Zero trust is no longer a slogan; it is a practical response to hybrid work, cloud services, and the fact that attackers rarely stay inside neat network boundaries. NIST SP 800-207 is the clearest reference point for understanding how zero trust architecture works, what it assumes, and where it fits into real security programmes. In this article I break the model down in plain English, show the parts that matter operationally, and explain how UK teams can apply it without turning the rollout into a rebuild of everything at once.
Here is the practical takeaway before you go deeper
- Zero trust removes implicit trust based on network location and replaces it with explicit, policy-driven verification.
- The publication is an architecture guide, not a product spec or a vendor checklist.
- Identity, device posture, policy enforcement, and telemetry are the controls that make it real.
- Legacy systems can still be supported through a mixed-estate approach instead of being blocked outright.
- For UK organisations, the smartest route is phased adoption around critical workloads, not a big-bang migration.
What the standard actually defines
The core idea is simple, but it changes how security teams think. Zero trust shifts protection away from a static network perimeter and toward the users, assets, and services that are actually being accessed. In practice, that means access is not granted because a device is on an internal subnet or because a user belongs to the right company. It is granted because policy, identity, device state, and context all say the request is acceptable.
What I think many teams miss is that authentication and authorisation are treated as separate decisions made before a session starts. That detail matters because it pushes you to design for each request, each service, and each resource, rather than relying on a one-time “inside the network” assumption that no longer reflects how modern environments work.
The document also stays deliberately abstract. It gives a model, deployment patterns, and use cases, but it does not tell you to buy a single product or follow one rigid rollout path. That is one reason it still reads as relevant in 2026. The idea is broad enough to survive technology shifts, but specific enough to guide real architecture work.
Once that framing is clear, the architecture itself becomes much easier to read.
The building blocks that make zero trust work
In the real world, zero trust only works when the control plane is split into clear jobs. I prefer to think in terms of decision, enforcement, identity, and telemetry, because that keeps the design from collapsing into one oversized “security platform” that sounds complete but behaves loosely.
Policy engine and enforcement point
The policy engine decides whether a request should be allowed, while the enforcement point applies that decision at the proxy, gateway, endpoint, or service layer. If those two roles are blurred together, teams usually end up with brittle exceptions and poor audit trails. The clean split matters because it lets policy change without rewriting every access path.
Identity for users, services, and devices
Every actor needs a strong identity, not just people. Modern zero trust also has to identify workloads, machine accounts, and managed devices, because service-to-service traffic is often where attackers move fastest once they get a foothold. If you cannot tell one service from another, you do not have enough confidence to make fine-grained access decisions.
Device posture and workload health
A valid identity is not enough on its own. The architecture also needs signals such as patch level, secure boot status, endpoint management state, certificate posture, and whether a workload is running in the expected environment. Those checks do not need to be perfect. They need to be relevant to the risk of the action being requested.
Read Also: True Positive vs. False Positive - Master Your SOC Alerts
Telemetry and continuous reassessment
Zero trust is not “authenticate once and forget.” Session behaviour, unusual data access, privilege escalation, and impossible travel patterns all feed back into later access decisions. That continuous loop is what makes the model useful when credentials are stolen after login, because the architecture can still reduce access or shut a session down.
That control loop is also why the old perimeter model struggles once traffic stops living in one building.
Why perimeter security breaks down in hybrid estates
The old model assumed the network boundary was the main boundary of trust. That worked reasonably well when most users, apps, and data lived in one place. It becomes much weaker once people work from home, applications move to SaaS, and sensitive data is split across clouds and on-prem systems.
| Model | What it tends to trust | Where it helps | Main weakness |
|---|---|---|---|
| Perimeter or VPN-first | Network location after login | Simple remote access | Broad internal trust and weak control after the tunnel is open |
| ZTNA | Specific app access for a specific user or device | Remote access to individual services | Does not by itself solve the whole architecture, especially identity and governance |
| Zero trust architecture | Identity, device, policy, and context | Hybrid estates with sensitive resources | Needs stronger policy discipline, telemetry, and operational maturity |
This is why I usually treat VPN replacement as one possible outcome, not the goal itself. If you only change the access path and leave the trust model intact, the security gain is smaller than the marketing suggests. The real win comes from narrowing access to the resource level and making every request earn its way through policy.
That leads straight into implementation, because the architecture only matters if the rollout is realistic.
