The essentials are visibility, control and recovery
- Start with the systems and data that cannot fail, then map their dependencies.
- Treat identity as the first control point with strong MFA and separate admin access.
- Use segmentation, patch discipline, logging and backups as layered defences.
- Plan for detection, containment and restoration before an incident forces the issue.
- Review the design regularly, because networks drift faster than most policies do.
Start with the business processes that cannot fail
I usually begin with three questions: what cannot be interrupted, what can be degraded, and what can be isolated without hurting the business. That forces the discussion away from products and towards outcomes, which is where it belongs.
The UK's NCSC still frames practical defence around risk management, asset management, identity, architecture, logging and incident handling. That order makes sense, because controls only become useful once you know which systems keep the business alive.
- Customer identity and sign-in systems
- Remote access and administrative access paths
- Finance, order processing and other revenue systems
- Shared file stores, backups and recovery points
- Any operational technology or supplier connection that can stop production
Once those priorities are clear, the next job is to build a map of the network that reflects reality instead of old assumptions. That map is what turns a vague policy into a usable plan.
Map assets and trust zones before adding new tools
If the inventory is wrong, every later decision is wrong too. I want a live picture of endpoints, servers, cloud workloads, SaaS apps, admin accounts, VPNs, DNS paths and every third-party connection that can reach internal resources.
The quickest way to find gaps is to ask what would still be reachable if one employee laptop, one contractor account or one supplier tunnel were compromised. Those answers show your trust zones more clearly than any architecture diagram.
- Public-facing systems and internet-exposed services
- Privileged accounts and shared admin roles
- Remote access paths, including VPN and SSO
- East-west traffic between users, servers and cloud workloads
- Backup repositories and restore permissions
I prefer this step to be current, not perfect. A good-enough map that is updated weekly beats a beautiful diagram that nobody trusts by the end of the month. From there, the next question is which controls deserve priority first.
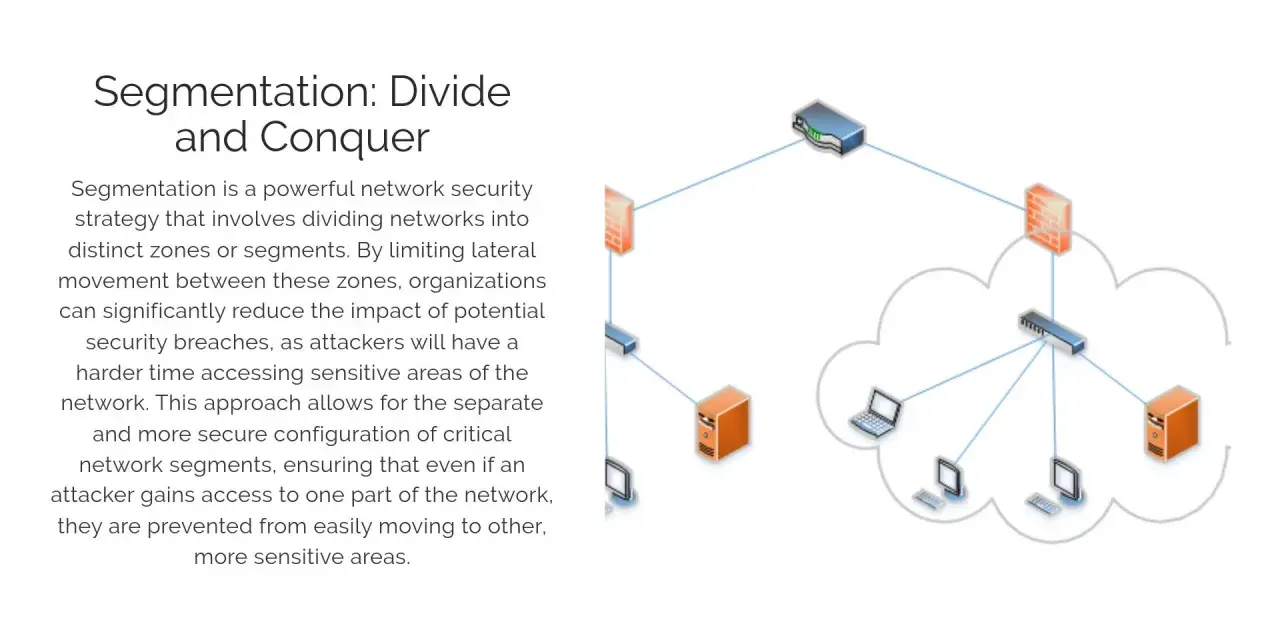
Layer the controls that actually reduce risk
This is where a lot of programmes go wrong. Teams buy a point product for each scare, but the network stays just as easy to move through. I would rather see four controls done consistently than ten tools only half configured.
