Keeping a cloud-hosted application healthy is not just about knowing whether it is up. cloud based application monitoring should tell you quickly whether users are feeling the pain, where the fault sits, and whether the fix belongs in code, infrastructure, or configuration. In this article I break down the signals that matter, how to turn them into useful alerts, and what to watch when your stack spans multiple cloud services, regions, or teams.
What matters most before you scale the tooling
- Start with user impact, not with dashboards. If a metric does not help you answer “who is affected and why?”, it is probably noise.
- Track the core signals first: latency, traffic, errors, and saturation, then add logs, traces, synthetic checks, and real user data where they add context.
- Use traces to follow one request end to end, because cloud failures often sit between services rather than inside a single box.
- Alert on SLO breaches instead of every wobble. A page should mean real customer risk, not just an inconvenient spike.
- Prefer portable instrumentation such as OpenTelemetry when you want to avoid locking your telemetry to one backend.
- In the UK, treat retention and access control as design choices, not compliance afterthoughts, because monitoring data often includes sensitive operational detail.
What this kind of monitoring must answer first
I start with questions, not tools. Is the service available, is it slow, is the problem local or widespread, and did something change recently? If a monitoring setup cannot answer those in under a minute, it looks impressive but does not help during an incident.
That matters more in the cloud because failures are rarely neatly contained. An application may be healthy at the instance level while a database, identity provider, API gateway, queue, or downstream SaaS dependency is degrading. The user experiences one broken journey; the operator has to work backwards through several layers of infrastructure and code.
So I treat monitoring as an incident triage system. The point is to decide whether I should roll back a deploy, scale a service, fix a query, or escalate to a platform team. Once those answers are clear, the next step is choosing the signals that expose them fastest.
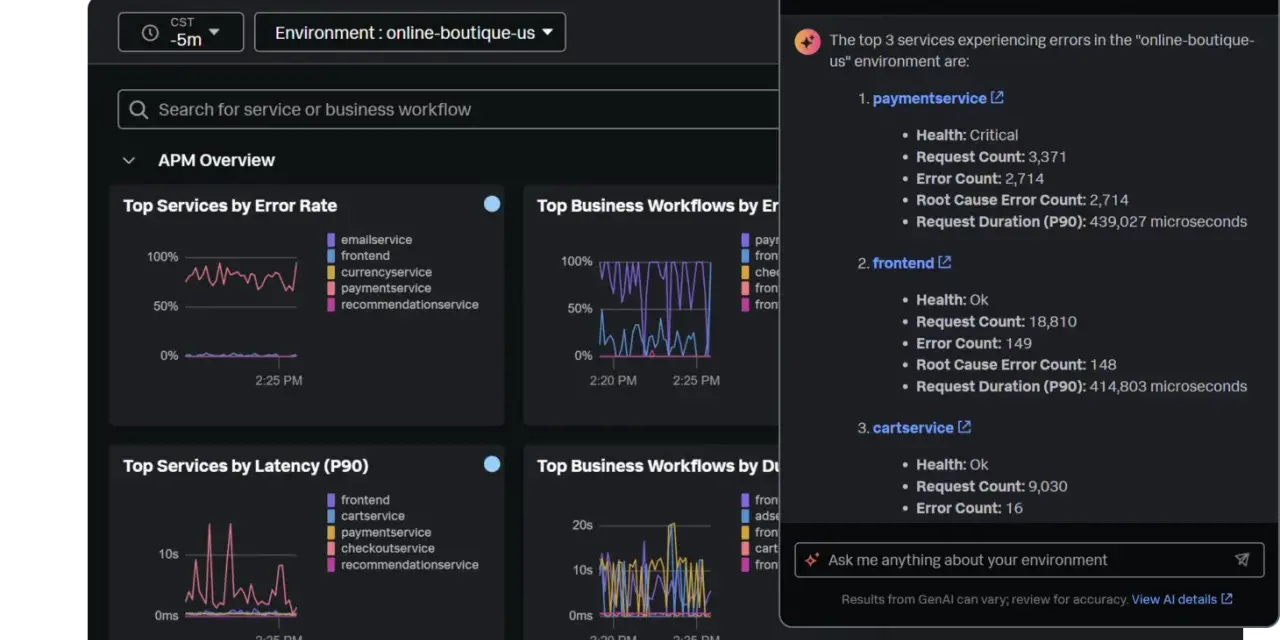
The signals that separate noise from real incidents
The strongest monitoring stacks use a small set of signals well. I still reach for the four golden signals first: latency, traffic, errors, and saturation. They map closely to what users feel and what the system can sustain. Around them, I layer logs, traces, synthetic checks, and real user monitoring when those extra views add something useful.
| Signal | What it tells you | Best use | Common mistake |
|---|---|---|---|
| Metrics | How the system behaves over time | Latency, error rate, request volume, queue depth, CPU, memory, database connections | Watching averages only and missing bad tail latency |
| Logs | What happened at a specific moment | Exceptions, auth failures, deployment events, feature flag changes | Logging too much text without structure or context |
| Traces | Where one request slowed down or failed | Distributed systems, microservices, checkout flows, API chains | Missing trace context between services, which breaks the story |
| Synthetic checks and real user monitoring | Whether people can actually complete important journeys | Login, search, payment, form submission, mobile app flows | Testing the wrong journey or only testing from one region |
I rarely trust averages on their own. A service can have a comfortable mean latency and still feel broken to a large slice of users. That is why p95 and p99 latency matter: they show the slow tail, not just the comfortable middle. For page-worthy alerts, I also prefer sustained breaches over single spikes; a threshold that stays wrong for 5 to 10 minutes is usually far more meaningful than one noisy minute.
