The practical takeaway for cloud teams
- Think in a control loop: prevent, detect, remediate, verify.
- Start with identity, public exposure, secrets, logging, and infrastructure-as-code checks.
- CSPM and CNAPP improve visibility, but they do not replace good cloud design.
- For UK teams, government cloud guidance and Cyber Essentials are a sensible baseline.
- Keep human approval for high-risk production changes and low-confidence findings.
What automated cloud security really means in practice
I treat this as a governed feedback loop rather than a product category. The point is to let systems enforce the routine parts of security while people define policy, approve exceptions, and handle incidents that need judgment. Policy as code is the backbone of that model: security rules are written in version-controlled files, tested like software, and deployed through the same release process as the rest of the stack.
That changes the shape of the work. Instead of asking engineers to remember dozens of manual checks, you make the safe path the default path. Infrastructure-as-code stops risky configuration from being created by hand, posture tools catch drift, and response automation handles the small, repeatable tasks such as revoking access, opening tickets, or isolating a workload. Once that is clear, the next question is why manual processes fail so quickly in cloud estates.
Why manual controls break down so quickly
Cloud environments move too fast for spreadsheet-style governance. New accounts, containers, functions, buckets, and service connections can appear in minutes, and they can disappear just as quickly. A human review queue cannot keep up with that pace, especially when one bad template can be copied across multiple regions, teams, or environments.
The other problem is inconsistency. Manual checks depend on who is on shift, how tired they are, and whether the situation looks familiar. That is exactly where misconfigurations creep in: public exposure, overbroad permissions, untagged resources, weak secrets handling, and logs that never get enabled. I also care about the shared responsibility model here. Your provider secures the platform, but your team still owns most of the configuration, identity, and data decisions that actually create risk. That is why the control model has to move from review-based to continuously enforced.
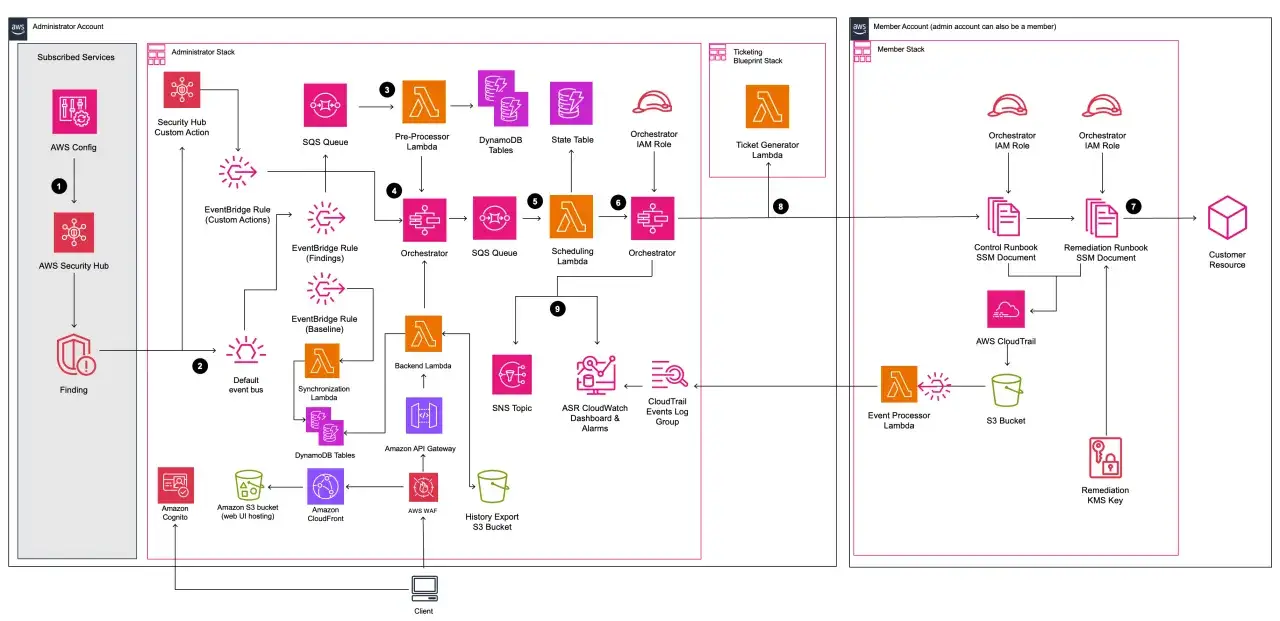
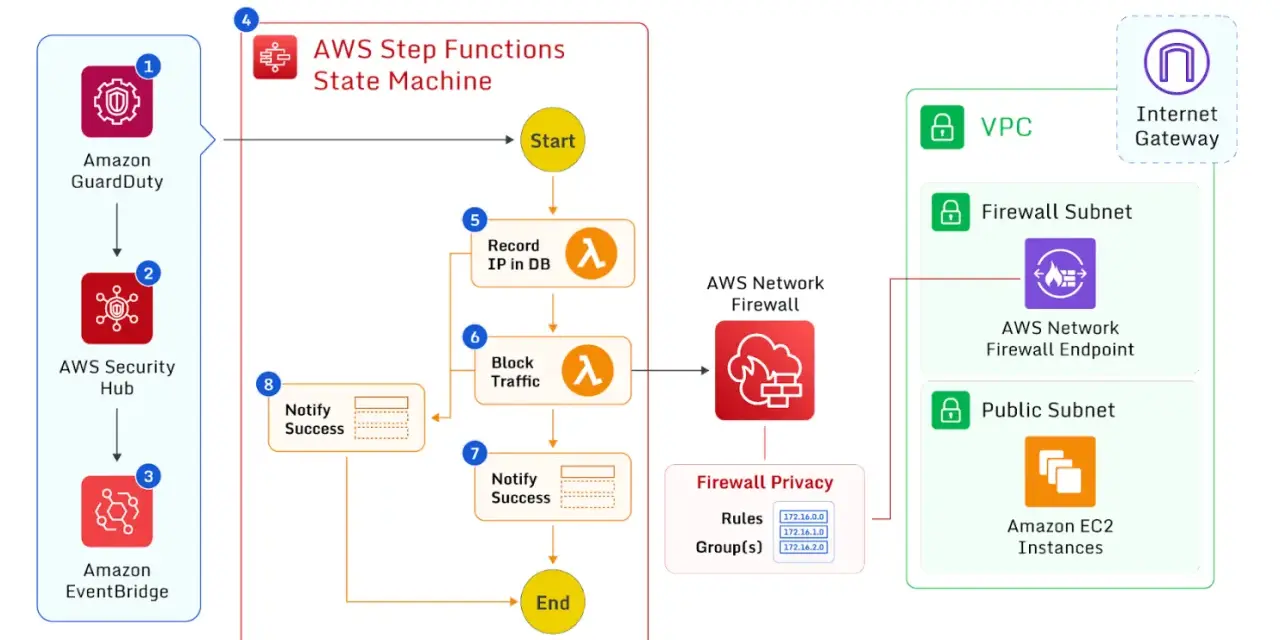
How the control stack should fit together
I usually split the stack into four layers. Before deployment, infrastructure-as-code scanning and policy checks catch mistakes before they reach production. After deployment, CSPM tools watch for drift, exposed services, missing tags, and weak settings. At runtime, workload protection covers containers, virtual machines, and serverless functions. Across the whole estate, identity, logging, and orchestration tie the signals together so the security team can react without rebuilding the same context every time.
