TLS 1.3 is a genuine protocol overhaul, not a cosmetic bump. It shortens the handshake, encrypts more of the negotiation earlier, removes legacy cryptographic baggage, and gives modern systems a cleaner security baseline. The TLS 1.3 changes matter because they affect both performance and the failure modes you have to watch for in production.
The biggest gains are speed, tighter defaults, and fewer legacy traps
- A normal connection usually completes in 1 round trip, and resumed sessions can use 0-RTT.
- Static RSA, renegotiation, and TLS-level compression are gone.
- Cipher suites now choose the AEAD cipher and hash, not the whole key exchange story.
- All standard public-key handshakes deliver forward secrecy by default.
- Early data is fast, but it is also replayable, so it needs strict rules.
Why the handshake got shorter and safer
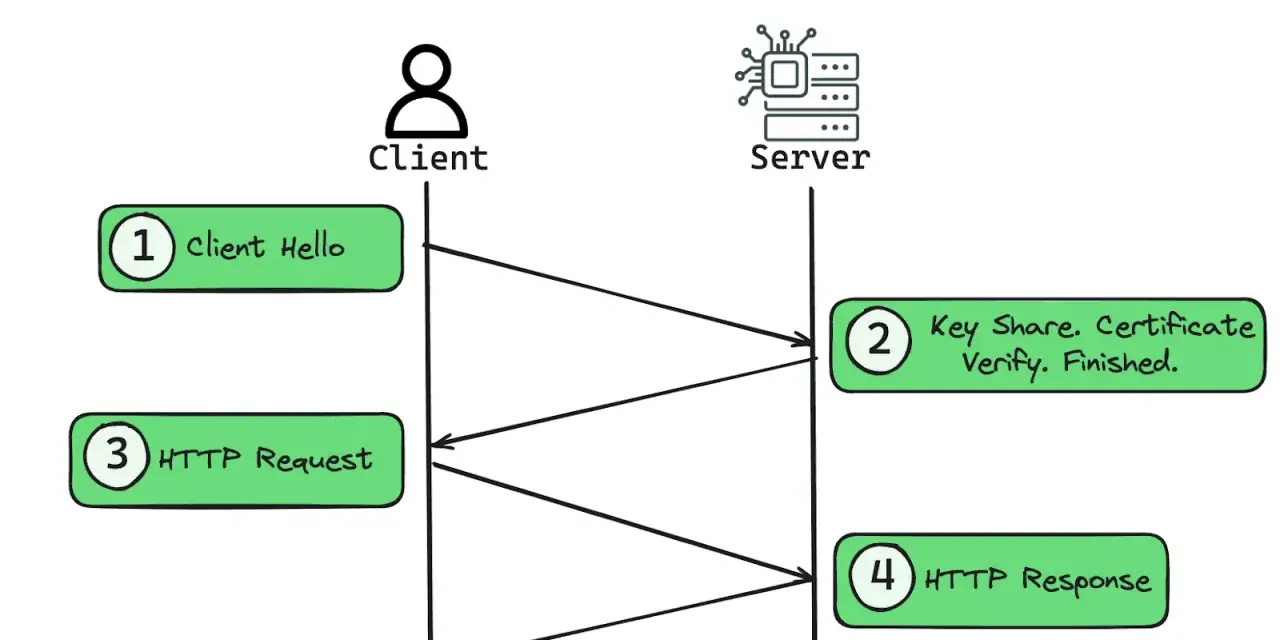
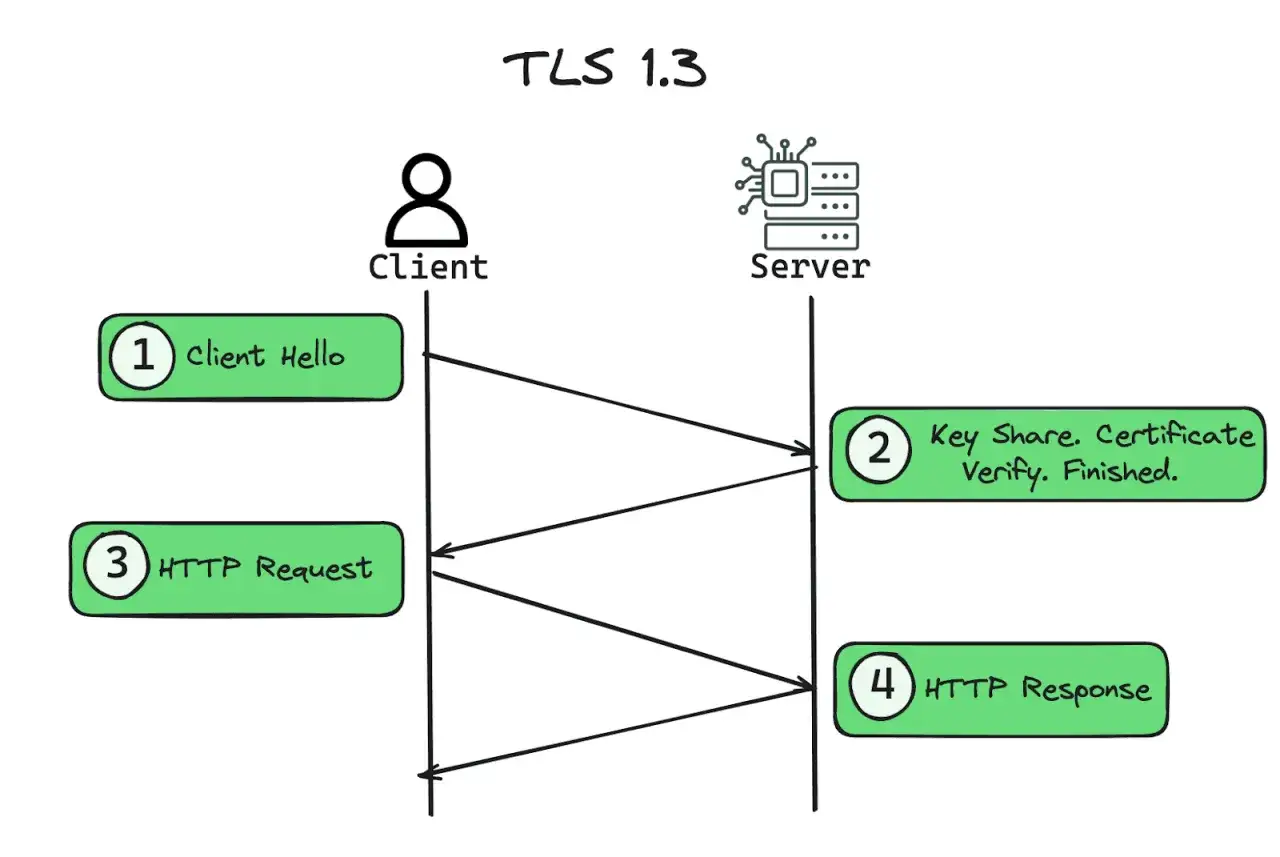
With TLS 1.2, a new connection usually took more back-and-forth before the application could send useful data. TLS 1.3 cuts that to one round trip for a full handshake, and a returning client can often send 0-RTT early data before the handshake is fully complete. That is a big deal on high-latency mobile links and across geographically distributed services.
The other important shift is visibility. In TLS 1.3, most of the handshake after ServerHello is encrypted, which reduces passive inspection and makes the protocol less chatty on the wire. It is not privacy magic, though: the initial ClientHello still has to travel in the clear, so I think of this as a strong reduction in exposure, not total invisibility.
| Area | TLS 1.2 | TLS 1.3 | Practical effect |
|---|---|---|---|
| Handshake latency | Usually 2 RTT | Usually 1 RTT | Lower setup delay for every new connection |
| Resumption | Session IDs or tickets | Session tickets plus optional 0-RTT | Faster reconnects, but early data needs discipline |
| Version negotiation | Legacy version field carried more weight |
supported_versions does the work |
