
What matters most before you choose a network management platform
- It is more than monitoring: it combines discovery, alerting, configuration, and control in one operational layer.
- Modern systems mix SNMP, telemetry, logs, and APIs so teams can see both health and behaviour.
- The best fit depends on scale, multivendor support, automation, and how much cloud or remote work sits in the network.
- Good tooling reduces outage time, but it only works if naming, baselines, and ownership are kept clean.
- In 2026, the strongest platforms are the ones that help teams act, not just observe.
What a network management system actually does
When I look at network operations, I treat the management system as the layer that turns a pile of devices into something a team can actually run. It discovers assets, watches behaviour, raises alerts, and gives administrators a way to change settings before small problems become outages. In a modern estate, that includes on-prem switches and routers, Wi-Fi, firewalls, SD-WAN, cloud connections, and branch sites spread across the UK.
That is why the practical answer matters: the real job is not to admire dashboards, but to keep the network visible, controllable, and predictable. Once you see it that way, the next question is how it sits inside the wider infrastructure.
| Function | What it covers | Why it matters |
|---|---|---|
| Discovery | Finds devices, interfaces, links, and services | Stops teams from managing blind spots |
| Fault handling | Detects outages, errors, and threshold breaches | Shortens the time between failure and response |
| Performance tracking | Measures latency, bandwidth, utilisation, and packet loss | Shows whether the network is merely up or actually usable |
| Configuration control | Tracks settings, backups, and changes | Makes rollback and audit work far easier |
| Reporting | Builds historical views and service trends | Supports planning, compliance, and capacity decisions |
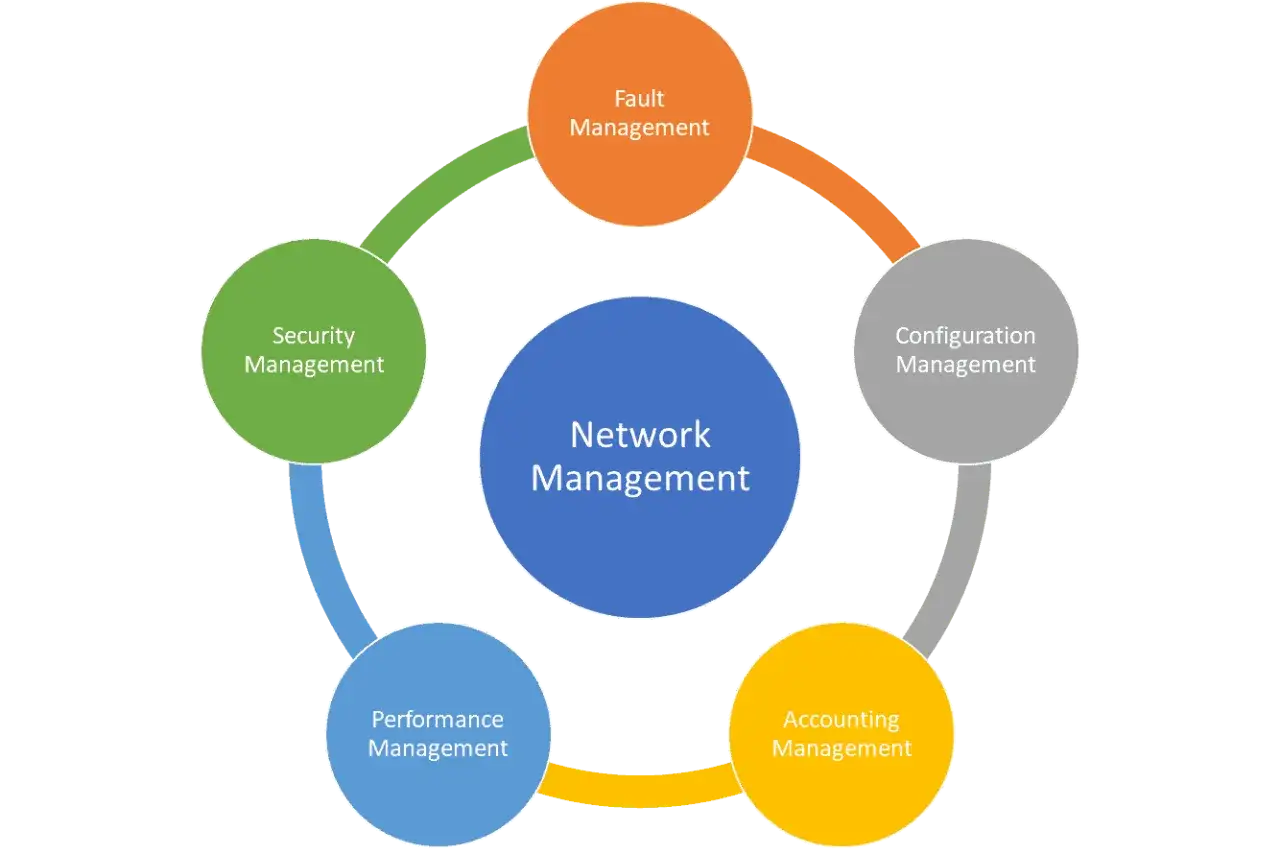
In older language, this sits close to the FCAPS model: fault, configuration, accounting, performance, and security. I still find that framework useful because it reminds teams that a network is not managed by alerts alone; it is managed by a mix of visibility, discipline, and repeatable control. That becomes clearer once you map the system onto the infrastructure it is supposed to manage.
