Dedicated cloud environments are appealing because they reduce tenant noise and give you tighter control over identity, network paths, and data placement. The trade-off is simple: the more control you keep, the more security you must operate yourself. In private cloud security, the real work is not the hardware; it is the operating model, especially around access, segmentation, logging, backups, and recovery.
What matters most before you start hardening the platform
- Identity and the control plane usually matter more than the brand of stack underneath them.
- Segmentation should separate administration, production, development, and recovery paths.
- Encryption helps most when keys and workloads are not managed by the same weak controls.
- Backups need isolation and restore testing, not just storage.
- UK governance should line up with UK GDPR, cloud guidance, and any sector rules you already carry.
- Most incidents in these environments are caused by configuration drift, not exotic exploits.
What a private cloud actually changes about risk
A private cloud is usually provisioned for one organisation, but it may still be managed by a third party and hosted on- or off-premises. That matters because the security boundary is not a physical room; it is the mix of identity, hypervisors, networking, storage, API access, and operational discipline. I treat that as a narrower tenancy model, not an automatic guarantee. The NCSC Cloud Security Principles are useful here because they push you to check separation, operational security, user management, and auditability rather than trusting the label.
The question I ask first is simple: if one admin token is stolen, what else can the attacker reach?
Once you ask that, the main risk areas become much easier to map.
The risk areas I would test first
I start with the places that turn one mistake into an estate-wide incident. This is where most real breaches begin, because cloud platforms amplify ordinary failures like weak access control, bad segmentation, and untested recovery.
| Risk area | Why it matters | What good looks like |
|---|---|---|
| Privileged identity | Admin accounts are the fastest path to total compromise. | Phishing-resistant MFA, separate admin accounts, just-in-time elevation, and weekly review of break-glass access. |
| Management plane exposure | APIs, consoles, and orchestrators are high-value targets. | No public exposure by default, IP allowlisting, a dedicated admin network, and full audit logging. |
| Lateral movement | Flat networks let one compromised workload reach many others. | Deny-by-default segmentation, microsegmentation where it adds value, and separate zones for dev, prod, and backup systems. |
| Data and key handling | Encryption is weaker when keys and data live under the same weak controls. | Encrypted data in transit and at rest, keys separated from workloads, and a documented rotation and recovery process. |
| Recovery paths | Backups are a favourite ransomware target. | Immutable or isolated backups, separate backup credentials, and monthly restore tests. |
| Supply chain and images | Base images, agents, and automation can quietly import vulnerabilities. | Signed artefacts, scanning, ownership of templates and pipelines, and clear patch accountability. |
When one row is weak, the others have to absorb the blast radius. They usually cannot, which is why I treat the control plane as the asset, not just the workloads. That leads straight into the controls I would prioritise first.
The control stack that makes the biggest difference
This is the stack I would build first. It is less about collecting tools and more about making it hard for an attacker, a careless admin, or a broken pipeline to move from one mistake to a platform-wide incident.
Identity and privileged access
I start here because admin access is the shortest path to everything else.
- Require phishing-resistant MFA or passkeys for privileged users. Passkeys are device-bound credentials that are much harder to phish than passwords.
- Keep daily user accounts separate from admin accounts, and grant elevation only when needed.
- Use RBAC, or role-based access control, so permissions follow job function instead of personal convenience.
- Put break-glass accounts in a vault, monitor them continuously, and test them on a schedule.
If a team cannot explain who can approve elevation, who can revoke it, and how quickly they can do both, the access model is too loose.
