Key points at a glance
- The internet is a layered system that provides naming, routing, interconnection, and transport rather than a single service.
- DNS and BGP are the control plane; fibre, routers, cables, and data centres are the physical layer that carries the traffic.
- Subsea cables are central to UK connectivity, so resilience depends on route diversity, landing-site diversity, and strong failover planning.
- Peering, transit, and CDN caching decide whether traffic stays local or travels farther than it needs to.
- Security is not only an endpoint problem; route validation, DNS protection, and monitoring are part of infrastructure hygiene.
- Good network design is measured by recovery time, route diversity, and observability, not by uptime claims alone.
What the internet actually provides
The simplest way I can frame it is this: the internet provides foundational network services that let independently run networks talk to each other at scale. That includes naming, addressing, routing, traffic exchange, and delivery. The visible web is only one service riding on top of that foundation, alongside email, cloud access, video calls, VPNs, payments, gaming, software updates, and remote administration.
This is why the phrase internet as a network infrastructure is useful. It shifts attention away from content and toward function. A robust internet layer does not need to “do” anything flashy; it needs to make packets find destinations reliably, quickly, and securely. When that layer is weak, every service above it inherits the weakness.
| Layer | What it does | What failure looks like |
|---|---|---|
| DNS | Turns human-readable names into IP addresses | Sites seem offline even when servers are healthy |
| Routing | Chooses paths between networks | Slow loading, unreachable regions, or odd detours |
| Interconnection | Moves traffic between providers and platforms | Congestion, higher latency, or asymmetric paths |
| Transport capacity | Handles the raw volume of data | Packet loss, jitter, and peak-time slowdown |
Once those jobs are separated, the rest of the stack becomes much easier to evaluate. The next step is to look at the physical network that makes all of it possible.
The physical backbone that carries traffic
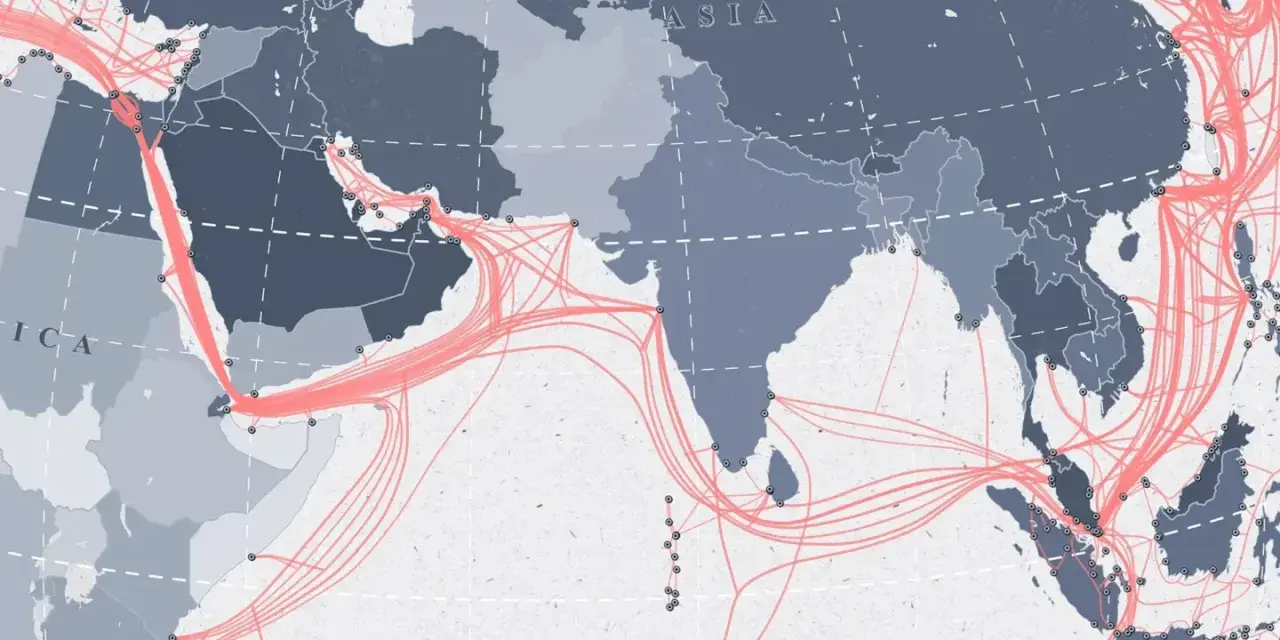
The internet is still a physical system first. Fibre cables run through ducts, street cabinets, exchanges, carrier hotels, and data centres before traffic ever reaches a browser. At the international level, subsea cables do the heavy lifting. The UK Parliament’s undersea-cables inquiry notes that the UK relies heavily on those cables and that they carry 99% of the country’s data to and from the outside world.
That is not an abstract dependency. It affects finance, cloud services, emergency communications, logistics, media delivery, and the ordinary act of loading a webpage. A strong design usually has several layers of physical diversity:
- Access networks connect homes, offices, masts, and industrial sites to the provider edge.