How it fits into modern network infrastructure
A network management system is not the network itself. It is the control layer around it. That distinction matters, because a switch or firewall can forward traffic perfectly well without telling you whether users are struggling, routes have shifted, or a configuration drift has started to spread. The management system watches that behaviour from the outside, then translates it into something operationally useful.
In practice, I think of it as following the shape of the network rather than sitting above it in some abstract way. It has to understand the devices, the links between them, and the services riding on top.
| Part of the network | What the system watches | Why it matters |
|---|---|---|
| Routers and switches | Interface status, routing changes, error rates, utilisation | They carry the core traffic path |
| Wi-Fi and access points | Signal quality, client counts, channel use, roaming behaviour | They shape the user experience at the edge |
| Firewalls and security appliances | Policy hits, denied traffic, session health, configuration changes | They protect segmentation and access control |
| SD-WAN and cloud links | Tunnel health, latency, path selection, failover events | They keep distributed sites and cloud apps reachable |
| Servers and application agents | CPU, memory, service status, dependency failures | They reveal whether the network or the workload is at fault |
This is especially relevant for UK organisations with hybrid estates, remote workers, and branch offices that depend on a mix of private circuits and internet-based links. If the management layer does its job well, a team can see when the problem sits in the LAN, the WAN, the Wi-Fi, the cloud path, or the endpoint. That is the difference between a vague complaint and a useful diagnosis, which brings us to the functions that matter day to day.
The functions that matter most in daily operations
In real operations, I care less about feature lists and more about whether the system helps people answer three questions quickly: what changed, what is failing, and what will fail next if nothing moves. The strongest platforms do that by combining several jobs rather than pretending one dashboard is enough.
- Discovery and topology mapping - The system builds a live picture of devices and links, which is essential when networks change often or span multiple sites.
- Fault management - It detects outages, interface flaps, unreachable devices, and threshold breaches, then turns them into alerts with enough context to act.
- Performance management - It tracks latency, jitter, bandwidth, CPU, memory, and packet loss so teams can spot degradation before users feel it.
- Configuration management - It keeps track of device settings, backups, and change history, which reduces the risk of bad deployments and makes rollback practical.
- Security visibility - It helps surface unknown devices, policy drift, and suspicious changes, even if it is not a full security platform on its own.
- Reporting and capacity planning - It converts raw data into trends, so teams can justify upgrades instead of guessing when a circuit or device is nearing its limit.
The older term for this kind of operational coverage is still useful because it keeps expectations honest: a network management system is meant to reduce uncertainty. It should not merely tell you that a device exists; it should help you understand whether that device is healthy, whether it is behaving as designed, and whether its state has changed in a way that matters. Those jobs depend heavily on how the data is collected, and that is where many buyers underestimate the complexity.
How it collects data and turns it into action
A management platform is only as good as the signals it receives. In 2026, the practical standard is a mix of legacy compatibility and newer, richer data sources. I still see SNMP in many estates because it is widely supported and gets broad coverage, but streaming telemetry and API-driven integration are increasingly important where scale, freshness, and automation matter.
| Method | Strength | Limitation | Best use |
|---|---|---|---|
| SNMP | Broad device support and simple polling | Less detailed and less real-time than newer methods | Mixed multivendor networks and older hardware |
| Streaming telemetry | Fast, high-resolution data with better scale | Needs newer equipment and more design work | Large or time-sensitive networks |
| Syslog and events | Explains what happened at the device level | Does not provide continuous state on its own | Troubleshooting and event correlation |
| APIs | Useful for orchestration and automation | Depends on vendor support and consistent data models | Repeatable change workflows and integration |
What matters is not just collection, but interpretation. Good systems build baselines, compare current behaviour against normal patterns, and correlate events so the alarm volume stays manageable. Without that, teams end up with noise instead of insight. I have seen more projects fail from alert fatigue than from missing raw data. That is also why this category is often confused with monitoring or observability, even though the overlap is only partial.