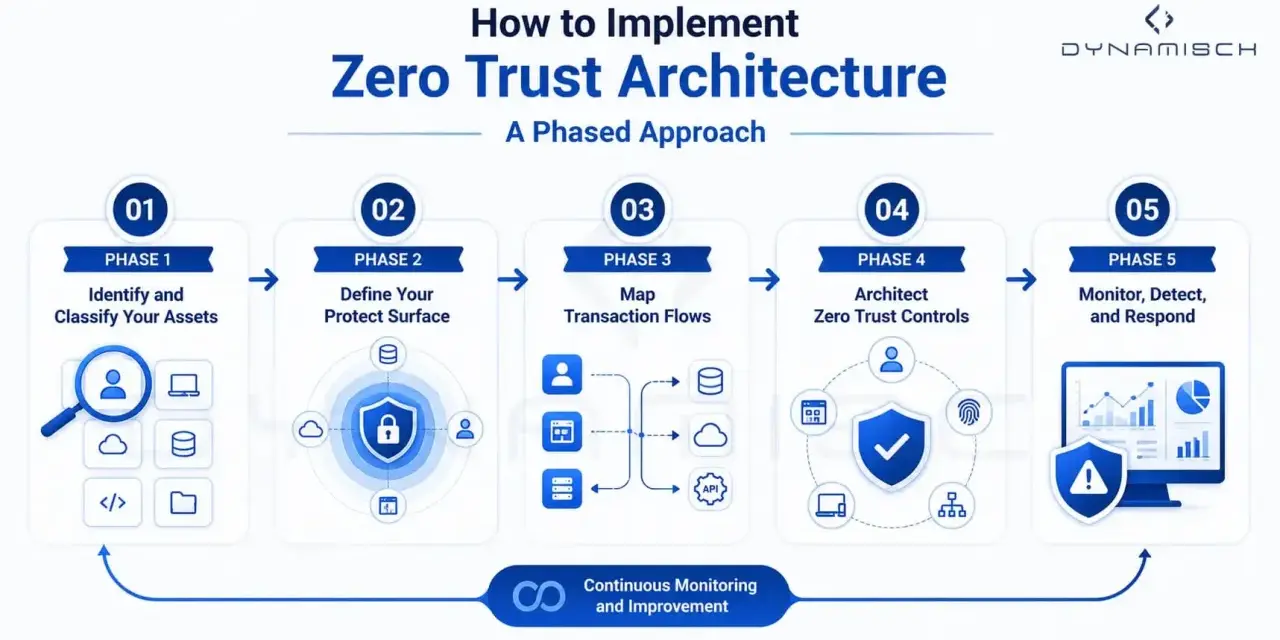
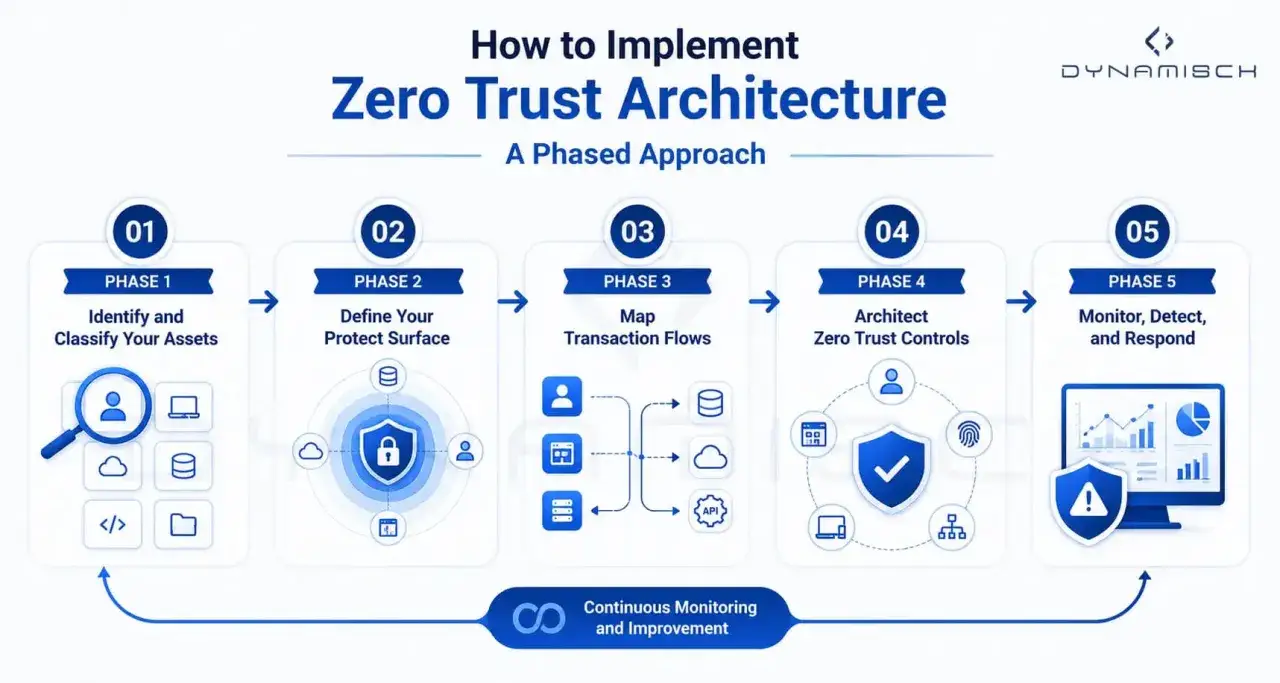
How to roll it out without a big-bang rewrite
The cleanest approach is incremental. I would start with the highest-value workloads, tighten identity and policy around them, and only then expand the model into lower-risk or legacy areas. The fastest projects are rarely the most successful ones, because zero trust usually fails when teams try to modernise every control at once.
