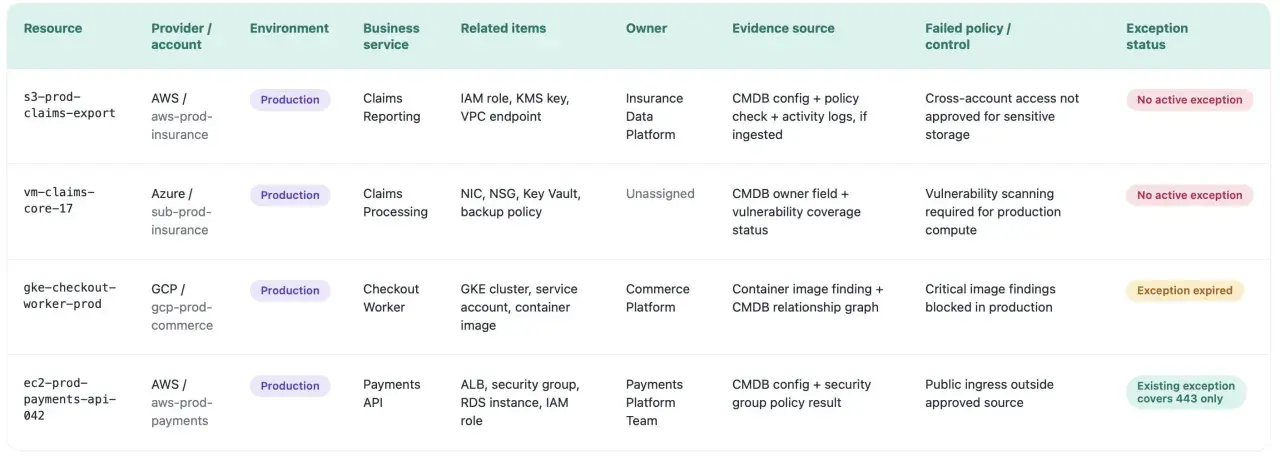
A cloud security checklist is only useful when it turns cloud risk into concrete checks: identity, exposure, encryption, logging, recovery, and the evidence that each control is actually working. In practice, the failures I see most often are not exotic; they are misconfigured access, overly open network paths, and weak visibility when something changes. For UK teams, I usually treat the NCSC cloud principles as the baseline and the ICO’s information and cyber security toolkit as the accountability lens.
Verify ownership, exposure, and proof before anything else
- Identity and access usually decide the real blast radius, not the brand of cloud platform.
- The UK NCSC’s 14 cloud security principles are a solid provider-evaluation baseline for larger organisations and public sector teams.
- Encryption matters, but only if you also know who controls the keys and how deletion really works.
- Logs, alerts, backups, and restore tests are the difference between a secure design and a hopeful one.
- Shared responsibility is not a slogan; it is the first thing that needs to be mapped before any hardening work starts.
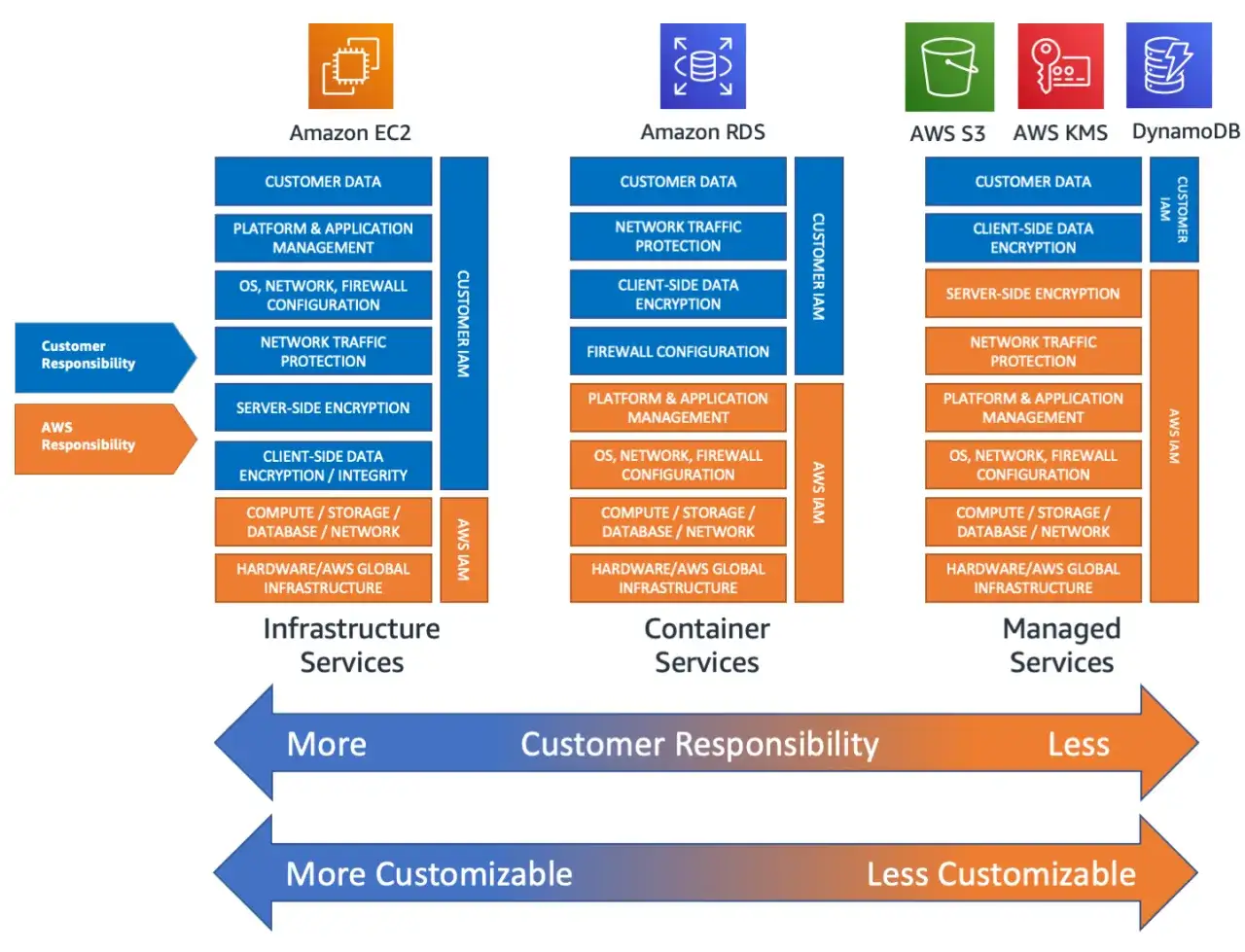
Start with the shared responsibility model
I always begin here because cloud security gets messy when nobody can answer a simple question: who owns what? SaaS, PaaS, and IaaS all shift responsibility in different ways, and a control that is critical in one model may be largely the provider’s job in another. The more managed the service, the less patching you own, but the more important configuration, identity, and data governance become.
| Cloud model | Provider usually handles | You still need to verify |
|---|---|---|
| SaaS | Application uptime, platform patching, core infrastructure | User access, sharing settings, retention, integrations, audit logs, data export and deletion |
| PaaS | Runtime, managed services, much of the patching burden | Application code, secrets, permissions, network exposure, logging, deployment controls |
| IaaS | Physical security, host infrastructure, hypervisor layer | OS hardening, patching, firewall rules, backups, monitoring, IAM, workload segmentation |
In my view, this is where many teams get cloud security backwards: they spend time choosing a platform before they know which controls are actually theirs. If that ownership map is unclear, every later check becomes fuzzy too. Once I know who owns each control, I move straight to identity, because that is where most cloud incidents start.
Verify identity and access before anything else
If I can only review one area, it is access. A cloud environment with strong encryption but weak identity controls is still easy to misuse. Most damage comes from excessive permissions, stale accounts, and admin paths that were never tightened after launch.
