Traffic distribution is one of those infrastructure layers you only notice when it fails. The right load balancing tools keep applications available, spread demand across healthy backends, and stop a single server from becoming the bottleneck. In practice, the best choice depends on whether you need simple request sharing, intelligent routing, cloud-managed failover, or something that fits a bare-metal Kubernetes estate.
The essential questions that decide the right fit
- Load balancing is about resilience and traffic efficiency, not just equal request distribution.
- Software balancers offer flexibility; hardware and appliance platforms still matter in strict, high-throughput environments.
- Cloud-managed services reduce day-to-day operations, but they trade that for provider dependency and different cost dynamics.
- For Kubernetes and bare metal, the real question is whether you need Layer 4 exposure, Layer 7 routing, or both.
- Health checks, session persistence, TLS handling, and observability usually decide success more than raw throughput.
What a load balancer actually does in a live network
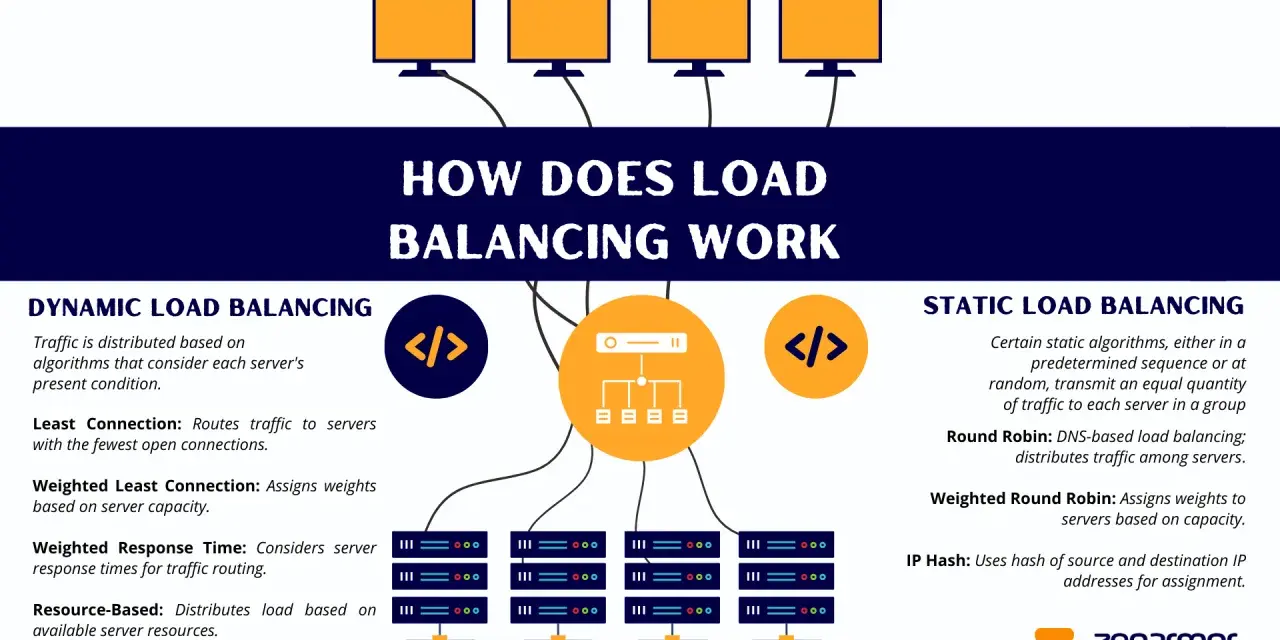
At the simplest level, a load balancer sits between clients and your servers and decides where each request should go. In a production network, though, it does much more than shuffle traffic around. It checks whether backends are healthy, removes bad nodes from rotation, and can terminate TLS so your application servers spend less time on encryption work.
That makes it a traffic director, a resilience layer, and often a policy engine. For HTTP services, a Layer 7 device can inspect paths, headers, cookies, and methods, which is useful when one application needs to serve API calls, static files, and admin traffic differently. Layer 4 tools work lower down the stack and simply move TCP or UDP streams, which keeps them fast and general-purpose.
