NetFlow is one of the cleanest ways to see how traffic moves across a network without drowning in raw packets. It gives you a flow-level view of who talked to whom, how much data moved, and when a conversation started or stopped, which is exactly the kind of visibility that matters in observability and monitoring.
In this article, I break down how NetFlow works, what it records, why teams still rely on it for troubleshooting and security, and where its limits begin. I also compare it with IPFIX and sFlow so you can judge which flow telemetry model fits a real network instead of an idealised diagram.
The short version is that NetFlow turns traffic into usable flow records
- NetFlow is flow telemetry: it describes conversations, not packet payloads.
- Most records are built around the 5-tuple, then enriched with counters, timestamps, and interface data.
- It is strong for top talkers, bandwidth analysis, anomaly detection, and incident triage.
- Sampling and timeouts are the main trade-offs, because they shape accuracy and export volume.
- IPFIX is the standards-based evolution of the same idea, while sFlow uses a different sampling approach.
- It works best when you pair it with logs, metrics, and packet capture instead of treating it as a full replacement.
What NetFlow actually records
At its core, NetFlow watches packets as they pass through a router or switch, groups them into flows, and exports a compact record for each conversation. A flow is usually identified by the 5-tuple: source IP, destination IP, source port, destination port, and protocol. That simple model is powerful because it lets you summarise traffic behaviour without storing every packet.
A useful flow record normally includes more than just the 5-tuple. In practice, I expect to see packet counts, byte counts, start and end timestamps, input and output interfaces, and sometimes extra fields such as DSCP, next-hop, autonomous system numbers, VLAN tags, or MPLS labels. Those extra fields matter when you are trying to explain why traffic took a certain path or why a specific class of traffic started to dominate a link.
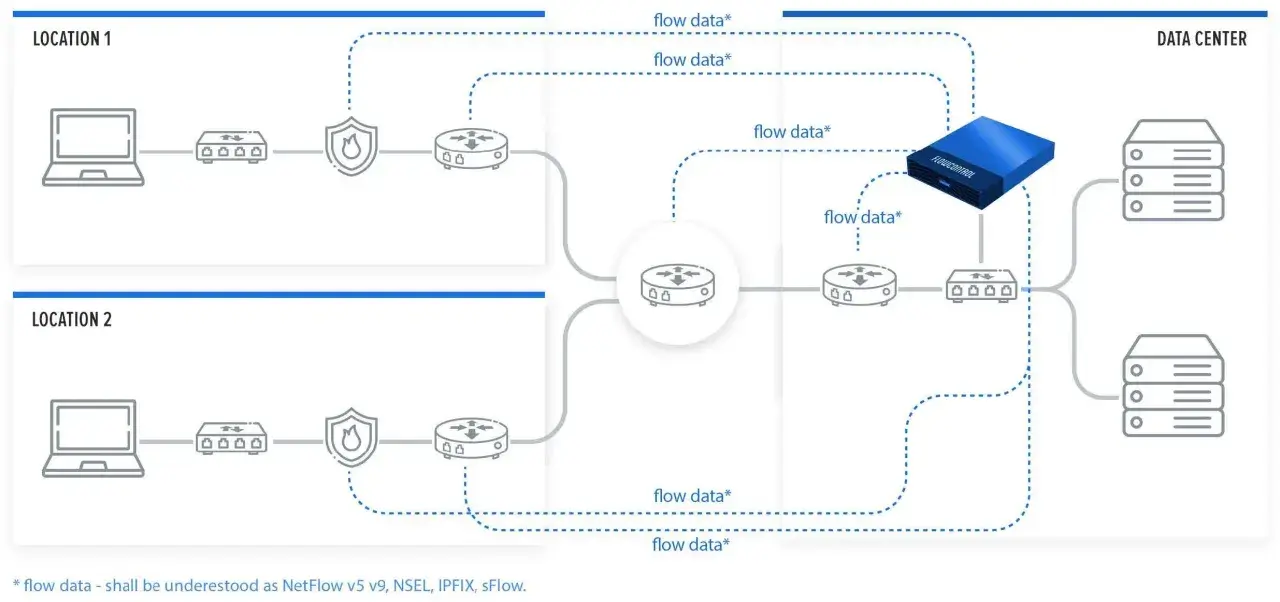
The main thing to remember is that NetFlow describes metadata about communication, not the payload itself. If traffic is encrypted, you still get useful behavioural signals even though you cannot inspect the content. That is why flow telemetry remains useful in modern networks where encryption is the rule rather than the exception. Once you understand that distinction, the export pipeline makes a lot more sense.How flow export works in practice
The workflow is simple, but the timing details matter. A device acts as an exporter, keeps recent flow state in a cache, and sends flow records to a collector for storage and analysis. The collector then normalises, aggregates, and visualises the data so an operator can ask practical questions like “what changed on this link?” or “which host suddenly became the top talker?”
