
What you need to know first
- Virtual networking is about abstracting connectivity so policy and automation matter more than manual device-by-device changes.
- The main building blocks are overlays, SDN control, NFV, virtual switches, and policy-driven segmentation.
- The biggest value shows up in hybrid estates, branch sprawl, multi-tenant environments, and security isolation.
- Buying the software is not the same as fixing the architecture; observability and operating discipline decide the outcome.
- A pilot should prove provisioning speed, visibility, rollback, and MTU handling before you scale.
Why virtual networking matters now
I usually see the need for virtual networking when a team has outgrown the old pattern of changing physical switches, firewalls, and VLANs every time an application or site changes. That approach works until it does not. Once you have multiple environments, frequent releases, remote offices, or mixed cloud and on-prem workloads, the network starts to slow everything down instead of enabling it.
The real gain is decoupling. Application topology no longer has to mirror the physical topology, which means I can isolate traffic, move workloads, and apply policy without redesigning the entire fabric. In practical terms, that supports faster provisioning, cleaner segmentation, and better alignment between infrastructure and security teams. It also explains why these platforms matter most in hybrid estates, where consistency is harder to maintain than raw bandwidth.
That said, I would not oversell it. A small, stable network with very few changes may not need this level of abstraction at all. The value appears when complexity is already expensive, and when the cost of a bad change is higher than the cost of adding another layer of control. That is where the architecture itself becomes worth studying.
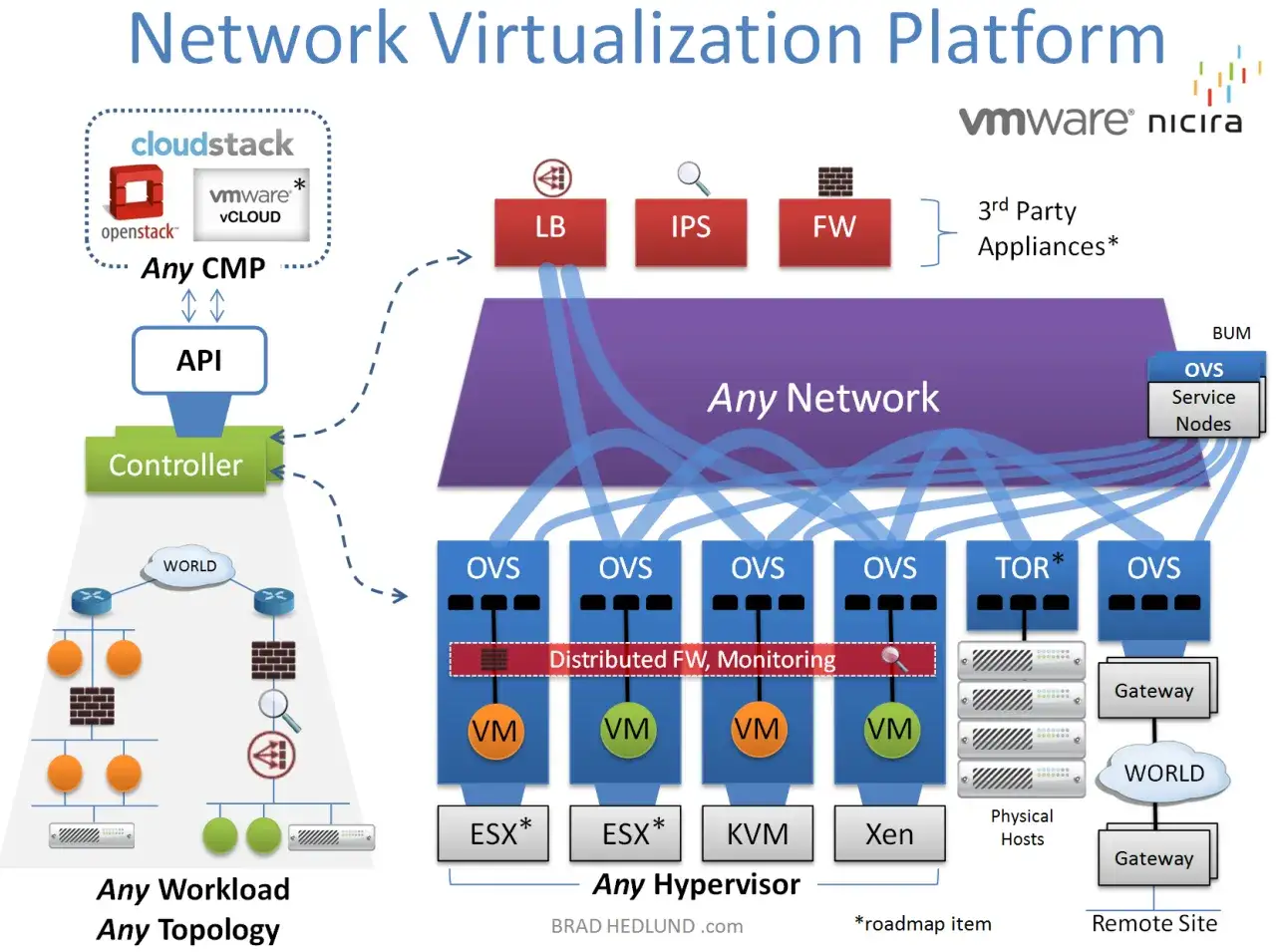
The building blocks behind the model
The easiest way to think about the stack is to separate the underlay from the overlay. The underlay is the physical transport: switches, routers, links, and IP reachability. The overlay is the logical network that rides on top of it. That split is what makes modern virtual networking flexible, because policy can live above the transport while the transport stays comparatively simple.
There are a few core pieces I always look for. SDN, or software-defined networking, moves control into software so routing and segmentation decisions can be automated. NFV, or network functions virtualisation, runs functions such as firewalls, load balancers, or routers as software instead of fixed appliances. A virtual switch handles packet forwarding inside a host, while orchestration tools push policy, create tunnels, and keep the virtual topology consistent.