For UK infrastructure teams, that distinction matters because one environment rarely serves every workload well. A public web app, an internal API, and a legacy TCP service usually need different handling, even if they share the same physical or cloud estate. Once you know which layer you need, the shortlist becomes much shorter.
The main tool categories and where each one fits
When people talk about load balancing, they often mix together very different products. I find it easier to separate them by operating model first, because that tells you far more than a logo or feature sheet ever will.
Software balancers
HAProxy, NGINX, Envoy, and Traefik are the names I see most often when teams want control without hardware lock-in. They are flexible, scriptable, and comfortable in virtual machines, containers, and edge deployments. The trade-off is operational ownership: you patch them, scale them, monitor them, and design the failover.
Appliances and enterprise platforms
F5 BIG-IP, Citrix ADC, Kemp, and similar systems still have a place where traffic volumes are high, change control is strict, or advanced traffic policy is part of the job. The attraction is depth: SSL/TLS offload, persistence, traffic shaping, and support contracts all come together in one platform. The cost is usually complexity and procurement overhead, so I only recommend this route when the organisation is actually ready to operate it well.
Cloud-managed balancers
AWS Elastic Load Balancing, Google Cloud Load Balancing, Azure Load Balancer, and Cloudflare Load Balancing remove a lot of undifferentiated work. They are a strong fit when you want elastic capacity, zone-aware failover, and minimal appliance management. The downside is that your design follows the provider’s model, pricing, and control plane, so portability becomes a real consideration rather than a theoretical one.
Bare-metal and Kubernetes options
MetalLB is the clearest example here. It solves a common problem in bare-metal Kubernetes: exposing services without a cloud controller to assign external addresses. I treat this category as infrastructure glue, not a general-purpose replacement for every balancer you might use in front of a platform.
That technical split matters because the next question is how the balancer actually decides where each request goes.
How balancing decisions are made under the hood
The algorithm matters more than most buying guides admit. I have seen teams choose the right platform and still get poor results because the traffic pattern and the scheduling method were a bad match.
Round robin and weighted round robin
Round robin sends requests to backends in turn. Weighted variants send more traffic to stronger nodes, which is useful when machines are not identical. It is straightforward, predictable, and often good enough for web traffic that does not keep much state on the server.
Least connections and latency-aware steering
Least connections sends new sessions to the server with the fewest active connections. I prefer it when request durations vary a lot, because one slow backend should not keep collecting new work just because it is next in line. Some platforms also steer traffic by latency, which can help when origins behave differently under load or when network paths are uneven.
Persistence and hashing
Session persistence keeps a client on the same backend for a period of time, usually through cookies or source-IP hashing. That helps with shopping carts, older applications, and any system that still keeps state on the server. The downside is that it can hide imbalance and reduce the value of an otherwise clean distribution strategy.
Read Also: Network Virtualization - Avoid Costly Mistakes & Choose Right
Health checks and failover
Good health checks do more than test whether a port is open. They confirm that the application is answering in a way that actually matters, then remove broken nodes before users feel the outage. In 2026, this is still the feature I would refuse to compromise on.
Those mechanics only help if the platform matches your operating model, which is what I look at next.
What I compare before I commit to a platform
When I evaluate a load balancer, I start with operating questions rather than feature counts. A long checklist is less useful than a few blunt filters that reveal whether the tool fits the environment.
| Criterion | What I ask | Why it matters |
|---|---|---|
| Protocol support | Does it handle HTTP(S) only, or also TCP, UDP, gRPC, and passthrough TLS? | Protocol support determines whether the tool can serve web apps, APIs, or non-HTTP services without awkward workarounds. |
| Deployment model | Is it cloud-managed, self-hosted, appliance-based, or Kubernetes-native? | The deployment model decides who owns patching, scaling, and failover. |
| Observability | Can I see health status, logs, metrics, and backend behaviour clearly? | Weak visibility turns routine incidents into guesswork. |
| Automation | Is there a stable API, Terraform support, or a GitOps-friendly config flow? | If changes are manual, configuration drift arrives quickly. |
| Security | Can it terminate TLS, support mTLS where needed, and fit with WAF or DDoS controls? | Security and traffic management are increasingly linked, not separate. |
| Resilience | Does it support multi-zone or multi-node failover, config sync, and graceful health-based removal? | A single proxy with no redundancy is still a single point of failure. |
| Data residency and control | Where is the control plane, and where do logs or telemetry go? | For UK organisations, that matters for governance, procurement, and sometimes regulatory comfort. |
If I am comparing two tools and one gives me good automation but weak visibility, I usually worry about operational pain later. Those criteria become much easier to judge when you compare the common options side by side.