In a typical deployment, the exporter does not send a record for every packet. It updates the cache while the flow is active, then exports a record when one of a few things happens: the conversation ends, the active timeout is reached, or the inactive timeout expires. On some Cisco platforms, the default inactive timeout is 15 seconds and the active timeout is 1,800 seconds, although many teams shorten the active timeout when they want fresher visibility.
That timeout choice is not cosmetic. If you shorten the active timeout to around 60 seconds, you get more frequent updates for long-lived sessions, which is helpful during incident response and near-real-time monitoring. The trade-off is more export traffic and more records to store. If you keep the defaults, you reduce overhead but accept slower visibility into long-running flows. I usually treat that as a design decision, not a minor tuning knob.
Sampling adds another layer. On higher-speed links, devices may inspect only a subset of packets to keep overhead manageable. Sampling is often the right call on busy core or edge interfaces, but it changes how you read the data: you are working with estimates, not exact packet-by-packet accounting. That is acceptable when the goal is trend detection or anomaly spotting, but it becomes a problem if someone expects billing-grade precision from a heavily sampled feed.
The practical lesson is straightforward: NetFlow is efficient because it compresses the story of traffic into records. It is also opinionated because the cache, timeout, and sampling choices decide how much of that story survives export.
Why it still matters for observability and security
In observability terms, NetFlow fills a gap that logs, metrics, and traces do not cover well on their own. Logs tell you what an application said. Metrics tell you whether a system is under pressure. Traces tell you how a request moved through services. Flow telemetry tells you how the network carried the conversation, which is often the missing layer when a team is trying to explain a slowdown or a spike.
| Question | What NetFlow can show | Why it helps |
|---|---|---|
| Who is using the most bandwidth? | Top talkers by bytes, packets, and duration | Lets you separate a genuine demand spike from a single noisy host |
| Is the issue north-south or east-west? | Source and destination patterns across subnets, sites, and zones | Helps you decide whether to investigate internet access, internal services, or lateral movement |
| Is something scanning the network? | Many short flows to many destinations or ports | Useful for spotting reconnaissance, malware behaviour, or misconfigured automation |
| Did a change alter traffic shape? | Before-and-after shifts in volume, ports, and peer sets | Validates routing, firewall, or application changes quickly |
Security teams use the same data for slightly different reasons. NetFlow is good at showing unusual volume patterns, unexpected destinations, and bursts of short-lived connections that do not fit normal behaviour. It is not a substitute for a packet capture when you need proof, but it is often the fastest way to narrow the problem before you spend time on deeper forensics.
I find this distinction important: NetFlow is excellent for detection and triage, not final confirmation. That is exactly why it belongs in an observability stack rather than sitting off to the side as a niche network feature. From here, the next question is which flow format gives you the best fit.