- Metro fibre moves traffic around cities and into major exchanges.
- Long-haul and subsea routes carry traffic between regions and countries.
- Landing stations and data centres terminate and redistribute that traffic.
- Power and cooling keep the whole system alive when demand spikes or weather turns ugly.
The mistake I see most often is assuming two links automatically mean resilience. They do not if both links share the same duct, the same landing station, or the same power feed. Real diversity means separate failure domains, not just separate contract lines. That physical reality is why naming and routing matter so much once the traffic reaches the network edge.
DNS and routing are the control plane
If the physical layer is the road system, DNS and routing are the signage and the traffic logic. ICANN describes DNS as the Internet’s address book, and that is a good mental model: it translates a name people can remember into the IP address machines can use. The lookup path usually runs through a recursive resolver, then to root servers, then to the relevant top-level domain, and finally to the authoritative server that knows the answer.
DNS problems are often misunderstood because they can mimic site outages. In reality, the service may still be up; the name just cannot be resolved reliably. That is why DNS protection matters so much. Techniques such as DNSSEC add cryptographic verification, which helps resolvers detect tampering or forged responses. For anything public-facing, I treat that as baseline hygiene rather than an advanced extra.
DNS resolves names to addresses
The user types a domain, the resolver asks the hierarchy where that domain lives, and the result is an IP address. That sounds simple, but the design is resilient because no single server needs to know everything. Root servers know where top-level domains are; TLD servers know which authoritative servers to ask next; authoritative servers know the final answer. It is distributed, and that distribution is what makes it workable at global scale.
Read Also: Network Intelligence: Beyond Monitoring - Make Better Decisions
BGP decides how networks reach one another
BGP, the Border Gateway Protocol, is the routing protocol that lets networks tell each other what IP space they can reach. Cloudflare calls it the routing protocol for the Internet, and that captures the operational role well. BGP does not move packets itself; it tells routers which direction is sensible, based on policy, reachability, and preference. That is why route leaks or bad announcements can create wide disruptions even when the cables themselves are fine.
For security, the key idea is simple: DNS tells you where to go, and BGP helps decide how to get there. If either layer is manipulated or misconfigured, the damage can spread quickly. That leads directly into interconnection, where most of the internet’s performance is won or lost.
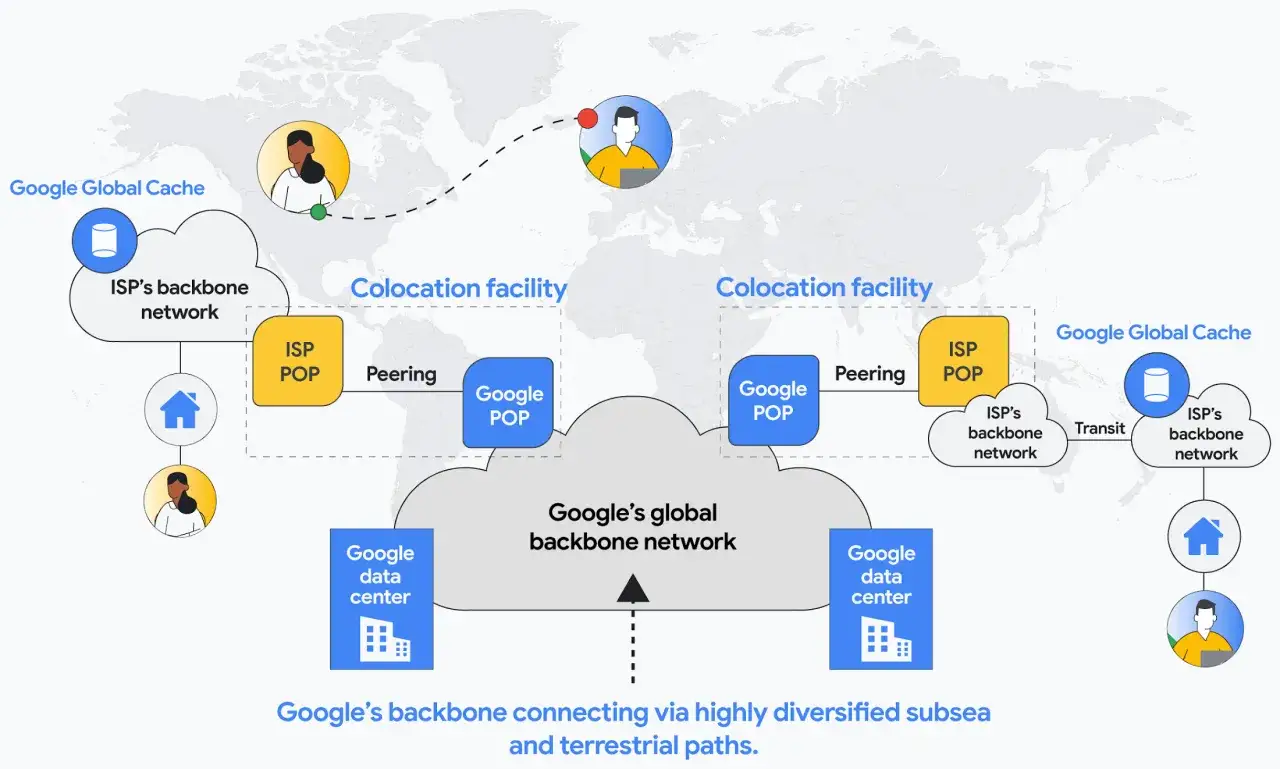
Interconnection is where speed and resilience are decided
Most users think they are connecting to one service, but their packets are usually crossing several networks on the way. Providers can hand traffic to upstream transit networks, exchange it directly through peering, or keep content close to users with CDN caches. Those are not just commercial choices; they shape latency, cost, and resilience.