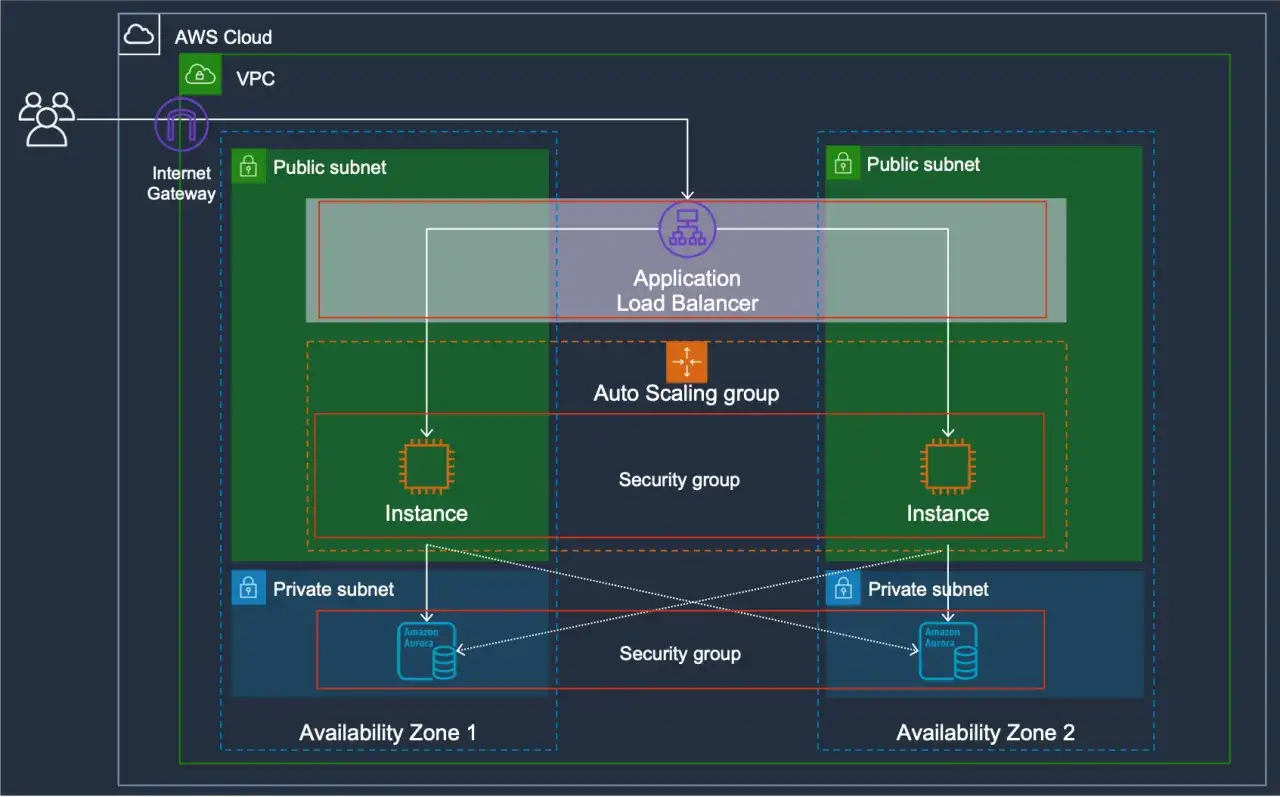
Network and workload isolation
Private clouds fail when the management plane, production workloads, and backup systems share too much trust. I want separate admin networks, production zones, development zones, and recovery zones, with deny-by-default rules between them.
- Keep management interfaces off the public internet unless there is a very strong reason not to.
- Use private endpoints, allowlists, and jump hosts for administration.
- Add microsegmentation where lateral movement is a real concern; it means filtering traffic between workloads rather than trusting a broad subnet.
- Separate production from development and from backup storage, even if the same platform team runs all three.
The point is not perfect isolation. It is to make lateral movement expensive, visible, and slow. That is the practical shape of a zero-trust mindset in a dedicated environment.
Data protection and keys
Data protection works only when key management is stronger than the workloads that use the keys. I want encryption in transit and at rest by default, with keys stored in a dedicated KMS, or in an HSM when the risk profile justifies it. A KMS manages keys; an HSM keeps them in tamper-resistant hardware.