- Enforce single sign-on and MFA for every administrative account and every high-risk user path.
- Separate human identities from machine identities; service accounts should not look like spare human users.
- Use role-based access with least privilege, and review privileged roles on a monthly or quarterly cadence depending on risk.
- Eliminate shared admin accounts and long-lived access keys wherever possible.
- Use short-lived tokens or federated workload identities for automation instead of static secrets that linger in code or scripts.
- Create break-glass accounts, store them securely, and test them; emergency access that has never been tested is not reliable.
MFA is non-negotiable for console and privileged access. So is a clear process for joining, changing, and leaving roles, because cloud permissions tend to accumulate quietly. If an account can reach production with old credentials or vague approval logic, the control set is not finished. With identity under control, the next question is whether the data itself is protected well enough to survive a mistake.
Check data protection, encryption, and key control
This is where cloud projects often sound secure on paper and then get vague in practice. I want to know what data exists, where it lives, how it is encrypted, who can decrypt it, and how long it actually sticks around. If the answer is different for primary data, backups, snapshots, and replicas, that needs to be explicit.
- Classify data by sensitivity first, not by convenience. Public, internal, confidential, and regulated data do not deserve the same treatment.
- Encrypt data in transit with modern TLS and enforce it consistently across apps, APIs, admin consoles, and service-to-service traffic.
- Encrypt data at rest for databases, object storage, file shares, backups, and snapshots.
- Decide whether provider-managed keys are enough or whether customer-managed keys are needed for higher-risk workloads.
- Separate key administration from data administration where the risk justifies it.
- Define retention, deletion, and secure erasure rules for live data, backups, and logs.
- Keep secrets out of source code, tickets, and chat logs; put them in a vault or a managed secrets service.
For UK workloads, data residency is worth checking, but I do not treat it as a magic answer. What matters is the full path: where the data is processed, where backups go, how subprocessors behave, and how deletion is handled when a record should no longer exist. If a provider cannot explain how a delete request affects replicas, archives, and backups, the story is incomplete. After data, the next weak point is the path in and out of the environment.
