The north-south traffic vs east-west traffic split sounds like a tidy networking distinction, but in observability it changes what you can see, what you miss, and which signals deserve your attention first. I use it as a practical lens: edge-facing traffic usually tells you about exposure and availability, while internal service-to-service traffic tells you where systems actually break. This article breaks down both directions, shows how monitoring changes between them, and gives a concrete way to instrument a modern cloud or hybrid estate.
The essentials at a glance
- North-south traffic crosses the boundary of your environment, so edge devices, gateways, and firewalls usually see it first.
- East-west traffic stays inside the platform, which makes service discovery, retries, and internal dependencies harder to observe.
- Monitoring north-south paths is mostly about availability, TLS, request rates, and edge latency.
- Monitoring east-west paths is mostly about dependency latency, error propagation, retries, and service identity.
- eBPF, distributed tracing, and service mesh telemetry are the most useful ways to recover visibility inside the cluster.
- In UK hybrid environments, private links and mixed cloud/on-prem estates make internal traffic visibility more valuable, not less.
What the two traffic directions actually mean
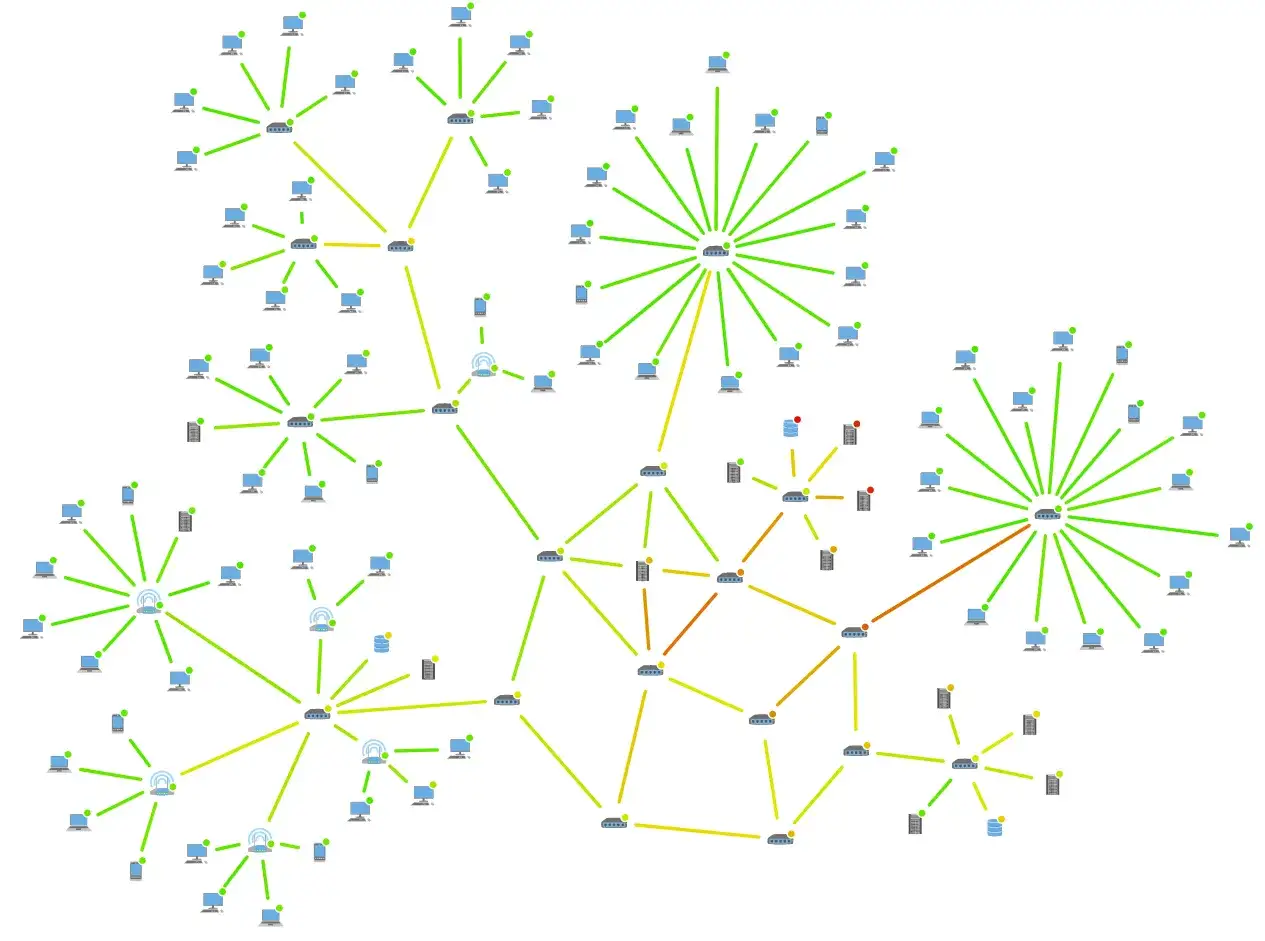
North-south traffic is traffic that enters or leaves your environment. A customer opening a web app, a partner API calling your gateway, or an employee connecting through a VPN all sit in that lane. It is the part of the network most teams are used to watching because it crosses a clear boundary.
