
What matters most when the network has to stay visible and controllable
- It usually combines monitoring, configuration control, inventory, automation, and reporting in one operational layer.
- The best tools reduce alert noise, show topology clearly, and make change history easy to trust.
- For UK organisations, cloud residency, auditability, and hybrid support often matter as much as raw feature depth.
- Open-source, SaaS, and on-premise options solve different problems; none is universally best.
- Automation helps only when discovery, naming, and rollback are already disciplined.
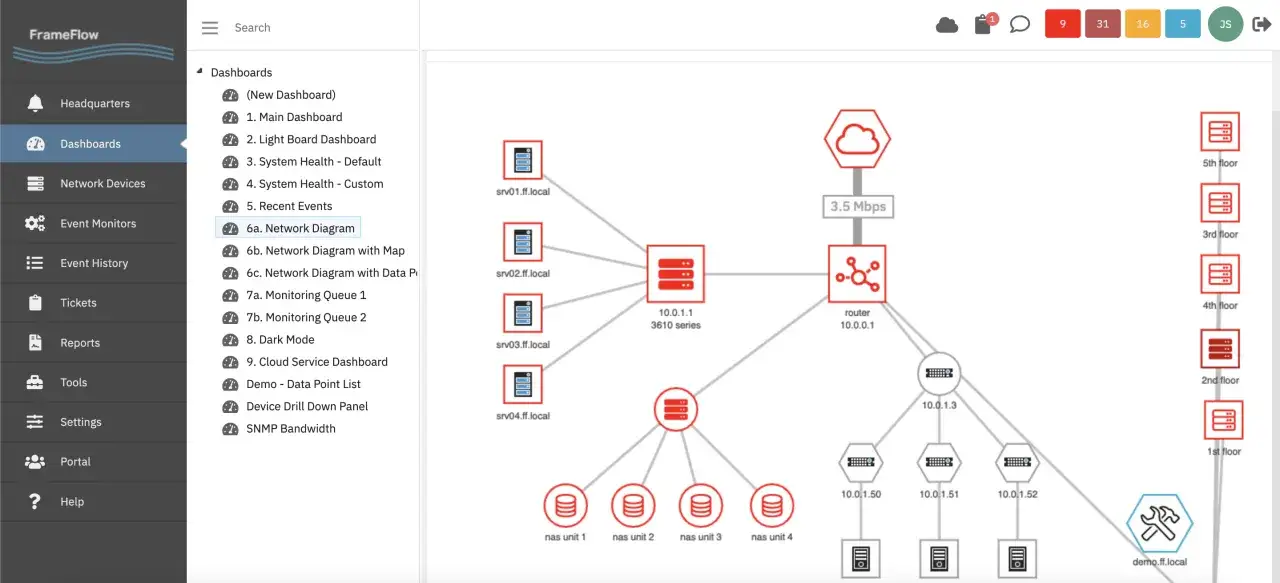
What this software actually covers
At its best, this software sits between the physical network and the people who have to run it. It does not replace switches, routers, firewalls, or access points; it makes them manageable by turning hardware state into something a team can monitor, change, audit, and automate.
In practice, that usually means a mix of functions rather than one tidy feature set. One platform may be strongest at live telemetry, another at config backups, another at IP address management, and another at policy-driven automation. The job is to tie those pieces together well enough that the network stops feeling like a collection of isolated devices.
| Layer | What it does | Why it matters |
|---|---|---|
| Monitoring and observability | Collects metrics, logs, flows, and device health signals | Shows whether the network is healthy before users complain |
| Configuration control | Stores device configs, tracks diffs, and pushes approved changes | Reduces drift and makes rollback possible |
| Inventory and IP planning | Maps devices, ports, addresses, circuits, and dependencies | Prevents the classic problem of not knowing what is actually deployed |
| Automation and orchestration | Runs templates, workflows, and policy changes across many devices | Makes repeatable work faster and less error-prone |
| Reporting and compliance | Produces audit trails, change records, and state reports | Helps security, operations, and management trust the same record |
The capabilities that separate a useful platform from shelfware
When I evaluate a platform, I start with the truth it can tell me, not the number of charts it ships. A glossy dashboard is not useful if it hides where the issue started, which devices are involved, or what happened after the last change window.
Visibility that actually answers operational questions
Good visibility means more than device-up or device-down status. It should show latency, packet loss, interface errors, route instability, wireless issues, and dependency chains in a way that a human can act on quickly. If the system cannot answer “what changed, who changed it, and what broke afterwards”, it is not really helping operations.
Automation with guardrails
Automation is where many teams overreach. A useful platform should let you standardise repeatable work without hiding the underlying commands, policies, or approval steps. In other words, it should make safe changes easier, not make risky changes faster. I prefer systems that support templates, dry runs, and rollback paths over tools that promise full autonomy before the network is even cleanly modelled.
Integration that fits the rest of the stack
Network tooling rarely lives alone. It needs to talk to ticketing systems, identity platforms, SIEM tools, cloud consoles, and sometimes a CMDB. Strong APIs, sane webhooks, and clean export options matter more than a long list of marketing integrations. If the platform traps your data, it becomes harder to trust during incidents and harder to leave later.