| Model | What it does | Why operators use it |
|---|---|---|
| Transit | Buys reachability from a larger upstream network | Quick coverage across many destinations |
| Peering | Exchanges traffic directly with another network | Lower latency, lower cost, fewer hops |
| CDN caching | Places content closer to users | Less backbone load and faster delivery |
Internet exchange points matter here because they keep traffic local where possible. In practice, that means a request does not have to cross the country or the continent just to fetch a page, video segment, or software update. I see this as one of the quietest wins in network engineering: a well-placed exchange point often does more for user experience than a marketing-heavy bandwidth upgrade.
That logic is especially important in the UK, where geography makes international interconnection a structural issue rather than a side note.
Why this matters so much in the UK
The UK is an island economy with deep dependence on subsea connectivity, so resilience is not optional. Ofcom’s Connected Nations reports keep tracking the country’s communications infrastructure, including the rollout of full-fibre and gigabit-capable networks, which is useful context because access quality shapes everything above it. But the more strategic point is that the UK’s international links are concentrated through a relatively small set of cable systems and landing sites.
That concentration affects how I think about public-sector continuity, financial services, cloud dependency, and business risk. If an international route degrades, the result may not be a dramatic national outage. More often it shows up as slower access to SaaS tools, delayed transactions, unstable video links, or regional performance drops. Those failures are expensive precisely because they look minor at first.
| Sector | What it depends on | What weak infrastructure can cause |
|---|---|---|
| Finance | Low-latency routing, stable DNS, international reachability | Delayed settlements, failed sessions, compliance headaches |
| Healthcare | Cloud records, secure links, remote collaboration | Slower access to systems and degraded coordination |
| Public services | Citizen portals, identity systems, third-party integrations | Queueing, failed logins, and service backlogs |
| Media and retail | CDN reach, peering efficiency, and caching | Slow pages, abandoned sessions, lower conversion |
The UK’s geographic situation also changes the risk model. A nation with a dense land border can reroute more easily across terrestrial alternatives. The UK has fewer such escape routes, so submarine resilience, domestic peering, and varied upstream paths carry more weight than they do in many other markets. That makes the failure modes worth spelling out clearly.
Where networks fail and how to design for resilience
Most serious outages are not caused by one catastrophic mistake. They are usually the result of several small assumptions lining up badly: a shared duct, a single DNS provider, a routing error, an undersized failover path, or a power issue at the wrong site. Once you start looking for them, the weak points are predictable.
- Single physical paths create hidden dependence. Separate contracts are not enough if the fibre shares the same route.
- One-DNS setups are fragile. A secondary resolver or anycast deployment is much safer.
- Loose routing policy invites trouble. Prefix filtering and RPKI reduce the blast radius of bad announcements.
- No failover testing means the backup path may fail when you need it most. I would test it under load, not only in a maintenance window.
- Weak observability hides problems until users complain. Watch latency, packet loss, DNS resolution time, and route changes together.
There is one rule I repeat often: redundancy only helps when the redundant parts fail differently. Two links into the same building do not give you true resilience if a single power cut can take both out. The best designs break dependency chains at multiple layers, including carrier, geography, power, and control plane.
That is also where security and operations meet. Resilience is not just about surviving attacks; it is about surviving ordinary accidents, software faults, and demand spikes without forcing users to notice the plumbing underneath.
What I would prioritise in 2026
When I review a modern network stack, I look for a few practical signs that the infrastructure has been designed with reality in mind rather than in slides:- Multiple upstream providers with genuinely different routes.
- Local peering or CDN presence where user concentration justifies it.
- DNS deployed with anycast and protected with DNSSEC.
- Routing hygiene backed by RPKI, prefix filtering, and clear incident procedures.
- Monitoring that covers path quality, not just whether a service is technically up.
- Documented failover tests that prove recovery works under pressure.
That list is not glamorous, but it is the difference between a network that looks fine in normal weather and one that can absorb a cable fault, a misroute, or a provider incident without collapsing into visible downtime. Once you see the internet as a network infrastructure, the investment priorities become much clearer: diversify paths, harden the naming and routing layers, and keep local traffic as local as possible. That is the practical foundation behind reliable connectivity in the UK and everywhere else that depends on it.