Why it is not the same as monitoring or observability
People often use these terms interchangeably, but I would separate them. Monitoring asks whether the network is up, slow, or broken. Observability asks why the behaviour is changing by combining richer context from logs, metrics, traces, and related systems. A network management system sits in the middle: it focuses on operational control, device health, and the ability to manage the network rather than simply watch it.
| Capability | Main question | Typical output | What it is best at |
|---|---|---|---|
| Monitoring | Is it working right now? | Alerts, status checks, uptime views | Fast detection of visible issues |
| Network management system | What is connected, what changed, and how do I control it? | Discovery, topology, config, alerts, reports | Day-to-day network operations |
| Observability | Why is the behaviour changing? | Correlated telemetry, logs, metrics, and traces | Deeper diagnosis and root-cause analysis |
The overlap is real, but the centre of gravity is different. Monitoring is narrower. Observability is broader. A network management system is the operational layer that lets teams discover, supervise, and adjust the infrastructure itself. Once that distinction is clear, choosing the right platform becomes a more practical exercise and a less ideological one.
What to look for when choosing a platform
When I evaluate these tools, I start with workflow, not branding. A platform can look impressive in a demo and still fail in daily use if it cannot map the real estate, suppress noise, or fit the way the team works. For a UK business, that often means checking whether the platform handles hybrid office networks, remote access, cloud connectivity, and a multivendor estate without making the admin team fight the tool every day.
- Accurate discovery - It should find devices and links without requiring constant manual cleanup.
- Multivendor support - If your environment spans several manufacturers, weak interoperability becomes expensive very quickly.
- Useful alerting - Good alerting is precise, actionable, and tied to service impact, not just raw thresholds.
- Automation and APIs - These matter when you want repeatable change, not just better screenshots.
- Role-based access and audit trails - They are essential when different teams need different levels of control.
- Reporting and retention - Historical data is what turns a technical issue into a capacity or compliance decision.
- Deployment model - Cloud-managed, on-prem, and hybrid options each create different cost and maintenance trade-offs.
On cost, I would be realistic rather than optimistic. Some tools are open source and reduce licensing spend, but they shift effort into engineering time, support, and upkeep. Commercial platforms usually charge by device, node, feature tier, or subscription, which can be easier to justify if the organisation wants faster rollout and vendor support. The cheapest option is rarely the cheapest after administration is counted properly. Even then, a strong platform can still underperform if the operational habits around it are weak.
Where projects go wrong and what the system cannot fix
The most common mistake is assuming the tool will solve a process problem. It will not. If your device names are inconsistent, your IP plan is messy, or nobody owns threshold tuning, the dashboard will simply expose the chaos more clearly. That is useful, but it is not a cure.
- Alert fatigue - Teams turn off notifications because everything looks urgent.
- Poor baselines - A threshold without a normal-state model creates false positives or missed issues.
- Too much scope too soon - Buying every module at once usually slows adoption.
- Weak ownership - If nobody is responsible for tuning, reporting, and review, the system decays fast.
- Ignoring change management - The best visibility is wasted if changes are made without traceability.
- Assuming automation is the first step - Automation works best after the data model and alert logic are already stable.
There are also hard limits. A network management system cannot fix bad cabling, an unstable ISP, a flawed architecture, or a security policy that was never designed cleanly in the first place. What it can do is shorten diagnosis, reduce blind spots, and make the cost of complexity visible before it becomes a business problem. That is the real value, and it is the reason the category still matters.
The practical takeaway for network teams in 2026
If I had to compress the whole topic into one sentence, I would say this: a network management system gives you the control surface that turns infrastructure into something operable. It connects discovery, health checks, configuration, reporting, and response so teams can keep modern networks stable across offices, cloud services, and remote users.
For most organisations, the best starting point is not the biggest platform, but the one that gives clean discovery, usable alerts, and enough visibility to understand service impact quickly. Build the system around the parts of the network that matter most, keep the data clean, and add automation only after the underlying model is trustworthy. That is how the tool starts earning its place instead of becoming another dashboard nobody opens.