Modern network infrastructures are the hidden operating system of almost every business process, from cloud apps and hybrid work to customer-facing services and security controls. In practice, the real challenge is not defining the network, but deciding how to build one that stays fast, resilient, and manageable as traffic, devices, and threats grow. This article breaks down the core components, the way the architecture fits together, the design choices that matter most, and the security and resilience rules that are shaping network work in the UK.
The practical shape of a network you can actually run
- A usable network starts with a few essentials: switching, routing, wireless, identity, DNS, and monitoring.
- Architecture matters more than individual devices, because failure domains and traffic flow decide how the network behaves under stress.
- In 2026, zero trust and segmentation are no longer optional extras; they are part of the baseline design.
- For UK organisations, resilience is also a compliance issue, especially in communications and essential services.
- The best designs are simple to understand, easy to observe, and built with redundancy where outages would hurt most.
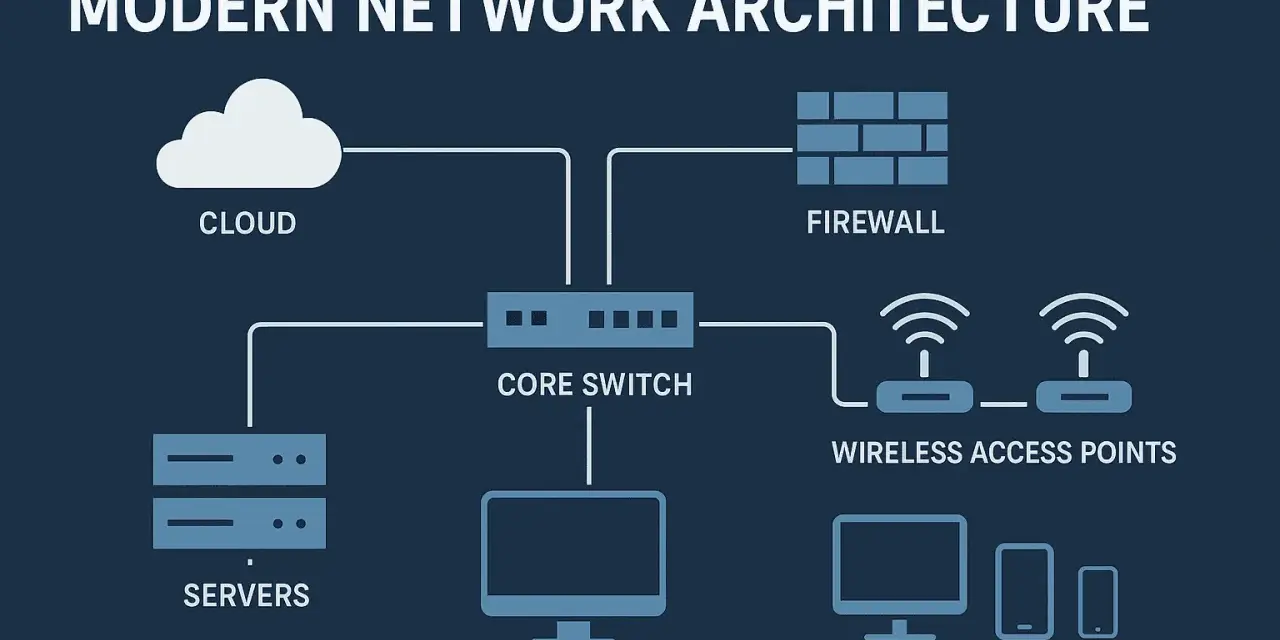
What a modern network is made of
If I strip the topic down to essentials, a network is a set of services that move traffic, enforce policy, and keep users and applications talking to each other. The mistake I see most often is treating only the visible hardware as the network, while ignoring the services that quietly carry the whole environment.