| Control layer | What it does | Best first move | Common failure mode |
|---|---|---|---|
| Identity and access management | Restricts who can enter and what they can do | Require phishing-resistant MFA for admins and remote access | Shared accounts and standing privilege |
| Segmentation | Limits lateral movement after compromise | Separate users, servers, guest, OT and supplier access | A flat internal network with no real trust boundaries |
| Vulnerability management | Reduces exploitable attack paths | Patch internet-facing and high-value systems on fixed SLAs | Treating patching as ad hoc maintenance |
| Monitoring and logging | Makes compromise visible quickly | Centralise auth, DNS, endpoint, cloud and firewall logs | Collecting logs without alert tuning |
| Backups and recovery | Restores operations after disruption | Keep immutable copies and test restore regularly | Backups that fail under the same domain compromise |
If I had to start with a lean budget, I would spend first on MFA, segmentation, patch discipline and restore-tested backups. That sequence does not eliminate risk, but it shrinks the blast radius of a bad day. From there, the design principle becomes clearer: trust less, verify more, and limit how far an attacker can travel.
Design for zero trust and segmentation, not a flat network
NIST's zero trust guidance is useful because it rejects the old assumption that anything inside the perimeter is automatically safe. I think of zero trust as a habit: verify identity, check device posture, grant the narrowest possible access, and re-check when context changes.
- Give admins separate accounts and, where possible, separate devices.
- Put suppliers into time-bound, task-specific access paths.
- Use microsegmentation to separate user, server, cloud and operational zones.
- Tie access to device health, location and authentication strength.
- Remove standing trust between applications that do not need it.
Microsegmentation matters because it creates small trust zones instead of one large, easy-to-traverse internal network. That takes more design work upfront, but it reduces the amount of infrastructure a thief can explore after one compromise. Once the boundaries are in place, the harder part is proving that you will spot a problem quickly enough to contain it.
Make detection, response and recovery part of the network
I like to define three clocks: how fast you detect, how fast you contain, and how fast you can restore. If those clocks are vague, the strategy is vague.
- Stream logs from identity, endpoints, DNS, firewall, cloud and key business apps into one place.
- Tune alerts for privileged logins, new admin creation, unusual data movement, blocked security tools and changes to backup jobs.
- Write playbooks for ransomware, account takeover, lost laptops and supplier compromise.
- Run tabletop exercises with IT, operations, legal and leadership.
- Test restores from immutable backups at least quarterly and after major changes.
A practical logging target is at least 30 days of hot data and 6 to 12 months of searchable archive, if budget and regulation allow. The exact number matters less than the discipline: if you cannot reconstruct what happened, you cannot contain it with confidence. That is why recovery planning needs to sit beside prevention, not behind it.
What usually breaks the plan in UK organisations
The common failure is not missing technology; it is drift. I see flat networks that were meant to be temporary, VPN exceptions that never expire, admin accounts used for day-to-day work, and incident plans that have never been tested beyond a desk review.
UK teams also tend to underestimate supplier access. A contractor path that was safe last year may now be a live route into business-critical systems, especially when the same trust model has been copied into cloud services and remote support tools.
- Buying tools before fixing identity and inventory
- Leaving third-party access broader than internal access
- Treating patching and backup testing as optional maintenance
- Letting the exception list become the real policy
- Ignoring who owns recovery after hours or during holidays
If your network security strategy cannot survive a stolen laptop, a compromised supplier account and one well-placed phishing email, it is too brittle. I would start by narrowing access, reducing trust and rehearsing the recovery path until the team can do it without debate. That is the difference between a network that looks secure and one that can actually absorb an attack without losing control.