
The essentials that keep device-to-cloud projects from breaking later
- MQTT over TLS is still the most practical default for most device telemetry and command flows.
- A gateway is often the right answer when devices speak Modbus, BACnet, CAN, or another non-HTTP protocol.
- Per-device identity matters more than shared passwords or a single fleet key.
- UK projects need to think about UK GDPR, the DPA 2018, and secure-by-design expectations from the start.
- The real cost drivers are usually message volume, retries, storage, and retention, not the initial SDK.
- Offline behaviour, OTA updates, logging, and topic design should be planned before the first pilot device ships.
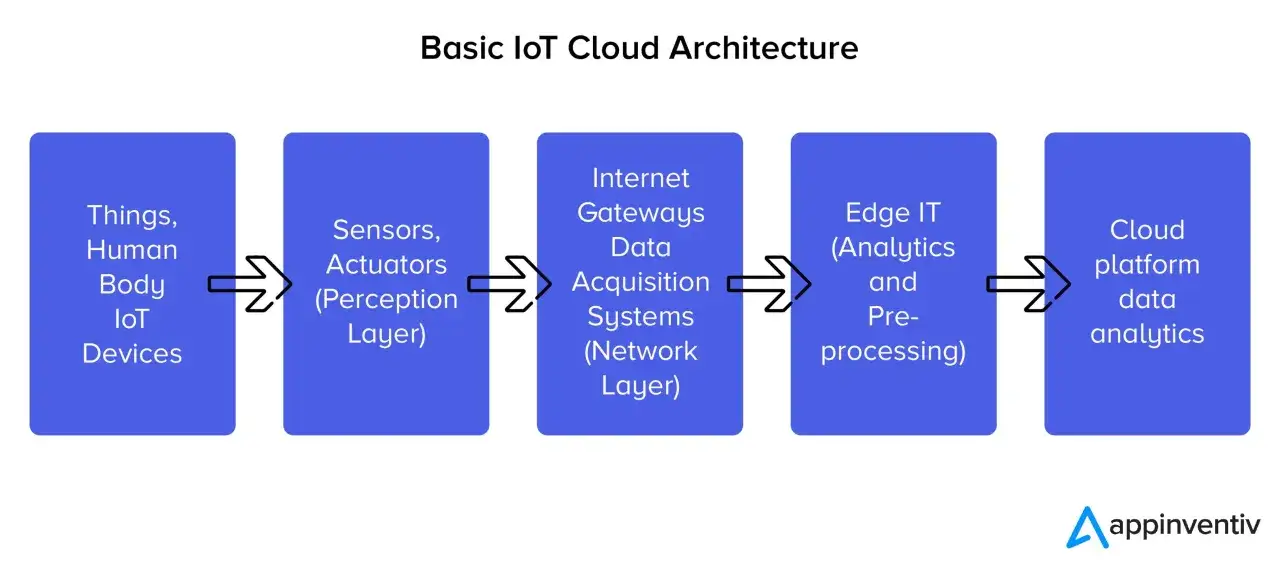
What this connection actually needs to solve
Most teams begin by asking how to “connect a device to the cloud”, but that is only the transport layer of the problem. In practice, iot cloud integration succeeds only when identity, transport, data handling, and operations are designed together.
There are five jobs the system has to do well: collect telemetry, deliver commands, keep device state in sync, update firmware or configuration remotely, and feed analytics or alerts without overwhelming the backend. If any one of those jobs is bolted on later, the whole stack starts to feel fragile.
I also like to separate the obvious data flow from the less obvious operational flow. A temperature reading can travel to a dashboard in milliseconds, but a failed certificate renewal, a missed OTA update, or a bad retry policy can quietly turn a clean pilot into a support headache. That is why the architecture deserves as much attention as the protocol itself.
Once that scope is clear, the next question is how the components should be arranged so they stay maintainable after the pilot phase.
