The goal is to catch risk early and explain it fast
- Monitoring tells you that something is off; observability helps you understand why.
- The most useful telemetry mix is metrics, logs, traces, and synthetic checks on key journeys.
- Alerts work best when they are tied to SLOs, not random infrastructure thresholds.
- OpenTelemetry is the cleanest portable instrumentation layer in 2026 for multi-cloud and hybrid estates.
- Security, retention, and cost controls belong in the design, not as an afterthought.
What cloud monitoring actually has to do
I think of cloud operations as a control loop. You observe the state of the system, decide whether it is safe, and then act. That action might be scaling a service, draining traffic from a bad node, rolling back a release, revoking access, or simply slowing down a deployment that is clearly not behaving.
That is why I never treat monitoring as just "watching graphs." A serious setup has to cover four things at once: infrastructure health, application behavior, platform changes, and operational risk. If the stack cannot show you which region, account, service, deployment, or dependency changed, it is too narrow to be useful in production.
- Infrastructure tells you whether compute, storage, network, and cluster capacity are under pressure.
- Application health tells you whether users are seeing latency, failures, or broken flows.
- Change visibility tells you whether a deploy, config edit, autoscaling event, or access change lines up with the incident.
- Operational control tells you whether the team can respond automatically or manually with confidence.
When I frame it this way, monitoring stops being a reporting exercise and becomes part of the operating system of the cloud. That makes the difference between knowing that something is wrong and actually being able to explain it.
Once you see operations as a control loop, the difference between monitoring and observability becomes much easier to define.
Why observability gives better answers than dashboards alone
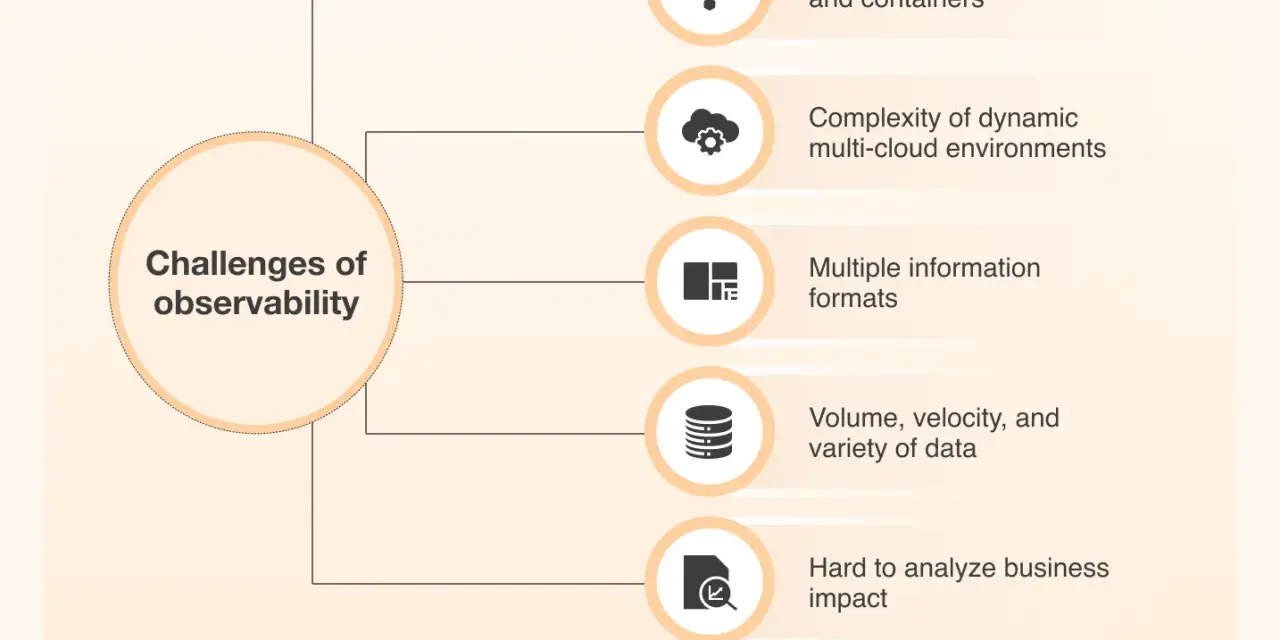
Monitoring asks known questions. Observability helps answer the questions you did not know to ask. That distinction matters in cloud environments because the failure is often not where the symptom appears. A slow checkout might start as a database lock, a misconfigured sidecar, or a noisy neighbour in a shared cluster. A simple threshold page will tell you that the symptom exists; observability should help you trace the chain of cause and effect.
