Reliable connectivity is rarely about one device; it depends on a chain of switches, firewalls, wireless access points, links, and recovery routines that all have to work together. In this article I break down what this kind of support actually covers, where UK businesses usually feel the pain, and how to judge whether the network is being maintained properly. I also compare in-house, managed, and hybrid models so you can make a realistic decision instead of buying reassurance on paper.
What you need to know before you trust a network with the business
- Support is not just fault fixing; it includes monitoring, patching, configuration control, backups, and incident handling.
- The most expensive failures are usually the quiet ones: stale firmware, weak segmentation, poor logging, and untested restores.
- UK organisations benefit from aligning network work with Cyber Essentials-style controls, especially firewalls and security update management.
- A managed service helps most when you need coverage beyond office hours, while in-house teams are strongest when the environment is complex and tightly integrated.
- Good support is measurable. If nobody can show alerts, SLAs, change records, and restore tests, the network is being hoped over rather than managed.
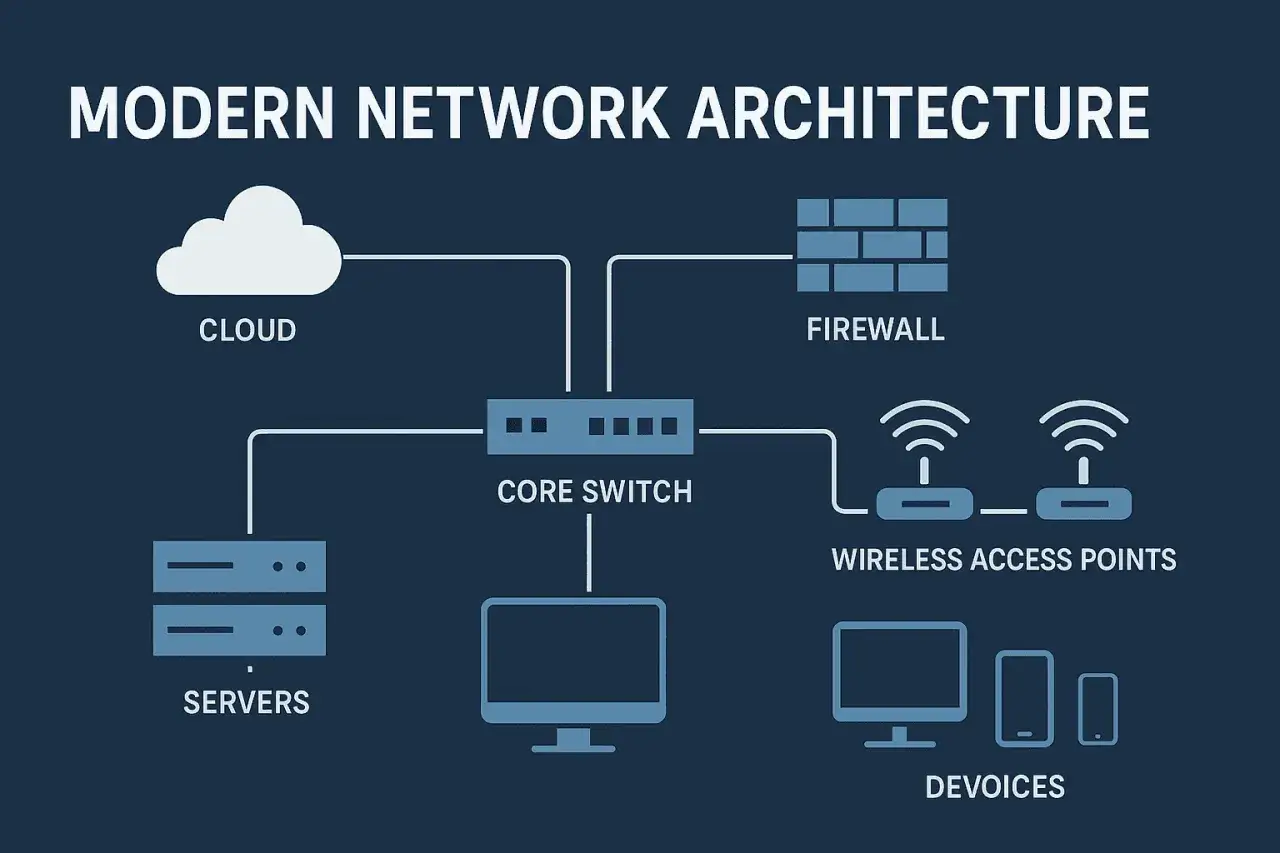
What network infrastructure support actually covers
When I talk about this support, I mean the work that keeps the whole connectivity stack usable, secure, and recoverable. That includes the physical side, such as cabling, switches, routers, and access points, but it also reaches into logical services like IP addressing, DNS, DHCP, VPNs, segmentation, wireless policy, and monitoring.