- Map the resources that matter most, including critical data, privileged applications, admin paths, and third-party access.
- Clean up identity first with MFA, lifecycle controls, service account governance, and device enrollment.
- Define the policy inputs you will actually trust, such as user role, device posture, location, network signal, and data sensitivity.
- Enforce least privilege at the edge of the resource, not at the edge of the entire network.
- Pilot one workload, measure failure modes, and then widen coverage only after the policy is stable.
- Use a mixed-estate pattern for legacy systems that cannot move yet, so access stays available while implicit trust is reduced elsewhere.
For cloud-native applications, later guidance from the same ecosystem goes further into API gateways, sidecar proxies, and workload identity. That matters because zero trust eventually reaches the service mesh and deployment pipeline, not just the firewall. If your application teams are not part of the conversation, the architecture will stall at the edge.
When that sequence is ignored, the programme usually starts with tools instead of decisions, which is where most disappointment comes from.
Where zero trust programmes usually fail
The most common failure mode is simple: a team buys a ZTNA product and declares victory. That can improve access control, but it does not automatically create a zero trust architecture. The model is broader than remote access, and it only works when identity, policy, telemetry, and resource-level enforcement move together.
- They focus only on employees and forget service identities, machine accounts, and automation.
- They leave legacy exceptions unmanaged, which quietly recreates the old perimeter.
- They collect telemetry but never turn it into policy changes.
- They overcomplicate the design before proving value on one workload.
- They try to make zero trust feel exactly like the old network, which defeats the point of the change.
The other recurring mistake is treating the model as a one-time project. It is closer to an operating approach. Trust should be narrower, access should be more explicit, and monitoring should be better at exposing drift. If those three things are not improving, the architecture is probably cosmetic.
That discipline is exactly what makes the approach relevant for long-lived estates, not just cloud-native ones.
What UK organisations should take from this in 2026
The UK context is practical rather than ideological. Current UK guidance frames zero trust as removing inherent trust from systems, networks, and services, and its design principles are aimed at both public and private sector teams that need to make mixed estates work. The emphasis is on knowing your architecture, knowing identities, assessing behaviour and health, authorising by policy, authenticating everywhere, monitoring users and services, and refusing to trust any network by default.
The useful 2026 nuance is that the guidance is comfortable with imperfect estates. Not every system can be moved at the same speed, and some cannot be moved cleanly at all. That is why mixed-estate patterns exist. They let organisations preserve security benefits while still supporting older applications, unusual operating constraints, or tightly coupled dependencies.
Later NIST material also shows how the concept keeps maturing. The ecosystem now includes 19 example architectures and follow-on guidance for cloud-native, multi-cloud environments, which is a strong signal that the original paper is a foundation rather than a finished implementation manual. For UK buyers and security leaders, that means procurement should ask about identity, telemetry, policy integration, and legacy handling, not just whether a product uses zero trust language.
Once that lens is in place, the final step is deciding how to start without making the programme harder than it needs to be.
The shortest sensible next move for a security team
If I were starting from scratch, I would pick one high-value application, one identity gap, and one monitoring stream, then prove that access can be narrowed without breaking operations. That gives you a real control loop instead of a slide deck.
- Choose one application that contains sensitive data or privileged access.
- Define who should access it, from where, and on what kind of device.
- Fix the weakest identity or posture control that currently grants broad access.
- Decide now how unsupported or unmappable systems will be handled later.
That is the shortest path from theory to practice. Zero trust becomes useful when it reduces unnecessary trust, improves visibility, and gives you narrower access decisions that still let the business run. If a programme delivers those three outcomes, it is working in the spirit of the standard rather than just borrowing its terminology.