This is also where the technical limits show up. Traditional VLANs top out at 4,094 usable IDs, which is one reason overlays such as VXLAN became so popular in large estates. VXLAN and similar encapsulation methods solve scale, but they also add overhead, so I always check MTU, latency, and troubleshooting visibility before I let the design near production. If the team cannot explain how packets move through the underlay and back out of the overlay, the architecture is still too opaque.
Security is part of the model, not an optional extra. Microsegmentation, which applies policy at a much finer level than a perimeter firewall, is often the biggest practical win because it reduces lateral movement inside the estate. Once those building blocks are clear, the next question is which type of platform actually fits the job.
The main solution families worth comparing
When I compare platforms, I group them by the problem they solve first, not by vendor branding. That keeps the conversation honest. Some products are really about software-defined connectivity, some about virtualised network functions, and some about making cloud-native environments behave like a single policy domain.
| Approach | Best fit | Strengths | Watch-outs |
|---|---|---|---|
| SDN overlay platforms | Private cloud, data centre segmentation, multi-tier application environments | Central policy, consistent automation, strong east-west control | Needs a well-designed underlay and good observability |
| NFV and service chaining | Virtual firewalls, routers, WAN functions, branch service delivery | Replaces appliance sprawl, scales faster than hardware refresh cycles | Performance, licensing, and packet path complexity can creep up |
| Hypervisor-integrated networking | Virtual machine estates and private cloud platforms | Tight workload-level policy, mature operational model | Can become tied to a specific stack or vendor ecosystem |
| Cloud-native virtual networking | Public cloud, containers, and hybrid cloud estates | Native API integration, elastic scaling, easier cloud automation | Policy can fragment across providers if governance is weak |
My shorthand is simple: if the pain is application segmentation, I look first at overlays; if the pain is replacing physical functions, I look at NFV; if the pain is multi-cloud consistency, I look at how the cloud platform handles its own virtual network primitives. The label matters less than whether the platform can be operated cleanly by the people who will actually own it.
That point leads directly to evaluation. A platform can look elegant on paper and still fail in a real organisation if it does not fit the existing security model, support model, and change process.
How I would evaluate one for a UK organisation
For a UK organisation, I would not start with features. I would start with operational fit. If you have offices in more than one city, a separate data centre, cloud workloads, and a security team that insists on auditability, the platform has to support all of that without turning every change into a project.