The important distinction is this: support is not the same as occasional repair. It is the ongoing practice of checking performance, watching for failure signals, applying updates, documenting changes, and resolving incidents before users notice them. The UK standards framework for network support reflects that reality by focusing on monitoring, incident resolution, upgrades, reporting, and fault correction.
In practice, I would split the work into five layers: connectivity, security, availability, recoverability, and change control. A network can feel fine in daily use while still being one firmware bug, one failed backup, or one misconfigured firewall rule away from a serious outage. That is why good support looks boring most of the time and decisive when something breaks.
Why it matters more in the UK than many teams admit
UK businesses often run a mix of office connectivity, hybrid work access, cloud applications, and legacy on-premises systems, and that combination makes weak networking visible very quickly. If the Wi-Fi is unstable, staff cannot get into line-of-business apps. If the VPN is brittle, remote work becomes a support queue. If the firewall is mismanaged, the business can end up exposed or, just as badly, over-restricted.
Security expectations matter as much as uptime. NCSC guidance and the Cyber Essentials model both point to a simple truth: firewalls, secure configuration, security update management, access control, and malware protection are basic controls, not advanced extras. In other words, the network is now part of the security perimeter whether you like that phrase or not.
There is also a business continuity angle that is easy to underestimate. A payroll interruption, a stuck payment terminal, a failed VoIP system, or a cloud outage that cannot be routed around can cost more than the hardware itself. In my experience, the real risk is rarely one dramatic failure; it is a cascade of smaller ones that nobody has tested for.
The daily work that prevents outages and security drift
Stable networks are built on routine. The best teams I have seen do the unglamorous tasks consistently: they watch alerts, review logs, patch systems, validate backups, and track configuration changes instead of assuming the environment will stay healthy on its own.
Monitoring and alerting
Monitoring should tell you when links degrade, switches drop, a wireless controller starts behaving oddly, or latency climbs enough to affect users. A good alert is specific enough to act on, not just noisy enough to ignore. I prefer thresholds that track both symptoms and trends, because a slow rise in packet loss is usually more useful than waiting for a complete failure.
Patching and configuration control
Firmware and software updates are not optional maintenance. They close known weaknesses, improve stability, and keep vendor support available. The same logic applies to configuration drift: if the firewall, router, or access point settings keep changing without a clear change record, troubleshooting becomes guesswork. I want every meaningful network change tied to a ticket, a reason, and a rollback path.
Backups and restore testing
Backups only matter if restoration works under pressure. NCSC ransomware guidance is clear on the practical points: keep backup systems isolated where possible, protect them with timely updates, make them resilient to destructive action, and test restoration from earlier copies. I would add one simple rule of my own: if you have never restored the data, you do not yet know your recovery time.
Read Also: Network Management Essentials: Master Stability & Avoid Outages
Incident handling and root cause analysis
When something does fail, the first job is to restore service, but the second job is just as important: determine why it failed. Root cause analysis means tracing the issue back to the real trigger, not stopping at the symptom. A reboot may hide the problem for a day; it does not explain whether the issue came from congestion, hardware failure, a bad update, a routing loop, or an access policy mistake.
| Support area | What good looks like | What usually goes wrong |
|---|---|---|
| Monitoring | Alerts are actionable, acknowledged quickly, and tied to clear escalation paths. | Too many noisy alerts, no ownership, and no after-hours response. |
| Patching | Updates follow a regular cadence and emergency fixes can be applied fast. | Firmware is left untouched for months because "nothing seems broken". |
| Backups | Copies are isolated, retention is defined, and restores are tested on schedule. | Backups exist, but nobody knows whether they are recoverable. |
| Documentation | Topology, IP ranges, access lists, and vendor contacts are current. | Knowledge sits in one engineer's head and disappears when they are absent. |
| Incident response | Failures are logged, diagnosed, repaired, and reviewed for patterns. | Teams keep fixing the same fault without removing the cause. |
Once those routines are in place, the next question is ownership: who watches, who acts, and who is allowed to change the environment without creating a second problem while solving the first.