| Approach | What it answers | Strength | Main limitation |
|---|---|---|---|
| Monitoring | Is the system healthy right now? | Fast, familiar, and good for obvious failures | Poor at explaining cross-service problems |
| Observability | Why is the system behaving this way? | Correlates signals across services and layers | Only works well if instrumentation is deliberate |
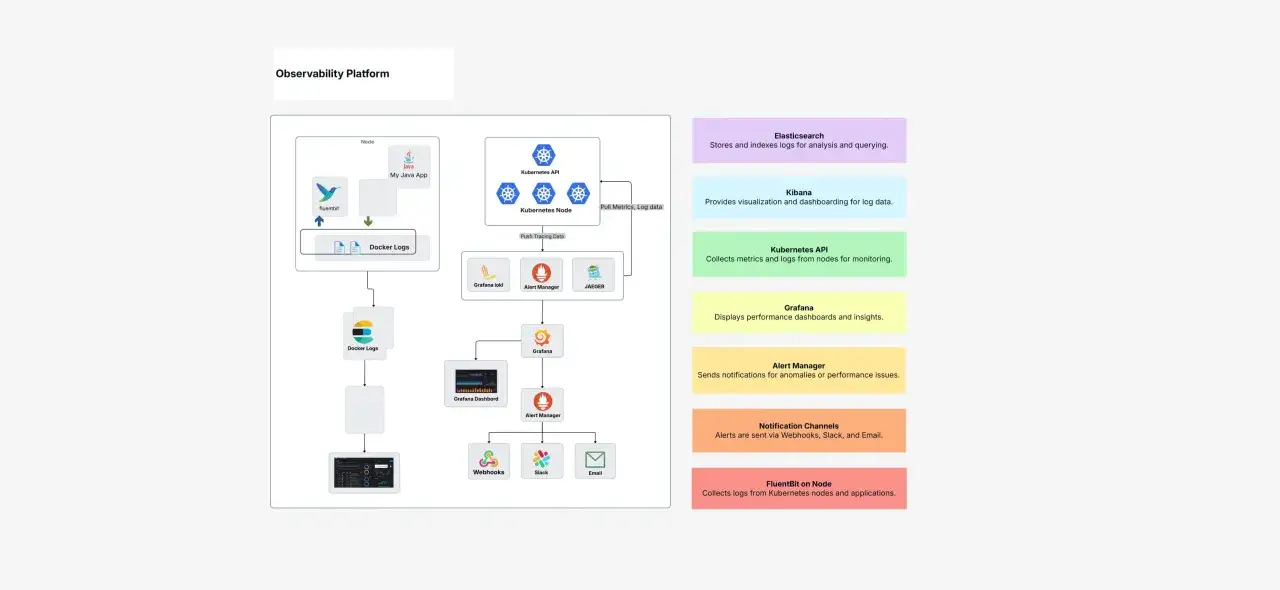
I still want monitoring in the stack, but I want it inside a broader observability model. In practice, that means tracing requests across services, linking logs to request IDs, and using metrics for the trends that need fast alerting. OpenTelemetry is the cleanest default I know in 2026 because it keeps that telemetry portable instead of locking it into one backend.
That sets up the next question: which signals should you collect, and how should they relate to each other?
The telemetry stack that actually works
The most reliable cloud setups are built on a small number of signals that reinforce each other rather than compete for attention. I usually start with metrics, logs, traces, and synthetic checks. Some teams add profiling later, but I treat that as a second wave once the basics are trustworthy.
| Signal | What I use it for | Good for | Common trap |
|---|---|---|---|
| Metrics | Trends, saturation, error rate, and alerting | Capacity planning and early warning | Too many labels, too much cardinality, not enough meaning |
| Logs | Exact events, errors, and audit trails | Forensics and compliance review | Raw noise, duplicate messages, and leaked secrets |
| Traces | Request flow across services and dependencies | Latency analysis and root cause work | Sampling too aggressively or losing context between services |
| Synthetic checks | Whether a user journey still works from the outside | Login, checkout, API availability, and regional health | Assuming they replace real traffic signals |
What matters most is correlation. I want to jump from a spike in error rate to the exact trace, then to the relevant logs, then to the deployment that landed five minutes earlier. OpenTelemetry is useful here because it standardises collection and export, while tools such as CloudWatch, Azure Monitor, Google Cloud Observability, Prometheus, and Grafana can sit on top of the same basic model.
If I have one strong opinion here, it is this: shared context beats isolated dashboards. A dashboard that cannot explain what changed is decoration. A telemetry stack that ties together service names, trace IDs, deployment markers, and error context is much closer to an actual operating tool.
Once the data is flowing, the real test is whether the alerts tell a human what to do next.
How I set up alerting so people trust it
I start with service-level objectives, or SLOs, which are the reliability targets that reflect what users actually feel. An error budget is the room you have left before you miss that target. That framing is far better than building alerts around arbitrary CPU or memory thresholds that may not mean much to the customer.
As a simple example, a 99.9 percent availability target over 30 days leaves roughly 43 minutes of error budget. A 99.5 percent target leaves about 3.6 hours. That is a much more useful way to think about risk than staring at a flat line and hoping the page is "obvious."
Start from user impact
I like fast-burn and slow-burn alerts. A fast-burn alert catches a sudden incident that is consuming the budget at an unhealthy rate. A slow-burn alert catches a quieter degradation before it turns into a serious outage. Google SRE's burn-rate approach is still one of the best ways to keep alerting precise without making it blind to drift.