A practical comparison of the main options
I am not interested in ranking every vendor on the market. What matters is whether a tool matches the traffic pattern, team size, and operating model you actually have. The table below is the comparison I find most useful in real projects.
| Option | Best for | Strengths | Trade-offs |
|---|---|---|---|
| HAProxy | High-performance self-managed L4/L7 balancing on VMs or containers | Fast, mature, flexible, and well suited to health-based routing | You own scaling, patching, and operational design |
| NGINX | HTTP-heavy stacks that also need reverse proxying | Versatile, familiar, and easy to integrate into web platforms | Advanced features may push teams toward the commercial edition |
| Envoy | Microservices and service-to-service traffic | Strong observability, dynamic configuration, and modern cloud-native fit | Steeper learning curve and more moving parts |
| F5 BIG-IP | Large enterprise estates, regulated environments, and advanced traffic policy | Deep feature set, support options, and appliance-class reliability | Higher cost and more complex lifecycle management |
| AWS Elastic Load Balancing and similar cloud-managed services | Teams that want managed scale and provider-native integration | Low operational burden, zone awareness, and elastic capacity | Less low-level control and more vendor dependence |
| Cloudflare Load Balancing | Global traffic steering and edge-facing applications | Good for latency-aware failover and reducing strain on origins | Works best as part of a broader edge strategy rather than a pure internal balancer |
| MetalLB | Bare-metal Kubernetes clusters | Clean way to expose services without cloud-native load balancers | Not a full ADC, so it depends on the surrounding network design |
If I wanted something portable and under my own control, I would usually start with HAProxy or NGINX. If I needed to minimise day-to-day work, I would lean cloud-managed. If I were dealing with a large regulated estate or legacy traffic patterns, I would look more seriously at an enterprise platform. The remaining risk is not picking the wrong product, but using the right one badly.
The mistakes that cause false confidence
Most bad outcomes come from assumptions, not from the tool itself. I see the same mistakes repeated often enough that they are worth calling out plainly.
- Using the balancer instead of fixing the application. If the backend is slow, memory-hungry, or leaking connections, more routing logic will not solve the root problem.
- Leaving health checks too shallow. A port being open is not the same as an application being ready to serve real traffic.
- Making sticky sessions the default. Session persistence can help, but it also hides poor distribution and makes failover less clean.
- Ignoring redundancy for the balancer itself. One proxy with no failover plan is still a single point of failure, no matter how elegant the config looks.
- Skipping observability. If you cannot see backend latency, connection counts, and health state, you will diagnose incidents slowly.
- Forgetting TLS lifecycle work. Certificates, renewal automation, and cipher policy all matter once traffic starts crossing real environments.
I also think teams underestimate how often the real problem is a control-plane issue rather than a traffic issue. If config changes are manual, undocumented, or inconsistent between environments, the balancer becomes a source of risk instead of protection. When the architecture is still unclear, I fall back to a simple decision rule.
The decision rule I use when the shortlist is still too long
If speed and low operations matter most, I choose a managed service. If portability, control, and predictable behaviour matter most, I choose software. If compliance, deep policy, or legacy dependencies dominate the brief, I look at an appliance or enterprise platform. If the environment is bare-metal Kubernetes, I treat MetalLB as the missing piece that makes the cluster usable in the first place.
- Pick cloud-managed load balancing when your team wants less maintenance and more elasticity.
- Pick software balancing when you want control, automation, and the freedom to move between environments.
- Pick enterprise hardware or appliance platforms when traffic policy, support, and governance outweigh simplicity.
- Pick Kubernetes or bare-metal add-ons when service exposure is the problem, not application routing.
For UK infrastructure in particular, I would bias toward the simplest design that still gives you failure isolation across zones or sites. The cleanest architecture is the one your team can operate confidently on a busy morning, not the one that only looks impressive on a diagram.