| Component | What it does | Why it matters |
|---|---|---|
| Switches | Connect devices inside a local network | They determine speed, segmentation, and how much east-west traffic the LAN can handle |
| Routers | Move traffic between networks | They connect branches, data centres, cloud networks, and the internet |
| Wireless access points | Provide Wi-Fi access | They are often the user experience bottleneck in offices, schools, and public spaces |
| Firewalls | Apply traffic policy and inspection | They still matter, but they should not be the only security control you rely on |
| DNS, DHCP, and NTP | Resolve names, assign addresses, and keep time in sync | These are small services with outsized impact when they fail |
| Load balancers and CDNs | Spread demand across servers and locations | They improve availability and performance for public-facing services |
| Identity and access systems | Decide who or what is allowed in | They are now central to the network, not separate from it |
| Monitoring and telemetry | Show what is happening in real time and over time | Without visibility, troubleshooting becomes guesswork |
What matters here is not just the list, but the dependency chain. A service may look like an application issue when the real problem is DNS, a misconfigured VLAN, or a failing uplink. I usually tell teams to map the hidden dependencies first, because that is where most outages become expensive. Once you see those dependencies clearly, the next step is understanding how the pieces are arranged.
How the architecture fits together
A useful network is built in layers, even if the actual implementation is more cloud-heavy than the classic campus diagrams people still draw. I usually think in terms of where traffic starts, where it needs to be inspected, and which components must survive failure without taking the whole environment down.
The access layer
This is where users, printers, cameras, phones, sensors, and laptops connect. It includes wired switch ports and Wi-Fi, and it is the part of the network that feels closest to the user. It is also where bad assumptions become visible fast: poor wireless planning, weak guest isolation, and messy device onboarding all show up here.
The core and distribution layers
These layers move traffic between parts of the organisation. In smaller environments, they may be collapsed into a simpler design; in larger ones, they separate local forwarding from higher-speed backbone functions. The design goal is stability. If the access layer is noisy, the core should still keep moving traffic cleanly.
Read Also: Network Infrastructure Support - Is Yours Good Enough?
The edge and the cloud
This is where traffic leaves the private network for the internet, SaaS platforms, remote workers, or cloud applications. In 2026, this boundary is far less important than it used to be, because a lot of business traffic never touches a traditional data centre. That is why many teams now design around distributed access, secure tunnels, and policy enforcement closer to the user or workload.
One technical distinction helps here: the control plane decides where traffic should go, while the data plane actually forwards the packets. Keeping those functions resilient and observable is one of the simplest ways to make the whole architecture easier to operate. From there, the real decisions become architectural rather than purely technical.
The design choices that matter most
I rarely recommend starting with vendor brochures. I start with traffic patterns, business criticality, and failure tolerance, because those three things decide whether a design will age well or become an expensive patchwork.
| Design choice | Best when | Main trade-off |
|---|---|---|
| Hub-and-spoke WAN | Most traffic should pass through a central site or cloud security layer | Simple to govern, but remote sites may feel slower |
| Full mesh | Sites communicate heavily with one another and low latency matters | Harder to manage and usually more expensive |
| SD-WAN | You need policy-driven routing across multiple links and cloud services | Flexible, but only if the policies are disciplined |
| Flat network | The environment is small, temporary, or non-critical | Easy to deploy, but the blast radius is large |
| Segmented network | You need better isolation between users, devices, and services | Requires more planning and ongoing governance |
The biggest practical difference is between a network that merely connects things and one that actively shapes risk. Segmentation, routing policy, and redundant paths can all look like overhead until the day they prevent a problem from spreading. If I had to choose one habit that pays off most often, it would be designing for failure domains, meaning the smallest area that can fail without taking everything else with it. That naturally leads into the security question, because modern architecture and modern security are no longer separable.
Security and resilience now define the network
Classic perimeter thinking still has a place, but it is not enough on its own. NIST’s zero trust model is useful here because it assumes location does not equal trust, and it treats authentication and authorization as separate decisions made before access is granted. That is a better fit for remote work, cloud services, BYOD devices, and hybrid environments than the old idea that anything inside the boundary is safe.
For me, the practical version of that thinking usually includes five controls:
- Identity-first access so users and devices are verified before they touch critical resources.