The architecture that scales beyond a pilot
There are three patterns I see again and again. The first is direct device-to-cloud, which works well when the device has IP connectivity, enough memory, and a modern protocol stack. The second is gateway-mediated, which is the safer choice when the device is talking to local industrial equipment or short-range sensors. The third is hybrid, where the edge handles local control and buffering while the cloud handles dashboards, rules, analytics, and long-term storage.
| Layer | What it does | What I watch closely |
|---|---|---|
| Device or sensor | Captures readings and executes local actions | Power use, firmware update path, identity, and reconnect logic |
| Gateway or edge node | Translates legacy protocols and buffers data during outages | Local storage, failover behaviour, and protocol translation quality |
| Cloud ingress | Authenticates traffic and receives telemetry or commands | Transport security, topic or endpoint design, and throttling limits |
| State layer | Maintains desired vs reported state through a shadow or twin model | Conflict handling, versioning, and stale data management |
| Data and operations | Stores events, drives alerts, and supports dashboards or automation | Retention, schema drift, alert quality, and access control |
That state layer deserves a plain explanation. A device shadow or twin is a cloud-side representation of a device’s current and desired state, which makes it much easier to handle intermittent connectivity. If a gateway goes offline for an hour, the cloud can still remember the last known state and reconcile it when the link returns.
I usually recommend a gateway whenever the field equipment is old, proprietary, or noisy on the network. It adds one more component, but it also prevents the cloud from being forced to understand every oddity of the local environment. Once the shape of the system is clear, the next decision is the protocol that carries the data.
Choosing the right protocol and transport
Protocol choice is where many teams overthink the wrong thing and underthink the important thing. The best choice is not the one with the most features; it is the one that fits the device, the network, and the operational model you actually need.
| Protocol | Best fit | Main advantage | Main trade-off |
|---|---|---|---|
| MQTT | Telemetry, command and control, low-bandwidth links | Lightweight publish/subscribe model with small overhead | Needs disciplined topic design and broker governance |
| HTTPS | Simple uploads, admin APIs, occasional device calls | Easy to understand and friendly to existing web tooling | Heavier than MQTT and less elegant for push-style messaging |
| CoAP | Constrained devices and lossy low-power networks | Very small footprint for resource-limited hardware | Cloud support is less universal, so proxies are often needed |
| OPC UA | Industrial machines and semantic machine data | Rich industrial model with strong interoperability | Usually needs a gateway or translation layer to reach the cloud cleanly |
For most deployments, MQTT is the default answer because it balances simplicity and efficiency. MQTT 5 adds better session handling, richer metadata, and request/response patterns, which makes it more practical than people expect for real-world command flows. MQTT over WebSocket on port 443 can also be useful when a device or gateway sits behind restrictive enterprise firewalls.
HTTPS still has a place. I use it when the device sends infrequent updates, when the team wants very conventional API handling, or when browser-adjacent tooling is part of the workflow. CoAP is excellent for constrained environments, but I only choose it when the device profile genuinely needs that small footprint. OPC UA is the right industrial choice when semantics matter more than raw simplicity, especially upstream of a gateway.
Once the transport is chosen, the next question is how to make it secure without turning the fleet into a certificate graveyard.
Security and compliance need to be designed in early
Transport encryption is the baseline, not the achievement. I treat TLS 1.2 or better as non-negotiable, and I strongly prefer per-device credentials over shared secrets. Managed IoT platforms commonly require encrypted transport anyway, and that is the correct default for anything that leaves the edge.
Identity is the real centre of gravity. Each device should have its own certificate or equivalent identity, its own policy scope, and a clear revocation path. If one unit is compromised, I want to disable that unit without interrupting the rest of the fleet. That sounds obvious until a team realises it built the whole rollout on one shared bootstrap token.
On constrained hardware, cryptography choices matter. ECC-based certificate handling can cut compute, memory, and bandwidth usage significantly on smaller devices, so I do not dismiss it as an academic preference. It can be the difference between a secure device and one that silently runs out of headroom.
- Provision devices individually rather than copying one credential across the fleet.