Read Also: Cribl Customers - Who Uses It & Why UK Teams Should Care
Make every alert answer three questions
- What changed? Link the alert to a service, deployment, or dependency, not just a metric name.
- Who owns it? Alerts without ownership are just noise with a timestamp.
- What should I check first? Add a short runbook so the first responder does not have to guess.
If you run Prometheus in the stack, Alertmanager is the piece that deduplicates, groups, routes, and silences alerts, which is exactly what you want during a large incident. That kind of routing matters because a single root problem can generate dozens of symptoms, and nobody benefits from a page storm.
I also avoid paging on every error. Low-value alerts train teams to ignore the system. If a signal is informative but not urgent, I send it to a dashboard, ticket, or chat channel with context instead of waking someone up. That discipline is what makes on-call sustainable.
The next decision is where these signals should live and how much platform work you want to own.
Choosing tools without creating a bespoke platform
There is no single best tool stack. The right choice depends on how much control you want, how many clouds you use, and how much operational overhead the team can absorb. In 2026, I treat OpenTelemetry as the default instrumentation layer unless there is a strong reason to stay completely native to one vendor.
| Approach | When I choose it | Strength | Trade-off |
|---|---|---|---|
| Managed cloud-native suite | Most workloads live in one cloud and the team wants speed | Fast setup, native integrations, less tooling glue | Tighter coupling to one platform and its pricing model |
| OpenTelemetry plus a backend of choice | Portability, hybrid cloud, or multi-cloud consistency matters | Vendor-neutral instrumentation and flexible export | Requires more design discipline in the collector and backend path |
| Prometheus, Alertmanager, and Grafana | The team is metrics-heavy, Kubernetes-heavy, or strongly platform-minded | Mature open-source ecosystem and strong query power | More maintenance, more decisions, and more ownership |
I usually recommend the simplest stack that can still survive growth. If most workloads sit in AWS, CloudWatch can be a strong operational anchor. If you are deep in Azure or Google Cloud, the native observability suites are often the fastest path to value. If you need flexibility across environments, keep the collection layer standardised and let the backend vary.
What I try to avoid is a Frankenstein stack where every team has its own dashboard style, its own alerting logic, and its own naming conventions. That is how a monitoring program becomes impossible to manage.
A tool only survives if it respects security, privacy, and cost constraints.
Security, compliance, and cost control belong in the same dashboard
For UK teams, I would be conservative with telemetry by default. Logs can easily contain personal data, tokens, internal hostnames, customer identifiers, and request bodies that never needed to be retained in the first place. If the data is not required for operations, I would not store it casually just because the pipeline can ingest it.
There are three cost and risk levers I watch closely: ingestion volume, retention, and cardinality. High-cardinality labels are metric dimensions with too many unique values, and they can make a monitoring bill grow faster than the insight does. Long log retention is useful for audits, but it should be explicit. Trace sampling is helpful, but it should be tuned so it still captures the paths you need during an incident.
- Redact secrets and sensitive fields before logs leave the service boundary.
- Separate audit logs from debug logs so access can be controlled differently.
- Set retention tiers for hot, warm, and archive data instead of keeping everything forever.
- Sample traces intentionally so production noise does not become storage waste.
- Track observability spend the same way you track any other production service cost.
I also like to mark deployments, config changes, and access changes directly on dashboards. That makes it much easier to connect a spike with a real event instead of someone speculating in a war room. In practice, that small discipline saves more time than another expensive alerting feature.
The most common failure modes are avoidable once you name them.
The mistakes I see most often in cloud operations
- Collecting everything and understanding nothing - teams ingest huge amounts of telemetry but never define the decisions it should support.
- Alerting on infrastructure instead of service health - CPU and memory are useful, but customers feel latency, failures, and broken journeys.
- Leaving alerts without ownership - if nobody is named, the alert will be ignored or bounced around.
- Skipping runbooks - a good alert should tell the responder what to check, what to rule out, and when to escalate.
- Ignoring deploy and config events - most production problems are easier to explain when you know what changed right before them.
- Using too many custom labels - high-cardinality metrics can quietly make the whole system expensive and slow.
- Treating observability as a postmortem project - it works best when it is baked into delivery, not added after an outage.
The fastest way out is to make every signal map to a real decision. If a graph, log stream, or trace does not help someone act, I remove it or move it behind a lower-priority workflow.
What I would standardize first in a UK cloud team
- Instrument one critical customer journey end to end with OpenTelemetry so you can trace real requests, not just infrastructure noise.
- Choose one central place to query metrics, logs, and traces so the team is not switching between disconnected tools during an incident.
- Define 3 to 5 SLOs that reflect actual user outcomes, then build alerts around error-budget burn instead of raw thresholds.
- Create one fast-burn page and one slow-burn ticket or chat alert for each important service.
- Add redaction, sampling, retention tiers, and access controls before telemetry volume grows, not after it becomes expensive.
If I had to reduce the whole discipline to one rule, it would be this: collect less, correlate better, and alert only when the user would feel the problem. That is the point where monitoring stops being a pile of tools and becomes a reliable way to run cloud services with confidence.