- Separate key administration from workload administration.
- Rotate keys and secrets on a schedule, not only after an incident.
- Protect backups with different credentials and, where possible, a separate trust domain.
- Classify data so you know which systems deserve stricter controls and shorter retention windows.
Encryption is still worth a lot, but only when the operational model around it is disciplined.
Read Also: TLS 1.3 - Why It's Faster, Safer, and Simpler Now
Monitoring, patching, and recovery
This is the section that tells you whether the environment is actually managed or just documented. I would log authentication, configuration changes, image pulls, privilege changes, key usage, and backup operations, then send those logs to storage the platform admins cannot quietly tamper with.
- Alert on unusual privilege escalation, disabled logging, and backup deletion.
- Patch critical host, firmware, and template issues within a defined SLA; my practical target is seven days, or faster if the system is exposed.
- Use Infrastructure as Code so configurations are repeatable and drift is visible.
- Test restores monthly, and run a deeper recovery exercise after any major platform change.
If the team has never restored a full workload under pressure, I would not call the recovery plan proven. Once these controls are wired together, the compliance conversation becomes much easier to handle.
Why UK compliance changes the design
For UK organisations, the question is not only whether the platform is hard to attack; it is whether you can justify the controls against the data and the risk. The ICO expects security measures to be appropriate to the nature, scope, context, purpose, and cost of the processing, so a platform carrying customer records should not be defended like a casual internal lab. That pushes you toward evidence: ownership, change history, access reviews, and recovery results.
| Layer | What it helps with | What it does not solve |
|---|---|---|
| UK data protection duties | Risk-based security and accountability for personal data | It does not tell you how to build the platform |
| Cyber Essentials baseline | Core hygiene around firewalls, secure configuration, access control, malware protection, and updates | It does not cover every cloud-specific failure mode |
| Cloud-specific guidance and internal policy | Provider separation, logging, and operational expectations | It still needs engineering evidence and regular testing |
I use this as a layering model: legal duties define the floor, cloud guidance shapes the platform, and local controls handle the exact risks of the workload. That baseline is useful, but it does not remove the usual mistakes that create incidents.
The mistakes that look harmless until they become incidents
Most expensive incidents come from boring decisions that were left unchallenged for months. I see the same patterns again and again:
- Shared admin habits. One directory, one set of credentials, and one person who can do everything is convenient until it is not.
- Backups in the same blast radius. If the production compromise can delete recovery data, the backup is decoration.
- Template drift. A secure golden image becomes weak after repeated manual fixes and one-off exceptions.
- Trusting internal traffic too much. Internal does not mean benign, especially after phishing or stolen credentials.
- Confusing encryption with resilience. Encryption protects the contents; it does not restore a deleted service.
- Skipping restore drills. If you have never restored the platform end to end, you do not really know how long recovery takes or how much data you can afford to lose.
These are not glamorous failures, but they are the ones that usually decide whether an incident stays small or turns into an outage with a ransom note attached. That sets up the final question: what do you measure before you trust the platform?
The signals I want before I trust the platform
Before I call a dedicated cloud mature enough for serious workloads, I want to see measurable signs, not policy slides. If these numbers are red, the platform still needs work.
- 100% of privileged accounts protected with MFA or passkeys.
- 0 public management interfaces unless there is a documented exception.
- 100% of critical assets mapped to an owner and a patch SLA.
- Monthly restore tests for the systems that matter most.
- Weekly review of privileged access and any break-glass usage.
- Logging coverage for authentication, configuration, key usage, and backup operations.
If those signals are in place, you usually have a platform that can carry regulated and operationally important workloads with confidence. If they are missing, I would fix the control plane, shrink the trust zones, and prove recovery before trying to scale the estate further. The strongest environments are not the ones with the most isolation on paper; they are the ones with the clearest ownership, the smallest trust zones, and the most reliable recovery path.