In-house, managed, or hybrid support
This is where many teams make a decision too quickly. The right model depends on complexity, business hours, regulatory pressure, and how much specialist depth you actually need. I usually think about it as control versus coverage: the more control you keep internally, the more operational effort your team must absorb; the more you outsource, the more you need a provider that can prove its process quality.
| Model | Best fit | Main strength | Main trade-off |
|---|---|---|---|
| In-house | Complex environments, strict internal governance, or highly integrated operational technology. | Deep context and faster decisions on business-specific changes. | Coverage can thin out quickly outside normal hours. |
| Managed service | SMEs and multi-site organisations that need reliable coverage without building a large team. | Broader expertise and easier access to monitoring, escalation, and after-hours response. | Less day-to-day control unless governance is written into the contract. |
| Hybrid | Businesses that want internal ownership of architecture but external help for monitoring or escalation. | Balanced control and resilience, especially when the team is small. | Requires clear boundaries so tasks do not get duplicated or dropped. |
How I judge whether support is actually good
Good network support is measurable. If a provider or internal team cannot show evidence, I treat the claims as unfinished. I want to see what is being monitored, how issues are escalated, how fast critical faults are handled, and whether the team can prove that backups and failover have been tested rather than assumed.
Here is the checklist I use when I am assessing maturity:
- Monitoring coverage - all important links, devices, and services should be visible, not just the obvious ones.
- Defined SLAs - response and restoration targets should be written, not implied.
- Change records - every material change should have a ticket, an owner, and a rollback plan.
- Asset inventory - hardware, firmware, support status, and ownership should be current.
- Backup evidence - restores should be tested, not merely reported as successful.
- Incident reviews - repeated faults should produce corrective action, not just another closure note.
I also look for cadence. Daily health checks, weekly trend reviews, monthly patch windows, quarterly restore tests, and an annual architecture review are not overkill for a business that depends on its network. They are the minimum rhythm that keeps drift from becoming surprise, and without that rhythm the same avoidable faults tend to return.
Where network support efforts usually fail
The failures are predictable, which is why they are frustrating. One of the most common is poor visibility: the team thinks the network is fine because nobody has complained yet, even though the logs already show warning signs. Another is stale hardware and firmware, especially on switches, wireless kit, and edge security devices that were installed once and then forgotten.
I also see organisations under-invest in segmentation. A flat network makes life easy at the start and difficult later, because problems and threats spread more freely. Segmentation is simply the practice of separating parts of the network so that one issue does not automatically become a whole-business issue. It is not a cure-all, but it is one of the most effective ways to limit blast radius.
Other recurring mistakes are more operational than technical: no named owner for critical devices, no spare capacity on important links, no documented vendor support dates, and no rehearsal for recovery. The pattern is usually the same. The business buys connectivity, but it never really buys operating discipline. That gap is where outages grow.
The first fixes I would make on a fragile network
If I walked into a network that felt shaky, I would start with three moves. First, I would map the actual environment: devices, links, admin access, cloud dependencies, and anything that would stop work if it failed. Second, I would tighten monitoring around the most business-critical components so problems are visible early. Third, I would verify backups and run at least one restore test that reflects a real incident scenario.
After that, I would clean up the basics: remove unused access paths, document the change process, separate guest and internal traffic, and make sure the edge firewall and remote access points are patched. None of those steps is glamorous, and that is exactly why they matter. They reduce the chance that a small fault turns into a morning of avoidable chaos.
For most organisations, the long-term win is not a perfect network. It is a network that is observed, maintained, and understood well enough to recover fast when something goes wrong. That is the real value of disciplined network support, and it is the difference between a resilient business and one that only looks stable when nothing is testing it.