- Micro-segmentation so a compromise in one area does not automatically spread everywhere.
- Encrypted transport for traffic crossing untrusted or semi-trusted networks.
- Continuous monitoring so unusual traffic, failures, and policy drift are visible quickly.
- Redundancy and failover testing so a single fault does not become an outage.
Resilience also has a regulatory dimension in the UK. Ofcom’s current network-security and resilience work makes it clear that communications providers and operators of essential services are expected to manage security risks, minimise consumer impact, and report network failures or breaches. That matters beyond telecoms, because it reflects the direction of travel for the broader digital infrastructure sector: availability is now a governance issue as much as an engineering one.
The compromise is that stronger security usually adds operational friction. More checks, more logs, and more policy layers can slow teams down if they are badly designed. The answer is not to remove the controls, but to make them coherent. A clean policy model, decent identity tooling, and a well-tested rollback path usually outperform a pile of separate point solutions. Once that is in place, the implementation work becomes much less chaotic.
A practical roadmap for building or modernising one
If I were modernising a network from scratch, I would not start with switches or firewall models. I would start with the business map, then build the architecture around the real flows that matter.
- Inventory users, sites, apps, and dependencies. List what depends on the network, including cloud services, remote workers, and hidden infrastructure such as DNS and identity.
- Map the traffic patterns. Separate internet-bound traffic, internal east-west traffic, voice, video, and application-to-application flows.
- Define service tiers. Decide which systems can tolerate interruption, which cannot, and which need active-active or fast failover.
- Choose the right topology. Pick hub-and-spoke, mesh, SD-WAN, or a hybrid model based on traffic and governance, not habit.
- Build redundancy where failure is costly. Two diverse uplinks, separate power paths, and independent failure domains usually matter more than buying the most expensive hardware.
- Separate management from user traffic. Keep admin access, logging, and orchestration on a protected path so a user-facing problem does not block recovery.
- Test failover before you need it. A design is only resilient if you have watched it fail safely in controlled conditions.
This is also where change management becomes part of architecture. A network that is easy to document but hard to modify will eventually drift into risk. I would rather see a slightly simpler design that the team understands than a technically elegant one that nobody can operate under pressure. That is where many organisations go wrong, and the mistakes are usually predictable.
The mistakes that create the biggest hidden risk
Most network failures are not dramatic. They are boring, cumulative, and avoidable. The same patterns come up often enough that they are worth naming directly.
- Designing around hardware instead of traffic. Teams buy devices before they understand the flows they need to support.
- Assuming Wi-Fi is separate from the network. Wireless is often the primary access layer, not an add-on.
- Ignoring identity and name services. If authentication, DNS, or time sync fail, the rest of the stack can behave unpredictably.
- Creating fake redundancy. Two links that share the same provider route, building, or power source are not truly diverse.
- Leaving visibility until later. Logging and telemetry are easiest to add before production pressure forces shortcuts.
- Over-segmenting without operational discipline. Too many policies can make the network harder to use and harder to recover.
These are not theoretical problems. They are the reasons a network looks healthy in a diagram and fragile in practice. The good news is that they are fixable, and usually with better structure rather than bigger budgets. That is the lens I would keep in mind when deciding what should age well and what should be revisited regularly.
The decisions that age well
The network choices that last are usually the ones that stay understandable under stress. Clear segmentation, visible dependencies, diverse paths, and identity-based access age better than clever shortcuts or oversized perimeter boxes. If I had to reduce the whole subject to one idea, it would be this: a network should make it easy to move the right traffic, hard to trust the wrong traffic, and simple to recover when something breaks.
- Review critical dependencies before changing topology or security policy.
- Test failover and restore paths on a regular schedule, not just after incidents.
- Keep the architecture simple enough that another engineer can explain it quickly.
- Revisit visibility, logging, and access control whenever you add cloud services or remote users.
That is the practical standard I would use for any network today, whether it serves a small office, a hybrid enterprise, or a UK-based service that cannot afford downtime.