CSPM is the posture layer: it continuously checks whether cloud resources match the policy you expect. CNAPP is broader; it tries to combine posture, workload, identity, and data signals into one operating plane. That can be useful, but it still needs disciplined workflow design. The NCSC is right to treat posture management as one piece of the puzzle, not a silver bullet. If the tool does not connect cleanly to your CI/CD pipeline, ticketing, and incident response process, you just create a faster stream of noise.
There are two details I would not ignore. First, workloads and automation should use service identities, not borrowed human accounts. A service identity is a machine identity with narrowly scoped permissions, and each automation path should have its own one. Second, observability only works when logs are useful, retained, and protected from tampering. If you cannot answer who changed what, when, and from where, the rest of the stack is weaker than it looks.
The controls I would automate first
If I had to prioritise a new programme, I would start with the controls that stop the most common and most expensive mistakes. These are the ones that tend to pay for themselves quickly because they reduce both breach risk and operational churn.
| Control area | What to automate | Why it matters | Where humans still intervene |
|---|---|---|---|
| Identity and access | MFA enforcement, least-privilege reviews, privileged role checks, service identities | Limits account takeover and privilege creep | Break-glass approval, unusual admin changes, exception handling |
| Public exposure | Block public storage, open security groups, exposed APIs, weak ingress rules | Prevents the most obvious data and service leaks | Intentional public endpoints and architecture exceptions |
| Secrets | Managed vault storage, rotation, secret scanning, exposure alerts | Reduces blast radius when code or pipelines leak credentials | Secret lifecycle exceptions and emergency rotation |
| Logging and tagging | Immutable logs, retention rules, mandatory owner tags, tag validation | Improves traceability, ownership, and incident response | Tag taxonomy changes and retention overrides |
| Configuration drift | Compare live resources to IaC templates and flag or block drift | Keeps production aligned with reviewed configuration | Emergency hotfixes and time-limited deviations |
If budget or time is tight, I would still start with identity, exposure, and secrets. Those three areas create the fastest risk reduction with the least debate. After that, the tooling question becomes easier to answer.