Reduce exposure on the network and external interfaces
Cloud platforms fail loudly when people leave too much open: public storage, broad security groups, admin consoles exposed to the internet, or APIs with no real rate limiting. I look at external exposure as a shrinking exercise. Every internet-facing asset must earn its place.
- Close public admin ports unless there is a documented exception with an expiry date.
- Use private endpoints or private links for databases, storage, and internal services where possible.
- Protect public APIs with authentication, rate limiting, a gateway, and where relevant a web application firewall.
- Separate production, development, and test environments so a compromise in one does not easily spill into the others.
- Review security groups, network policies, and firewall rules after every meaningful deployment change.
- Document every internet-facing service and recheck the list against reality, not just the architecture diagram.
Zero trust sounds abstract until you apply it here: never assume a request is safe just because it comes from inside the cloud. Verify it, constrain it, and log it. Once the attack surface is narrowed, I care most about whether the environment can detect and recover from trouble.
Make logging, alerting, backups, and recovery testable
Security claims are cheap; evidence is what matters. I do not count a control as live until I can see its logs, receive its alerts, and prove I can restore what matters. A backup that has never been restored is an assumption, not a recovery plan.
| Control | What I verify | Good sign |
|---|---|---|
| Logging | Admin actions, authentication events, network changes, key events, and data access are captured centrally | Logs flow to a SIEM or immutable store, and retention matches the risk |
| Alerting | High-risk events such as privilege escalation, public exposure, and key changes trigger real notifications | Alerts reach a human fast enough to act, not just a dashboard nobody watches |
| Backups | Backups are encrypted, isolated, and cover the data plus the configuration needed to rebuild it | Backups are protected from deletion and ransomware-style tampering |
| Recovery | Recovery point objective and recovery time objective are defined for critical systems | Restore tests and failover exercises are run on a schedule |
RPO tells you how much data loss is acceptable; RTO tells you how long the business can tolerate being down. Those numbers should be written down for the systems that matter most, not guessed during an incident. In my practice, quarterly restore tests for critical services are a sensible floor, and anything customer-facing deserves a recovery drill that includes people, process, and tooling. That brings the technical checks into the wider organisational picture, where provider evidence and contracts start to matter.
Review the provider and the contract, not just the console
In the UK, cloud due diligence is not only technical. The supplier, the contract, and the evidence pack all matter, especially when personal data or regulated workloads are involved. The NCSC’s cloud guidance is useful precisely because it separates choosing a provider from using the service securely, and that distinction is still valid in 2026.
- Ask for assurance evidence that matches the service and the sensitivity of the data.
- Check how provider staff access is controlled, logged, and constrained.
- Review subcontractors and supply chain dependencies, not just the headline vendor.
- Confirm incident notification expectations, support escalation, and breach handling procedures.
- Make data export, deletion, and exit support part of the contract, not an afterthought.
- If UK GDPR applies, verify that accountability, retention, and international transfer obligations are mapped into the operating model.
The ICO’s toolkit is useful here because it pushes the conversation beyond security controls into accountability, training, and breach management. I also like to see how a provider aligns with baseline hardening guidance such as CIS Foundations Benchmarks, because those baselines harden identity, logging, and networking in ways that are easy to compare across major cloud platforms. Once the provider story is clear, the final gap is usually human error and process drift.
The mistakes that keep showing up in cloud reviews
Most cloud failures are boring in the worst possible way. They repeat because teams are busy, not because the problems are subtle. These are the mistakes I keep seeing:
- Assuming defaults are secure when the default is really just convenient.
- Granting broad permissions early and never tightening them later.
- Leaving backups in the same trust zone as production, which makes recovery fragile.
- Turning on logging without monitoring it, which creates noise instead of defence.
- Storing secrets in code or chat and then treating the environment as hardened.
- Using CSPM as a substitute for ownership; cloud security posture management is useful for drift detection, but it does not replace people, process, or testing.
There is a pattern in all of those failures: the control existed on paper, but nobody could prove it was being used well. The cleanest way to avoid that is to turn the review into a recurring operational habit.
Make the review part of release and operations
The best cloud teams do not treat security as a one-time hardening project. They fold it into onboarding, releases, and routine operations so drift gets caught early. I prefer a simple cadence because complicated schedules tend to die under pressure.
| When | Re-check |
|---|---|
| Before go-live | Identity, public exposure, encryption, logging, backups, and contract terms |
| After any major change | All controls touched by the change, plus the alerting path |
| Weekly | New public assets, privilege changes, failed logins, and unusual outbound traffic |
| Monthly | Access reviews, secrets hygiene, configuration drift, and unresolved high-severity alerts |
| Quarterly | Restore tests, incident drills, supplier review, and any exception that is about to expire |
If I had to reduce the whole exercise to one rule, it is this: every cloud control should have a named owner, a measurable state, and a test you can run without guessing. That is what turns cloud security from a paper exercise into an operating discipline, and it is what makes the environment safer over time rather than just quieter after a review.