Less version-intolerance pain in mixed estates |
| Handshake encryption | More of the exchange was visible for longer | Most of the handshake after ServerHello is encrypted | Less passive observation and less protocol noise |
There is also a small but useful recovery path called HelloRetryRequest. If the server needs a different key share or more parameters before it can proceed, it can ask the client to try again instead of failing the connection immediately. That sounds minor, but in real deployments it helps the protocol degrade more gracefully in messy networks. The next question is what had to disappear to make that cleaner design possible.
What was removed from older TLS versions
The cleanest way to understand TLS 1.3 is to look at what it refused to carry forward. The protocol dropped features that had become either risky, hard to secure consistently, or simply too awkward to keep around. My view is that this is where most of the security value comes from: fewer escape hatches mean fewer accidental weak spots.
| Removed capability | Why it matters | What to use instead |
|---|---|---|
| Static RSA key transport | It does not give forward secrecy and has a long history of attack surface | Use ephemeral (EC)DHE or PSK with (EC)DHE |
| Renegotiation | Complex session re-entry made implementations harder to reason about | Use post-handshake authentication or application-level reauth |
| TLS-level compression | Compression adds a side-channel and operational complexity | Compress data at the application layer if you really need it |
| Old cipher-suite combinations | Too many awkward or weak pairings were possible | Stick to the TLS 1.3 suite set |
That deletion list has an important side effect: the protocol becomes much easier to audit. When I look at a modern stack, I would rather see a small number of well-understood primitives than a large menu of historical options that only exist for compatibility. Once you remove that baggage, the key schedule itself becomes easier to follow, which is the next improvement worth understanding.