Choosing tools without buying noise
Cloud security tools are easiest to choose when you know what problem each one solves. Native cloud guardrails are best for immediate enforcement inside one provider. CSPM is strongest at inventory, posture, and drift. CNAPP is useful when you want a broader view across posture and workload signals. SIEM and SOAR are for correlation and response. Policy as code is the discipline that makes the whole thing repeatable.
| Tool or approach | Best at | Weak spot | Use it when |
|---|---|---|---|
| Native cloud guardrails | Provider-integrated prevention and audit | Usually limited to one ecosystem | You need low-latency policy enforcement close to the platform |
| CSPM | Continuous posture monitoring and misconfiguration detection | Can become an alert factory without prioritisation | You need broad visibility across a changing estate |
| CNAPP | Unified context across posture, workloads, identity, and data | Can be complex to deploy and govern | You want one operating layer across many cloud services |
| SIEM / SOAR | Event correlation, investigation, and response automation | Only as good as the data and playbooks behind it | You need cross-domain detection and response |
| Policy as code | Versioned, testable governance rules | Does not replace runtime visibility | You want security decisions reviewed like software |
My bias is simple: use native guardrails first, then add a posture layer, then connect it to response workflows. Buying a platform before you know where the alerts will land usually just moves the chaos somewhere more expensive. The bigger risk is not missing a shiny feature; it is building an automation stack that nobody trusts enough to use.
Where automated controls tend to fail
Automation is only safe when it is narrow, observable, and reversible. The usual failures are predictable:
- False positives are high, so teams start bypassing the control.
- Automation has too many permissions and becomes a new attack path.
- Tags are treated as truth even when nobody validates them.
- Policies stay static while the cloud platform keeps changing.
- Production changes are remediated directly instead of through IaC.
I also see teams overuse hard blocks. If a control cannot distinguish between routine activity and risky activity, it should usually alert first and block only when the signal is reliable. That is especially true for production. In production, I prefer updates to flow through IaC templates so the fix is repeatable. In development, limited auto-remediation can be acceptable because the blast radius is smaller and experimentation matters more.
There is also a human issue that does not get enough attention: exception debt. Every temporary bypass becomes a policy exception that someone has to remember later. If you do not review those exceptions, the automation layer quietly degrades into a set of suggestions. That is why break-glass access should be rare, logged, and time-bound rather than a standing shortcut.
What I would ship first in a UK cloud estate
For UK organisations, I would anchor the programme in government cloud guidance and use Cyber Essentials as the floor, not the finish line. The UK baseline matters because it pushes teams toward practical controls rather than vague assurances. It also keeps attention on the basics that break most often: authentication, configuration, access control, malware resistance, and patching.- Map workloads to data sensitivity, ownership, and jurisdiction requirements.
- Turn on provider-native guardrails for public exposure, encryption, and identity abuse.
- Enforce logging, retention, and ownership tags from day one.
- Put policy-as-code checks into CI/CD so bad configuration fails before deployment.
- Use managed service identities and secrets management instead of raw passwords and shared keys.
- Test recovery by rebuilding at least one environment from backed-up IaC and restoring the data it depends on.
The UK-specific part is not just compliance theatre. Jurisdiction, auditability, and retention all matter, but none of them replace good engineering. If the data is encrypted, access is narrow, logs are trustworthy, and recovery is tested, you have a real security posture. If those pieces are missing, a local-storage promise does very little on its own.
The operating model that keeps paying off
The setups that age well are usually the least dramatic. They rely on narrow identities, visible inventories, trusted logs, and automation that either blocks low-risk drift or raises high-signal alerts. They do not try to make every decision automatic. They try to make the routine decisions boring.
That is the real value of cloud security automation: it keeps people focused on architecture, exceptions, and incident decisions instead of repeated hygiene checks. When the controls are designed well, the cloud becomes easier to govern as it grows, not harder. That is the standard I would use before I trusted any automated cloud security programme to run at scale.