- Integration with the current estate. It should work with the switches, firewalls, identity systems, and monitoring tools you already run.
- Policy automation. I want APIs, infrastructure-as-code support, and a clear way to map business rules into network policy.
- Visibility. Look for flow logs, topology views, policy simulation, and the ability to trace a packet path without guesswork.
- Security controls. Segmentation, least-privilege access, and east-west inspection should be first-class features, not add-ons.
- Resilience and recovery. Ask how the platform behaves when a controller fails, a site is down, or a policy push needs to be rolled back.
- Exit strategy. If you cannot describe how you would leave the platform, you are already too locked in.
I would also ask for proof that the vendor can support the way UK teams actually work: formal change windows, procurement cycles, audit demands, and a mix of local offices plus cloud services. In regulated or security-sensitive environments, the right answer is often the one that produces the cleanest evidence trail, not the one with the longest feature list. Once the operating model is clear, rollout becomes much easier to plan.
What a realistic rollout looks like
A sensible rollout usually starts with one contained environment, not the whole estate. I would map current traffic, identify the most painful application path or branch, and use that as the pilot. The point is to prove that the platform improves a real workflow, not a synthetic demo.
- Map the current network. Document dependencies, traffic flows, and any special routing or firewall rules that matter.
- Choose a narrow pilot. One application stack, one branch pair, or one cluster is enough to expose most design flaws.
- Define the policy model first. Name spaces, segments, and trust boundaries before you start building tunnels or policies.
- Validate the underlay. Confirm MTU, latency, route symmetry, and failover behaviour before overlay traffic is allowed in.
- Automate and test rollback. The first deployment should include a clean reversal path and a way to compare intended versus actual state.
- Migrate in waves. Move workloads gradually so a bad assumption affects one zone, not the entire business.
For planning purposes, I would treat a contained pilot as a matter of weeks and a broader multi-site rollout as a matter of months, depending on change control, legacy dependencies, and how much of the estate already has usable telemetry. If someone promises a full transformation in a few days, I would be cautious. The hard part is rarely the software itself; it is the cleanup work around old assumptions, unclear ownership, and inconsistent policy.
That is why the next section matters: the cost profile is broader than the licence, and the hidden costs decide whether the project becomes a win or a maintenance headache.
The costs and trade-offs that shape the real return
In almost every case I have seen, the software licence is only one line in the budget. The more important costs are integration, skills, observability, and the time it takes to make the new model reliable enough for production. If a platform saves engineering time later but requires months of manual work up front, that is still fine if the pain it removes is large enough. If the estate is small and stable, the same platform may be too much machine for too little problem.
- Licensing and support. Often the most visible cost, but rarely the whole story.
- Training and operations. Teams need time to learn policy models, failure modes, and troubleshooting methods.
- Telemetry and observability. Good visibility tools are not optional; they are what make the platform usable.
- Migration effort. Rebuilding old rules, routes, and exceptions takes real labour.
- Performance headroom. Encapsulation, security inspection, and virtualised functions can change throughput and latency expectations.
I only expect a strong business case when the platform reduces repeat manual work, shortens change windows, improves segmentation, or removes enough hardware sprawl to matter. In other words, the return comes from speed, control, and lower operational risk, not from the idea of virtualisation itself. The last thing I would do before cutover is check whether those benefits can survive contact with a real production incident.
The checks I would insist on before the first production cutover
The best network virtualization solutions are the ones that reduce change risk without creating a second system nobody understands. Before I sign off on production, I want three things to be true: the team can see the traffic path, the team can undo a bad change quickly, and the policy model is simple enough that another engineer can support it six months later.
I would insist on a documented rollback plan, a clean audit trail, and a failure test that is more realistic than a lab demo. I would also check whether the design still makes sense if one controller, one site, or one cluster disappears. If it does, the platform is probably ready. If it does not, the architecture is still carrying too much hidden risk.
That is the standard I would use in 2026: build the overlay only when the underlay is trustworthy, automate only what you can observe, and choose the platform that makes the network easier to operate rather than merely more abstract. That is where virtual networking stops being a trend and starts being useful.