- Rotate certificates and keys on a documented schedule, not only after an incident.
- Separate telemetry from control so a noisy sensor stream does not inherit admin privileges.
- Encrypt data at rest in the cloud, not just in transit.
- Log authentication and provisioning events so you can investigate failures later.
- Plan OTA updates as part of the security model, not as a nice-to-have.
For the UK, I would add one more layer of discipline. If your telemetry touches a person, a household, a vehicle, or a workplace pattern, UK GDPR and the Data Protection Act 2018 are relevant, and the ICO’s IoT guidance is worth following closely. I also keep the NCSC’s secure-by-design mindset in view, because connected-device risk rarely stays local to the device itself.
Security is not separate from integration work; it is what determines whether the integration is viable at all. With that in place, the implementation sequence becomes much easier to control.
The implementation sequence I trust
When I build this kind of system, I start small but I do not start vaguely. The sequence matters, because each step reduces the chances of having to redesign the fleet later.
- Define one use case first. Pick a single operational outcome, such as remote monitoring, alerting, or state sync.
- Write the data contract. Decide what each payload contains, how timestamps work, and how you will version changes.
- Choose the topology. Direct, gateway-mediated, or hybrid should be a deliberate choice, not an accident of hardware history.
- Set the identity model. Decide how devices are born, authenticated, rotated, and retired.
- Design offline behaviour. Buffer locally, define retry rules, and decide how duplicates will be handled.
- Build cloud routing. Separate ingestion, rules, storage, and alerting so one failure does not collapse everything else.
- Test failure modes early. Pull the network, expire credentials, replay messages, and see what actually breaks.
My own rule is simple: if the pilot cannot survive intermittent connectivity and credential churn, it is not ready for scale. I care less about the demo dashboard and more about whether the device recovers cleanly after the things that always happen in the field.
It also helps to measure the right things. I watch reconnect time, duplicate message handling, provisioning failures, firmware update success rates, queue depth on the edge, and end-to-end latency under load. Those metrics tell me far more than raw device count ever will.
Once the implementation is mapped out, the last thing to do is avoid the mistakes that sink otherwise solid projects.
Common failure points that break otherwise good projects
The biggest mistakes are usually boring, which is why they keep happening. They are not exotic cryptography failures or futuristic cloud bugs. They are design choices that looked harmless during the pilot.
- Using shared credentials for convenience and then having no clean way to isolate one device later.
- Overloading the topic hierarchy until nobody can reason about permissions or routing.
- Sending every raw reading upstream when edge filtering would cut noise and cost.
- Ignoring offline buffering and discovering that packet loss becomes data loss.
- Mixing telemetry and commands in the same access policy without clear boundaries.
- Skipping observability and then having no clue whether a problem sits in the device, network, or cloud.
- Treating firmware updates as optional and letting vulnerability management drift into chaos.
The expensive part is rarely the broker or the SDK. It is usually bad data modelling, uncontrolled traffic growth, or a fleet that cannot be maintained once it leaves the lab. I would rather have a modest design that I can explain in one minute than a clever one that needs a whiteboard every time someone asks how it works.
Another trap is assuming the cloud will magically compensate for weak edge design. It will not. If the device cannot validate its identity, queue data locally, and recover predictably after a power cut, the cloud simply receives the mess faster.
What a resilient IoT stack looks like when it is ready for production
The systems that last are the ones that stay simple in the right places and strict in the right places. They use one clear transport, one identity per device, one predictable path for telemetry, and one deliberate path for commands or updates. They also keep edge logic where it belongs, instead of forcing the cloud to solve local network problems.
If I were starting fresh, I would optimise for three things first: trustworthy identity, clean state handling, and recoverable failure. Everything else, from dashboards to analytics to automation, becomes much easier once those three are stable. That is the real shape of a good connected-device programme, and it is the difference between a working pilot and a fleet you can actually operate.
For a UK deployment, I would add one final habit: review privacy and security together before launch, not after the first public rollout. That saves more time, money, and reputational damage than most teams expect.