
A modern network is the layer that makes offices, cloud services, remote staff, and security tools behave like one system instead of a pile of separate products. The practical side of infrastructure and networking is less about jargon and more about latency, resilience, access control, and how quickly you can recover when something fails. In this article I break down the pieces that matter, how to design them sensibly for a UK organisation, and where the common failure points usually hide.
The essentials of a resilient network stack
- Network infrastructure is both physical and logical: cables, switches, firewalls, routing, DNS, identity, and monitoring all matter.
- Segmentation and least privilege usually reduce risk more than buying heavier hardware.
- Remote access should match the estate: VPNs still fit legacy on-premises environments, while zero trust suits cloud-heavy ones.
- Cloud networking works best when it is defined as code, reviewed like software, and observed through logs.
- In the UK, the basics map closely to Cyber Essentials: firewalls, secure configuration, updates, access control, and malware protection.
- Resilience comes from testing failure, not just adding backup links and hoping they behave.
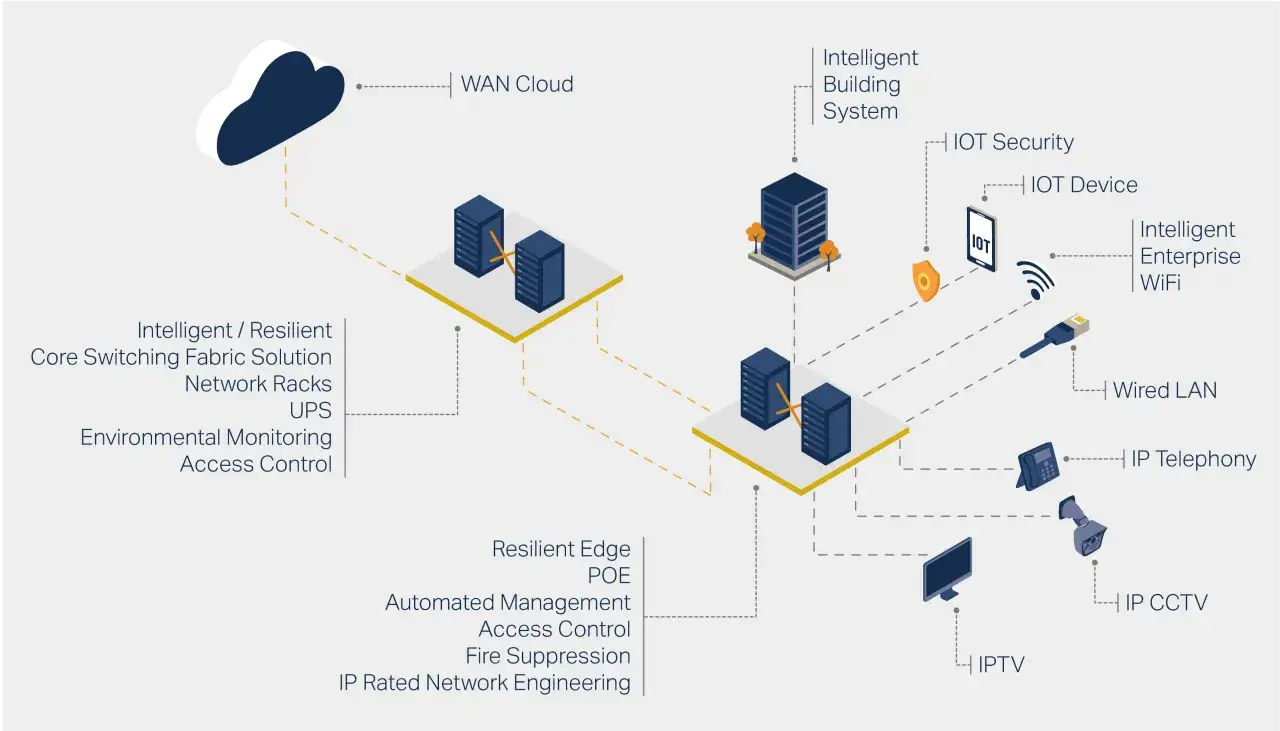
What network infrastructure actually includes
When I review a network, I do not start with brands or purchase lists. I start with the moving parts that determine whether traffic gets where it needs to go safely and predictably. That means the physical layer, the logical layer, and the security controls sitting in between.