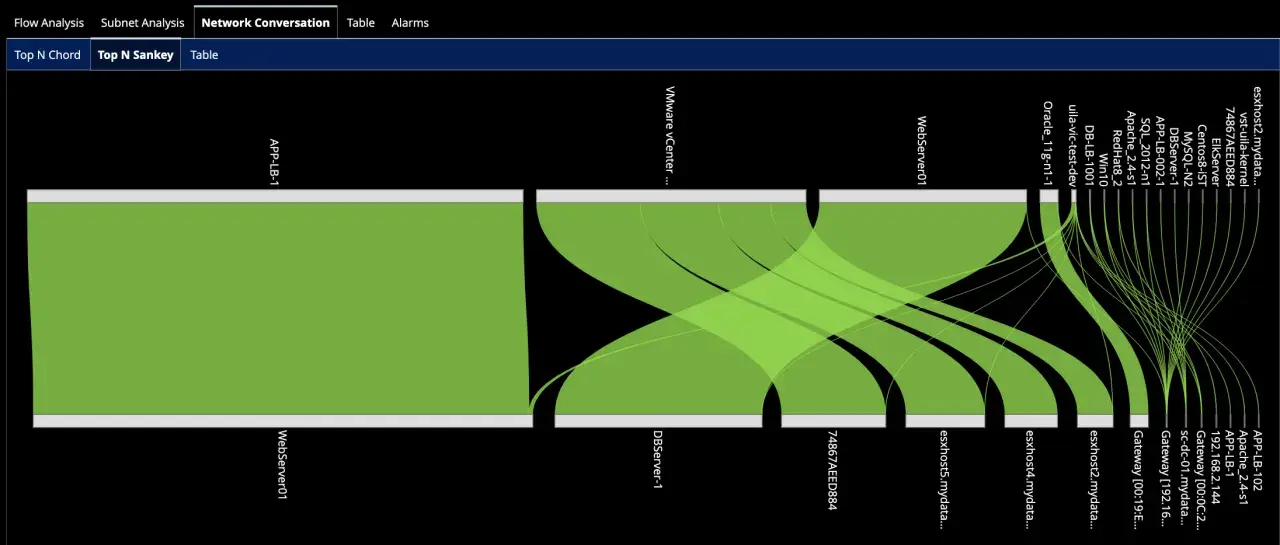
East-west traffic is traffic that stays inside the platform. One service calls another, a pod reads from a queue, a worker talks to a database proxy, or a microservice fans out to three internal APIs. This is where the real application dependency graph lives, and it is also where many incidents become hard to explain.
| Direction | Where it moves | What you can usually see first | Main monitoring focus |
|---|---|---|---|
| North-south | Between users, partners, the internet, and your edge | CDN, WAF, load balancer, API gateway, firewall | Availability, TLS, auth failures, request rate, edge latency |
| East-west | Between services, pods, nodes, queues, and internal APIs | Service mesh, traces, flow telemetry, node-level data | Dependency latency, retries, timeouts, connection churn, service health |
The important shift is this: north-south monitoring tells you whether the front door works, while east-west monitoring tells you whether the rooms behind that door are connected properly. Once you see that distinction, the observability problem becomes much easier to frame.
Why observability gets harder inside the platform
Edge traffic is easier to monitor because it crosses devices that were built to inspect it. Load balancers, firewalls, reverse proxies, and gateways naturally collect connection data, status codes, and latency trends. Internal traffic is different. It moves through short-lived pods, ephemeral IPs, service discovery layers, and sometimes encrypted sidecars, so the neat boundary disappears.
That is why monitoring often feels deceptively strong at the perimeter and frustratingly weak once a request is inside the system. A request can be accepted cleanly at the edge, then slow down because of a bad retry policy, a noisy neighbour on the same node, a broken DNS lookup, or a service mesh policy that is doing exactly what it was asked to do and no more. The symptoms look like one issue; the cause is often several small ones.
- Service discovery changes quickly, so the caller-callee map can drift during autoscaling or rollouts.
- Encryption hides payloads, which is good for security but limits packet inspection.
- Retries amplify noise, so one upstream fault can create a cascade of duplicate requests.
- Short-lived workloads vanish before a human can inspect them manually.
- Shared infrastructure blurs blame, because storage, network, and application latency can look identical from the outside.
I usually treat that as the point where basic monitoring stops being enough and proper observability begins. The next step is to decide which signals actually explain the traffic you care about.
