update paths, sensible defaults, and visible logging.
- Segment OT and IT networks so only the required traffic can pass.
- Use unique device identity and certificates rather than shared credentials.
- Encrypt traffic end to end where it crosses untrusted networks.
- Plan patch windows, rollback steps, and maintenance ownership before deployment.
- Build a safe degraded mode so the plant can keep running if connectivity drops.
- Keep audit logs for changes, alerts, and configuration updates.
Resilience is the part people underestimate. A duplicated sensor is not enough if the workflow collapses when the network is unstable. If the system cannot fail safely, it is not ready for production. That is why rollout planning matters as much as protocol selection.
Where I would start in a UK rollout this year
If I were advising a UK manufacturer, I would choose one site, one problem, and one operational owner who can act on the data. That keeps the project honest. It also makes it easier to measure whether the system is actually changing behaviour.
UK support programmes such as Made Smarter have already reached more than 4,000 manufacturing SMEs, which tells me adoption is no longer the big question. Execution is. The organisations that do well are the ones that keep the first phase narrow and measurable.
- Pick an expensive and visible problem, such as a bottleneck machine, compressed air loss, cold-chain monitoring, or a critical asset in transit.
- Measure the current baseline before installing anything, so the before-and-after picture is credible.
- Instrument only the signals that help explain the failure mode.
- Connect alerts to a maintenance, operations, or quality workflow rather than a standalone screen.
- Review false alarms, missed events, and response time, then refine the thresholds.
- Scale only after the pilot changes a metric that management already cares about.
If I had to prioritise spend, I would usually put the first budget into clean integration and alert design before advanced analytics. Machine learning becomes useful once the data is trustworthy and the workflow is stable. On a brownfield site, that sequencing saves more money than trying to look sophisticated on day one.
The patterns worth copying from the strongest deployments
The projects that tend to last all share the same shape: they are tied to a real operational pain, they keep the architecture simple enough to maintain, and they make sure every signal leads to a decision. That is the practical core of industrial IoT.
If you want the shortest path to value, start with maintenance, energy, tracking, or quality, then harden security and data flow before adding more intelligence. That is how you get a system that survives production pressure instead of a pilot that quietly fades away.