Read Also: What is NSX-T? Your Guide to VMware's Network Hypervisor
Reporting that is useful outside the NOC
Reporting should help more than the on-call engineer. Security teams want change history and segmentation evidence. Finance wants lifecycle and utilisation data. Leadership wants to know whether the estate is becoming more reliable or just more expensive. A good platform gives each audience a different view without forcing everyone to interpret raw telemetry.
Once those basics are covered, the next question is not feature count but fit. That is where deployment model, ownership, and operating style start to matter more than brand names.
How to choose the right fit for a UK environment
For a UK organisation, the practical decision is usually shaped by geography, compliance, and team capacity. A centralised cloud platform can be ideal for a distributed business with branches across the country, but a regulated organisation may care more about local control, auditability, and where telemetry is stored. The right answer depends less on fashion and more on how the network is actually run.
| Approach | Best for | Strengths | Trade-offs |
|---|---|---|---|
| SaaS platform | Multi-site teams, lean IT groups, faster rollout | Quick deployment, easier upgrades, remote access | Less control over data location and release timing |
| On-premise suite | Regulated or latency-sensitive environments | Greater control, easier local integration, tighter governance | More maintenance, patching, and infrastructure overhead |
| Open-source stack | Teams with strong engineering skills and a clear budget constraint | Flexible, transparent, often cheaper to start | More assembly required, support varies, ownership sits with your team |
| Hybrid model | Enterprises with mixed legacy and cloud estates | Balances control with accessibility | Can become messy if responsibilities are not clearly defined |
When I help teams narrow the field, I ask them to run a short pilot on real devices, not a synthetic demo. Two to four weeks is usually enough to see whether discovery is accurate, whether alerting is noisy, and whether the platform can survive a genuine change workflow. If the trial only works in a clean lab, it has not yet proved anything.
It is also worth checking whether the tool matches your operating style. Some teams want deep customisation and are happy to manage more complexity. Others need a simpler service that the whole support function can understand. Neither approach is wrong, but choosing the wrong one creates long-term friction that no feature checklist will fix.
With the fit question clear, the more interesting part is what usually goes wrong after purchase, because that is where expensive tools often lose their value.
The mistakes that make the network harder to trust
The failure mode I see most often is not bad software. It is a poor operational model wrapped around decent software. Teams buy the platform first and only then realise they have no clean naming standard, no reliable inventory, and no agreed change process. At that point the tool starts reflecting the mess instead of fixing it.
- Overloading alerts - If every minor interface fluctuation generates an alarm, people stop reacting to the system at all.
- Skipping discovery - If the software does not accurately map devices, links, and dependencies, every dashboard becomes suspect.
- Automating too early - Pushing config at scale before rollback, approvals, and testing are mature is a fast way to create a bigger incident.
- Ignoring access control - If too many people can change critical settings, the audit trail becomes evidence of risk rather than control.
- Separating security from operations - A network can be technically “up” and still be the wrong shape from a segmentation or exposure standpoint.
- Keeping data trapped - If exports are weak, you will struggle to prove compliance, analyse incidents, or switch tools later.
The common thread is trust. A platform only becomes operationally useful when the team believes the data, the history, and the rollback paths. If any one of those is missing, the software may still look impressive, but it will not be dependable under pressure. That is exactly why the next shift in the category matters.
Why automation and security are converging in 2026
The direction of travel is clear: network operations, observability, and security are moving closer together. The old model of “the network team owns connectivity, security owns policy, and the rest is someone else’s problem” no longer works cleanly in hybrid estates. Modern platforms increasingly need to understand configuration state, exposure, segmentation, and performance at the same time.
I would be cautious about any vendor that sells AI as a substitute for operational discipline. AI-assisted correlation can be useful for reducing alert noise and surfacing likely causes, but it still depends on accurate topology, clean telemetry, and sane change history. In practice, the strongest systems use automation to narrow attention, not to replace judgement.
Another important shift is the move towards policy-driven control. Instead of manually editing device after device, teams define intent once and let the platform enforce it across sites, clouds, and segments. That is especially valuable for branch-heavy organisations, but it only works when the underlying model is maintained carefully. If the source of truth drifts, the automation simply scales the mistake.For future-focused teams, the best question is not whether the platform has a copilot or a dashboard. It is whether it can keep the network understandable as complexity grows. That brings the whole discussion back to a practical buying rule that is easy to forget when sales demos are polished.
The quickest way to test whether a platform will help or just add noise
Before I would trust a platform in production, I would insist on five live checks. First, can it discover the estate without a week of manual cleanup? Second, can it show a real change history and produce a useful diff? Third, can it handle an intentional failure and guide rollback? Fourth, can it integrate with your ticketing and identity systems without awkward workarounds? Fifth, can another engineer understand it after a short handover?
If the answer to any of those is vague, the risk is not theoretical. The tool may still be valuable, but only if the team is prepared to do the hard work around it. My rule is simple: buy the smallest platform that gives you truthful inventory, clear change control, and automation you can explain to another engineer. Everything else is secondary until those three are solid.