Another useful distinction is between system health and business health. A healthy cluster does not automatically mean a healthy product. If checkout errors, sign-in failures, or API timeouts climb, the infrastructure may still look fine while revenue or trust is already slipping. That is the point where product-level metrics become part of observability, not a separate reporting layer.
Signals only help when they are connected to a workflow, which is why the setup matters as much as the data itself.
How to build a stack that stays useful in production
When I set up monitoring for a new cloud service, I move in a fixed order. First I instrument the application. Then I collect the telemetry centrally. After that I add alerting rules that reflect user impact, not internal panic. Finally, I wire in deploy markers and ownership metadata so incidents are easier to route.
Instrument the application itself
Use code-level instrumentation to emit traces, metrics, and structured logs. OpenTelemetry is a practical default because it keeps the data portable across back ends, which matters if the team changes tools later. Auto-instrumentation is helpful for coverage, but I would not rely on it alone; business-specific events and key user journeys usually need explicit spans or counters.
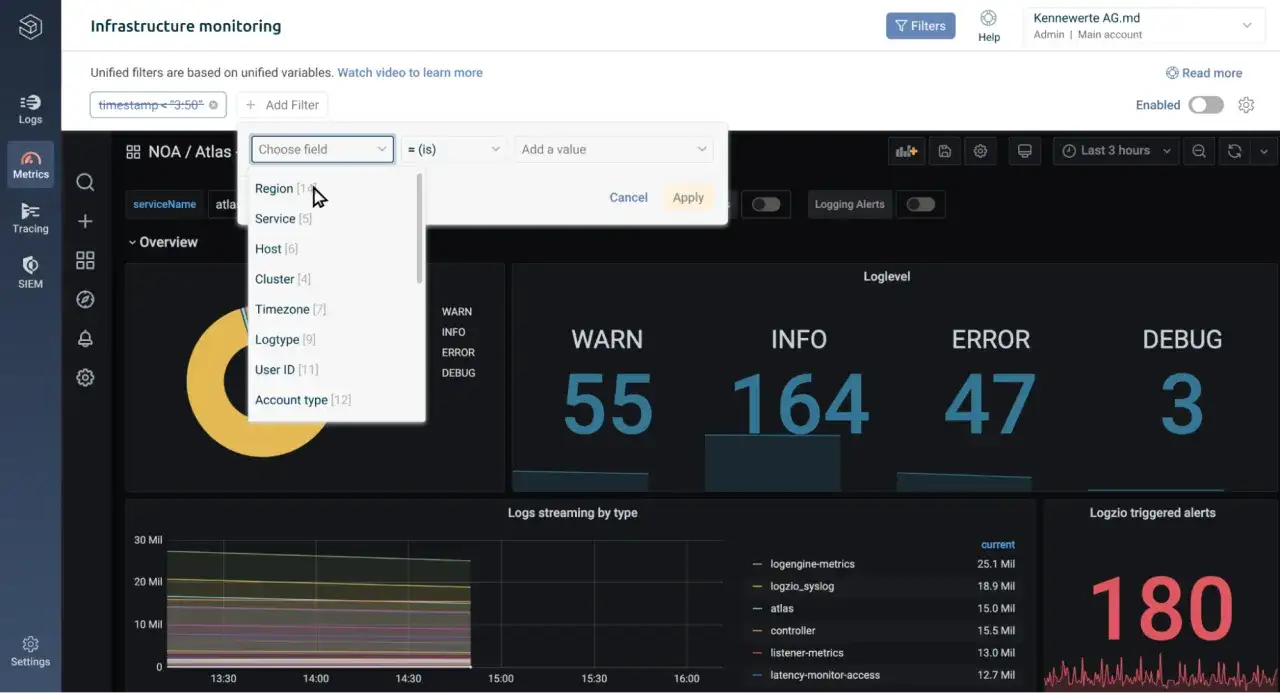
Collect and enrich telemetry centrally
Route signals through a collector or agent so you can filter, redact, sample, and enrich them before they hit long-term storage. This is where service names, environment labels, regions, request IDs, and deployment versions become genuinely useful. Without that metadata, even good telemetry turns into a search problem.
Alert on service-level objectives
I prefer alerts that are tied to service-level objectives, because they map much better to user experience than raw CPU or memory thresholds. A simple starting point is to page only when a customer-facing latency or error SLO stays outside the acceptable band for several minutes. For many teams, a monthly availability target of 99.9% still allows roughly 43 minutes of downtime, so the threshold has to be chosen deliberately, not borrowed from another organisation.