What to monitor for each traffic pattern
Different directions need different questions. For north-south traffic, I care about what the user or partner experiences at the edge. For east-west traffic, I care about whether service dependencies are healthy and whether the application can still move work across the internal graph without friction.
| Traffic pattern | Best signals | What a sudden change often means | Example alert |
|---|---|---|---|
| North-south | 5xx rate, request rate, TLS failures, WAF blocks, edge latency, auth errors | Public endpoint trouble, certificate issues, access problems, upstream dependency loss, or attack traffic | p95 latency up 30% from baseline, or 5xx above 1% for 5 minutes |
| East-west | Service-to-service latency, retry rate, timeout rate, queue depth, gRPC errors, DNS failures, connection resets | Broken dependency, bad deploy, noisy neighbour, service discovery failure, or saturation inside the cluster | Retry rate doubled on a critical path, or p95 on a fan-out chain up 25% |
| Shared signals | CPU, memory, packet loss, certificate expiry, saturation, dropped connections | Infrastructure pressure, rollout mistakes, or a network path that is degrading under load | Latency and utilisation rise together for more than one sampling window |
Those thresholds are starting points, not universal rules. I get better results by comparing each service to its own baseline than by forcing a single number across every workload. A 20% latency jump might be harmless for a batch process and unacceptable for a checkout API. The signal matters more than the slogan.
Once the signals are separated, the tooling choice becomes much easier.
The tool stack that reveals hidden flow
I do not expect one tool to solve both directions well. Metrics, logs, traces, and flow telemetry each answer a different question, and the best stacks combine them without drowning the team in noise. Red Hat's OpenShift network observability docs point out that eBPF-based collection can surface flow data from pods, services, and nodes, which is exactly why it matters for east-west visibility.| Tool | Best for | Strength | Tradeoff |
|---|---|---|---|
| Metrics | Trend monitoring, SLOs, saturation, error budgets | Cheap, fast, easy to alert on | Shows that something changed, not always why |
| Logs | Exact failures, request context, application errors | High detail for debugging | Noisy and expensive if over-collected |
| Distributed tracing | Latency across service hops | Shows where a request slows down | Needs instrumentation and consistent sampling |
| Flow logs and eBPF | Who talked to whom, on which port, and at what rate | Excellent for dependency maps and internal traffic patterns | Usually metadata, not full payloads |
| Service mesh telemetry | mTLS, policy, retries, routing, identity | Strong control and visibility for service-to-service paths | Adds operational complexity and overhead |
| Packet capture | Deep forensic analysis | Most detailed view of the wire | Hard to scale and rarely the right first step |
Common mistakes that distort the picture
- Thinking the perimeter is the whole network. If you only watch the edge, you miss the internal hops where most cloud-native failures hide.
- Alerting on host health but not user impact. A healthy node can still host a broken service chain.
- Using packet capture as the first tool. It is powerful, but it is slow, expensive, and often overkill for routine incidents.
- Ignoring DNS and service discovery. Many east-west problems look like application bugs when the real issue is name resolution or routing metadata.
- Collecting too much telemetry without a plan. A flood of low-value data makes it harder to see the few signals that matter.
- Letting retries hide real latency. Retries can make an outage appear smaller for a while, then blow up error budgets later.
In a hybrid estate, these mistakes are expensive because one missing dependency can look like a dozen small outages. That is especially true when your traffic crosses cloud, branch, and on-prem boundaries in the same request path.
How I would prioritise monitoring in a UK hybrid estate
In the UK, I often see a mix of public cloud front ends, private internal services, and at least one on-prem or co-lo segment connected through private links or VPNs. That mix makes a split approach sensible: watch the edge for customer impact, and watch the internal graph for service health. Trying to use one dashboard for both usually means you see neither clearly.
- Map the important paths first. I start with the top three customer journeys and the internal services they depend on.
- Instrument the edge. I track TLS health, request rates, edge latency, auth failures, and any WAF or gateway blocks.
- Add internal flow visibility. I bring in eBPF, service mesh, or flow logs on the critical east-west paths, not everywhere at once.
- Correlate traces and logs. One trace ID and one service identity scheme saves a huge amount of time during incidents.
- Keep security telemetry joinable. I want network and security data to line up, even if they stay in separate systems.
- Review alert noise regularly. If an alert does not change a decision, it is usually not worth keeping.
The practical payoff is simple: you catch public-facing problems quickly without losing sight of the internal dependencies that cause them. That is the real difference between monitoring a boundary and understanding a system.
The rule I use when choosing where to instrument first
If the issue is visible to customers, I begin at the north-south boundary. If the issue appears as a cascade between services, I move inward and instrument the east-west paths that carry the dependency chain. When I cannot decide, I look for the place where traffic crosses a trust boundary, because that is usually where the most valuable telemetry sits.
For most teams, the win is not another dashboard. It is a cleaner map of which traffic matters, which layer can actually see it, and which signal proves whether the problem is user-facing or buried inside the platform.