NetFlow, IPFIX, and sFlow are similar but not the same
People often use these names interchangeably, but the export model is different enough to matter. If your devices and collector are flexible, the choice usually comes down to how much structure you want in the records and how much overhead you can tolerate.
| Protocol | How it works | Strengths | Trade-offs | Best fit |
|---|---|---|---|---|
| NetFlow | Exports flow records from network devices | Mature, widely supported, easy to operationalise | Vendor variants exist, and sampling may be involved | Teams that want proven flow visibility on routers and switches |
| IPFIX | Standards-based flow export with template-driven records | More extensible and vendor-neutral | Collector and device support must line up | Environments that want a cleaner standard and richer fields |
| sFlow | Samples packets and pairs that with interface counters | Low overhead and simple statistical visibility | Less precise flow history than full flow export | Very high-speed links where statistical visibility is enough |
My rule of thumb is simple. If a device can export IPFIX cleanly and your collector supports it, I usually prefer that over older proprietary variants because the format is more extensible. If you already have a stable NetFlow deployment, there is no need to rip it out just to chase novelty. In monitoring, boring and reliable often beats elegant and fragile.
This comparison also explains why flow telemetry is still evolving rather than disappearing. The core idea is stable; the implementation details keep changing as networks get faster and more distributed.
Where NetFlow falls short
Flow data answers a lot of questions quickly, but it does not answer all of them. The biggest mistake I see is treating it like packet capture with fewer bytes. It is not that. It is summarised telemetry, and the summarisation is exactly what creates its blind spots.
- No payload visibility: you cannot see HTTP paths, SQL queries, file contents, or malware payloads.
- Sampling can blur detail: small bursts, low-volume attacks, and rare events can be missed or undercounted.
- Network architecture can distort the picture: NAT, load balancers, overlays, and asymmetric routing can make attribution less obvious.
- High cardinality can become expensive: modern environments create huge numbers of short-lived flows, which affects storage and query performance.
- It needs context: without logs and metrics, you can see that traffic changed but not always why it changed.
Those constraints do not make NetFlow weak. They make it honest. I would rather have a clear, bounded view of traffic behaviour than pretend that a flow record can replace the rest of the observability stack. If I need precise evidence, I reach for packet capture or application logs. If I need broad visibility fast, NetFlow is usually the first thing I check.
That trade-off leads naturally to the question of deployment: how do you get useful data without flooding the collector or the network?
How I would deploy it without creating noise
If I were rolling this out on a real network, I would keep the first deployment narrow and intentional. The goal is not to monitor every interface on day one. The goal is to capture enough signal to answer the questions that actually matter.
- Start with the right export points: internet edges, WAN links, datacentre uplinks, firewalls, and a few important internal chokepoints.
- Decide the question before the configuration: capacity planning, anomaly detection, peering analysis, chargeback, or incident response all benefit from slightly different records.
- Set timeouts deliberately: a shorter active timeout gives fresher visibility, while a longer one reduces export noise and storage demand.
- Use sampling only when the traffic volume justifies it: on smaller or critical links, unsampled flow data is usually easier to trust.
- Validate against another source: interface counters, SNMP, streaming telemetry, firewall logs, or a short packet capture should roughly agree with the flow picture.
I also try to avoid a few common mistakes. Do not export from every access switch unless you have a very clear reason. Do not compare sampled flow totals with interface counters as though they are exact. Do not forget that NAT, VRFs, and tunnels can change how flows look once they reach the collector. And do not keep enormous amounts of flow data just because storage is cheap; if you are not querying it, you are probably archiving noise.
On Cisco-style deployments, the current documentation still reflects a practical pattern many operators use: an inactive timeout around 15 seconds, an active timeout around 30 minutes by default, and a shorter active timeout when fresher data is worth the extra export volume. That is not a universal rule, but it is a useful starting point for tuning.
A practical way to read flow data in a modern network
The best mental model I can offer is this: NetFlow tells you how the network behaved, not what the payload said. Once you stop expecting it to do more than that, it becomes much easier to use well. It is a fast, lightweight way to see the shape of traffic, compare current behaviour with a baseline, and decide where to dig deeper.
- Use NetFlow when you need broad visibility with modest overhead.
- Use logs when you need application or security context.
- Use metrics when you need saturation, latency, or resource trends.
- Use packet capture when you need proof or payload-level detail.
- Prefer IPFIX-capable tooling when you are building something new and the ecosystem supports it.
That combination is what makes flow telemetry valuable in observability and monitoring. It is not the whole story, but it is often the fastest way to make the story legible. If you treat it as one layer in a larger system instead of a standalone answer, NetFlow keeps earning its place in modern network operations.