How the key schedule and cipher suites changed
TLS 1.3 also simplified the cryptographic menu. Cipher suites no longer bundle key exchange, authentication, encryption, and MAC choices into a single opaque block; they now mainly select the record-protection algorithm and hash, while the handshake uses a much cleaner key schedule built around HKDF. That is a small wording change on paper and a large maintenance win in practice.
The suite list is deliberately short:
| Cipher suite | Typical fit | Why it is used |
|---|---|---|
TLS_AES_128_GCM_SHA256 |
General-purpose default | Fast, widely accelerated, and straightforward to support |
TLS_CHACHA20_POLY1305_SHA256 |
Mobile or non-AES hardware | Strong performance when AES acceleration is weak or absent |
TLS_AES_256_GCM_SHA384 |
Higher-assurance policy | Fits environments that prefer a 256-bit AES profile |
TLS_AES_128_CCM_SHA256 and TLS_AES_128_CCM_8_SHA256
|
Constrained or specialised devices | Useful where implementation constraints matter |
- AEAD only means encryption and integrity are bound together instead of being mixed from older parts.
- HKDF drives key derivation, which makes the secret schedule more structured and easier to reason about.
- KeyUpdate lets either side refresh traffic secrets after the handshake without renegotiating the whole session.
I like this part of the protocol because it reduces the odds that a configuration mistake quietly degrades security. The trade-off is that the design leaves less room for convenience shortcuts, and that becomes most visible when you enable early data.
Where 0-RTT helps and where I keep it off
0-RTT is the feature that makes people either enthusiastic or nervous, and both reactions are reasonable. It lets a returning client send application data before the handshake is fully finished, which saves latency, but those first bytes can be replayed. The protocol therefore expects the server to use anti-replay measures or an equivalent operating model, and if a deployment falls back to PSK without (EC)DHE, that path can also lose the usual forward-secrecy guarantee.
Good fits
- Static asset retrieval
- Read-only API calls with no side effects
- Cache refreshes and warm-up requests
- Telemetry or analytics events that can tolerate duplication
Read Also: Stop Lateral Movement - Secure Your Network Now
Bad fits
- Payments and money movement
- Password changes and account recovery
- Login flows that mutate server state
- Inventory, booking, or order updates
My rule is simple: I treat 0-RTT as an allowlist feature, not a blanket performance boost. If a request has business consequences, I keep it on the 1-RTT path or reject it when it arrives too early. That choice matters even more in regulated or customer-facing environments, where replay risk is not a theoretical footnote but an operational concern. From there, the practical question becomes how these protocol changes behave once they meet real infrastructure.
What the TLS 1.3 changes mean for real deployments
By 2026, the question is rarely whether TLS 1.3 is worth supporting. The real question is where the last compatibility edge cases still live. For UK organisations, I usually find the friction in older appliances, inspection boxes, or service chains that still expect the older handshake shape rather than in modern browsers.
| Deployment point | What to verify | Common surprise |
|---|---|---|
| CDN or load balancer | It actually negotiates TLS 1.3 with representative clients | The edge advertises support, but debugging still assumes TLS 1.2 behaviour |
| Reverse proxy or WAF | It can terminate or pass through the new handshake cleanly | The middlebox misreads encrypted handshake messages as a failure |
| Internal service mesh | mTLS and certificate validation still work after the upgrade | A hidden dependency on renegotiation shows up late in testing |
| Legacy clients | TLS 1.2 fallback exists only where a real client still needs it | Older devices fail once 1.3 becomes the only accepted version |
| Monitoring and packet capture | Tools still tell you which side failed and why | Operators mistake encrypted behaviour for a broken connection |
My rule of thumb is simple: keep TLS 1.2 only for the clients that truly need it, and remove it everywhere else. The point of TLS 1.3 is not to keep two full protocol stacks alive forever; it is to let the modern path be the default and the legacy path the exception. Before I call a rollout done, I check a few things that usually catch the hidden problems.
The checks I would run before calling the rollout done
- Confirm that browsers, mobile clients, and CLI tools all negotiate TLS 1.3 on the edge you actually serve.
- Test through the oldest proxy, firewall, or inspection appliance still in the request path.
- Verify that session resumption works as expected and that ticket lifetimes match policy.
- Keep 0-RTT disabled until you have a narrow allowlist of replay-safe operations.
- Check that logs and traces still give you enough detail when a handshake fails mid-flight.
If I had to reduce the whole protocol update to one sentence, I would say this: TLS 1.3 trades legacy flexibility for a cleaner, faster, and more defensible security model. That is a good trade for most modern systems, and a careful one for anything that still depends on older TLS behaviour.