Read Also: Monitoring vs. Observability - What You Actually Need
Annotate deploys and changes
Most production mysteries become shorter once you can line up telemetry with deploys, config changes, scaling events, or feature-flag flips. I like to annotate those changes on the same timelines as the service graphs. It sounds small, but it often removes half the guesswork during an incident review.
That stack still has to fit a budget and an operating model, which is where platform choice starts to matter.
How to choose between managed, open source, and hybrid approaches
I usually frame the choice around control, speed, and long-term ownership. The right answer depends on whether the team wants a managed service with a lot of integration built in, a fully owned stack, or a vendor-neutral model that keeps exit options open.
| Approach | Strengths | Weaknesses | Best fit |
|---|---|---|---|
| Managed cloud suite | Fast to deploy, tightly integrated, less operational overhead | Can become expensive at scale and more opinionated over time | Teams that run mostly in one cloud and want speed over deep customisation |
| Open source stack | High control, portability, strong customisation options | You own upgrades, scaling, retention, and tuning | Platform teams with strong SRE or DevOps capability |
| Hybrid, vendor-neutral approach | Balanced portability and flexibility, easier migration later | Still needs integration work and good discipline | Multi-cloud, regulated, or fast-changing environments |
The cost trap is usually not the licence alone. Storage, indexing, retention, and high-cardinality labels can do more damage than the headline subscription fee. Cardinality simply means how many distinct values a field can take, and it matters because a metric with thousands of unique label combinations is harder and more expensive to query than a simple one. If the backend starts slowing down because every request is tagged too granularly, the observability system begins to fight the application instead of helping it.
I also look closely at trace sampling. At high traffic volumes, collecting every trace is often unnecessary, but sampling too aggressively can hide the very failures you are trying to understand. The best setup is the one that captures enough detail to explain incidents without turning telemetry into its own operational burden.
Once the platform is chosen, the next problem is not technology but habits.
Common mistakes that make cloud monitoring expensive and noisy
Most weak monitoring systems fail for the same reasons. They collect too much of the wrong thing, or they collect the right thing without enough context to make it actionable. I see a few patterns repeatedly.
- Watching averages only. Mean latency hides the slow tail, which is often where users feel the pain first.
- Alerting on every internal threshold. A CPU alert is not useful if customers are unaffected and the service has headroom elsewhere.
- Missing ownership metadata. If nobody knows which team owns a service or dependency, the alert becomes a routing problem.
- Logging everything at full volume. Verbose logs look comforting until storage costs, query times, and noise explode.
- Ignoring trace context. Without consistent request IDs or span links, distributed systems become guesswork.
- Treating dashboards as the end product. A dashboard that cannot guide action is just a wall of numbers.
Cardinality problems deserve special mention because they are easy to create and hard to unwind. A label such as customer ID, order number, or full URL path can multiply metric series very quickly. That inflates cost, slows queries, and can make a graph unreadable exactly when you need it most. I prefer to reserve high-cardinality fields for logs or traces, not for every metric.
The best defence against noisy monitoring is discipline: keep the signal set small, make the labels consistent, and only page when something has crossed the line from interesting to harmful. Those habits matter even more when the estate stretches across teams, clouds, and countries.
What UK teams should keep in mind
For UK teams, the technical challenge is usually similar to anywhere else, but the operating constraints are often more demanding. Monitoring data can cross public cloud, SaaS, and on-prem systems, so I pay close attention to where telemetry is stored, how long it is retained, and who can query it. That is especially important when logs, traces, or support notes may contain personal data or customer identifiers.
My practical advice is simple: mask sensitive fields early, keep access tightly scoped, and make retention a deliberate policy rather than a default. It is much easier to design for reduced exposure at ingestion time than to scrub an over-collected telemetry lake after the fact. That is not just a privacy issue; it also makes the data cleaner and easier to search during incidents.
UK organisations also tend to run a mix of cloud-native workloads and older platforms, so cross-environment visibility matters. I want one place that can show whether the slowdown sits in the internet path, the cloud region, an internal dependency, or a legacy system that still matters to the business. If the monitoring layer cannot bridge those worlds, the team ends up stitching together evidence manually, which wastes the most expensive minutes in an incident.
Finally, watch the operational rhythm. Alert routing, escalation windows, and dashboard annotations should reflect real working hours and on-call coverage, not an idealised team chart. A technically correct alert that lands with the wrong person at the wrong time is still a bad alert.
The baseline I would start with on a new cloud app
If I were starting from scratch, I would keep the first version intentionally small. I would instrument one critical user journey with traces and structured logs, collect the four golden metrics, and define one customer-facing SLO. After that, I would add synthetic checks for the main path and, if the product has a browser or mobile interface, real user monitoring for the journeys that matter most.
Only then would I widen the scope to dependency dashboards, business metrics, and more detailed environment views. That order keeps the system understandable and honest. It also makes it easier to see when a metric is genuinely useful rather than merely available.
If there is one rule I would keep, it is this: build the monitoring layer so it shortens the path from symptom to decision. When it does that consistently, the stack becomes valuable; when it does not, it is just another bill and another tab open during an incident.