Physical components
These are the parts people see first: switches, routers, wireless access points, firewalls, cabling, racks, power protection, and the internet circuits that connect a site to the outside world. In a typical office, the difference between a tidy setup and a painful one is often a handful of decisions such as whether the cabling is labelled, whether the switches have spare capacity, and whether the network can survive the loss of a single device without grinding to a halt.
I also treat cabling and power as part of resilience, not an afterthought. A neat comms cabinet with proper patching, UPS-backed core devices, and clearly separated uplinks will save more time during an incident than another dashboard ever will.
Read Also: Mobile Network Optimization - Fix Your Network's Real Problems
Logical services
The invisible layer matters just as much. IP addressing, DNS, DHCP, VLANs, routing tables, firewall rules, authentication, VPNs, and monitoring are what give the physical kit its actual behaviour. If DNS breaks, users often describe it as “the internet is down” even when the real issue is only name resolution. If routing is wrong, traffic may be technically connected but functionally useless.
The parts that matter most are usually the ones that fail quietly: routing, DNS, authentication, and monitoring. That is why I prefer to document those dependencies before I touch hardware or redesign a site.
Once you can see the components clearly, the next step is deciding how they should be arranged so that a failure stays local instead of becoming everyone’s problem.
Design the layout around traffic patterns, not device count
A network should follow business flows, not the inventory list. If finance users, guest devices, engineering systems, and administrative tools all sit in one flat domain, you get a simple design that is deceptively expensive the moment something goes wrong. The better question is not “How many switches do we need?” It is “Which traffic should be allowed to reach which systems, and why?”
The UK's NCSC is blunt on this point: security and resilience need to be designed in from the start, because retrofitting them later drives up complexity and cost. I see that play out constantly in estates where growth outpaced architecture.
| Model | Best fit | Strength | Trade-off |
|---|---|---|---|
| Flat network | Very small, isolated environments | Simple to deploy and cheap to start | Poor containment and weak control over lateral movement |
| Segmented network | Most SMEs and multi-site organisations | Limits blast radius and clarifies policy boundaries | Needs disciplined rule management and documentation |
| Identity-led access | Cloud-heavy or remote-first estates | Reduces implicit trust and fits distributed work | Depends on mature identity, device posture, and policy design |
My default for a mixed estate is segmentation first, then tighter identity-based controls where the business is ready for them. I would rather manage a few clearly separated zones than one large, fragile network with a long list of exceptions. That matters even more when management interfaces, backup systems, and admin tools are in the same trust boundary as ordinary user traffic.
In practice, that means separating user, server, guest, and management traffic; keeping admin access off the general user network; and treating DNS and identity services as critical dependencies rather than background utilities. The next question is how people get in from outside the building without weakening all of that work.Choose remote access that matches the estate
Remote access is where many networks quietly become more dangerous than they look. A VPN can be a sensible control, but it is not a universal answer, and it is not automatically “modern” or “secure” just because it exists. The right choice depends on how much the business still relies on on-premises services, how identity is managed, and how much trust you are prepared to place in the endpoint.
For legacy or mixed environments, a well-designed VPN still has value. For cloud-first organisations, zero trust usually fits better because each request is checked against policy rather than being granted broad network access after one successful login. Hybrids are common, and they are often the realistic answer during transition.
| Approach | Best for | Strength | Weakness |
|---|---|---|---|
| VPN | Legacy apps, internal file shares, on-premises services | Good for secure connectivity across untrusted networks | Can become a single point of failure and adds operational maintenance |
| Zero trust | Cloud-heavy, identity-driven environments | Verifies each access request and reduces implicit trust | Needs mature identity, device health checks, and policy design |
| Hybrid | Organisations in transition | Lets you support legacy needs while moving towards tighter access | Can become messy if rules and ownership are not documented |
My rule of thumb is straightforward. If the business still depends on internal services that were never built for internet exposure, a VPN can still be the right bridge. If the estate is already distributed and cloud-centric, a zero trust pattern is often cleaner and easier to defend. Either way, remote access should be a deliberate architecture decision, not a convenience feature.
Once that access model is set, the focus shifts to the cloud and hybrid pieces that make the network more modular, but also more abstract.
Cloud and hybrid networks need different disciplines
In the cloud, the network is still a network, but you build and operate it differently. Instead of racking devices and patching cables, you define boundaries, routes, gateways, and policies in software. That is why I treat infrastructure as code as a networking practice, not just a DevOps trend.
Using code to define network changes makes the environment more repeatable, easier to review, and less prone to one-off mistakes. It also forces a better conversation about ownership. If a change matters enough to affect routing or access, it matters enough to be versioned, tested, and rolled back cleanly.
- Subnets separate workloads by function or trust level.
- Route tables decide where packets are allowed to go.
- Gateways and endpoints control how cloud resources reach the internet or private services.
- Peering and transit hubs keep multi-network estates manageable.
- Flow logs and traffic mirroring give you visibility when something behaves unexpectedly.
I also prefer to keep cloud networking modular. One large, tangled design is hard to reason about and even harder to secure. Smaller building blocks, with clear guardrails and templates, are easier to operate and safer to scale. In AWS terms, that is the logic behind a VPC with subnets, route tables, private endpoints, and logging; the same idea exists in Azure and Google Cloud even if the naming changes.
For hybrid estates, I pay close attention to the links between the old and the new: VPNs, private circuits, DNS forwarding, identity integration, and failover behaviour. Those edges are where outages and exposure usually happen, so the next layer to get right is security and operational discipline.
Security and resilience are built on maintenance
A network that is architecturally sound can still fail if it is not maintained. Updates, configuration drift, weak credentials, and poor visibility are what turn a good design into an incident report. For a UK organisation, this is also where the practical side of Cyber Essentials becomes useful rather than ceremonial.
The five controls are simple to name and annoyingly easy to neglect: firewalls, secure configuration, security updates, user access control, and malware protection. Each one has to show up in the network itself, not just in policy documents.
| Control | What it should do in practice | Common mistake |
|---|---|---|
| Firewalls | Allow only the traffic the business actually needs | Leaving broad rules in place because they are “temporary” |
| Secure configuration | Disable default accounts, unused services, and weak settings | Assuming factory defaults are acceptable in production |
| Security updates | Apply patches quickly, ideally on a default-update basis | Waiting until the next maintenance window becomes the next quarter |
| User access control | Give people and systems only the access they need | Using shared admin accounts because they are easier to remember |
| Malware protection | Reduce the chance that one compromised endpoint spreads into the network | Treating endpoint security as separate from network security |
Beyond the core controls, I want three operational habits in place. First, keep good logs and make sure someone can actually use them during an incident. Second, back up device configurations so you can rebuild quickly. Third, separate management access from ordinary user traffic, especially for critical switches, firewalls, and wireless controllers. A small out-of-band management path can save hours when the main network is damaged.
Maintenance is what turns a nice diagram into something the business can rely on, and that brings me to the checks I would run before signing off any redesign.
The sign-off checks I would not skip before a go-live
I do not consider a network finished until I have tested how it fails. That sounds harsh, but it is the fastest way to find the assumptions that were never written down. A redesign can look elegant on paper and still collapse under a routine fault if no one has challenged the weak points.
- Pull one link or one device and confirm that the service degrades gracefully instead of disappearing.
- Check management access separately from user traffic so administrators are not blocked by the very outage they need to fix.
- Trace the critical dependencies for DNS, identity, authentication, and internet breakout.
- Verify firewall rules against a real business requirement, not a copied template.
- Restore from a configuration backup and prove that the process works under pressure.
- Validate alerts and logs so the right people hear about the right problem quickly.
I also like to ask one final question: if this site lost a switch, a circuit, or an internet-facing service, would the team know within minutes, or would users have to report the failure first? If the answer depends on luck, the design is not ready yet.
The strongest networks are not the ones with the most hardware. They are the ones that make access predictable, contain faults cleanly, and stay observable when things go wrong. If you build around that idea, the rest of the stack becomes much easier to reason about and much harder to break.