The decision comes down to scope, control, and exit risk
- It shifts networking from owned hardware to subscription-based capability, which changes both budgeting and operations.
- The strongest use cases are multi-site, hybrid-cloud, and fast-changing environments where manual network work becomes a bottleneck.
- The biggest risks are hidden recurring charges, weak observability, and contracts that make it hard to leave cleanly.
- For UK buyers, data transfers, resilience design, and local support coverage deserve the same attention as price.
- A good service should make policy and troubleshooting simpler, not hide the network behind another black box.
What this model changes in practice
I usually break the shift into four changes, because that is where the value or the pain shows up:
- Procurement moves from buying routers, firewalls, and connectivity appliances upfront to paying for a service layer that can scale with demand.
- Deployment gets faster because new sites, users, or cloud links are provisioned from a portal or API instead of waiting on physical refresh cycles.
- Operations become more software-driven, which means policy, segmentation, and monitoring matter more than rack space.
- Risk changes shape: you may reduce hardware burden, but you also inherit contract, integration, and vendor-dependency risk.
That is why I do not treat the model as a simple replacement for buying network gear. It is a different operating model, and it only makes sense when the network is expected to change often. Once that shift is clear, the next step is to look at the parts you are actually buying.
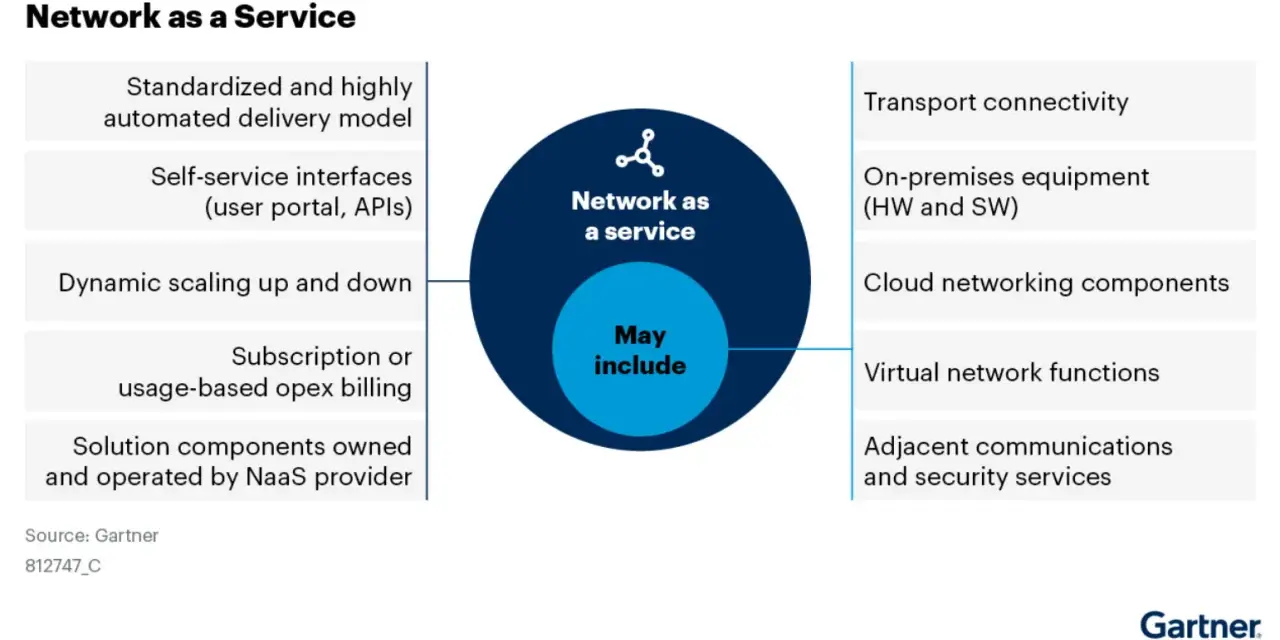
What sits inside the service
The strongest offers are not just a pipe. They usually combine transport, policy, security, and lifecycle support so the network can be consumed as a platform rather than a pile of separate tools. Cisco’s framing is useful here: the category can include hardware, software, management tools, licences, and lifecycle services, not only connectivity.
| Capability | What it covers | Why it matters |
|---|---|---|
| Connectivity and transport | Private links, internet breakout, and branch-to-cloud paths | Keeps traffic moving on the right routes without hand-built plumbing |
| Routing and segmentation | Policy-driven path selection and traffic separation | Helps isolate departments, applications, or tenants |
| Security enforcement | Firewalls, VPNs, access controls, inspection, and zero-trust policy | Brings security closer to the user and workload |
| Remote access | Secure connectivity for staff and contractors outside the office | Useful when office-centric designs no longer fit the workforce |
| Observability | Logs, telemetry, route visibility, and incident reporting | Makes troubleshooting faster and less guesswork-heavy |
| Lifecycle management | Patches, upgrades, licences, and service changes | Reduces the maintenance burden that usually gets ignored until it hurts |
That breadth is what makes the model interesting, but it is also why buyers need to be specific. Are you getting transport only, security plus transport, or a full operating model with policy and lifecycle management folded in? The answer changes the economics and the day-to-day experience.
Where it shines and where I would hesitate
I would reach for this model when the network has to change often and the team cannot afford long install cycles. It is strongest when flexibility matters more than owning every piece of the stack.
Good fits
- Opening new branches or temporary sites. This is where provisioning speed matters more than squeezing every pound out of fixed assets.
- Connecting cloud-heavy businesses. If workloads live across public cloud, colocation, and on-premises systems, a service model can reduce the number of moving parts.
- Integrating after mergers or acquisitions. Standardising network policy through a service can be faster than stitching together two legacy estates.
- Supporting hybrid work. When users, devices, and applications move across locations, a centrally managed service is usually easier to keep consistent.
Weak fits
- Very stable sites. If the network barely changes for years, a subscription layer may cost more than it saves.
- Air-gapped or highly specialised environments. Industrial, lab, or defence-adjacent networks often need hardware and topology choices that a standard service cannot absorb.
- Latency-sensitive workloads. Trading, real-time control, and other jitter-sensitive systems can outgrow generic policy abstractions quickly.
- Teams that need deep bespoke control. If you rely on custom routing, unusual inspection chains, or niche hardware, a managed abstraction can become friction rather than help.
The trap is buying flexibility you will not use, or paying for convenience where control is the real requirement. That balance becomes clearer when you compare it with the older ways of doing the job.
How it compares with building and running the network yourself
One useful distinction is that SD-WAN, or software-defined wide area networking, is a transport and policy layer. It can sit inside a broader service, but by itself it does not solve lifecycle management, observability, or the full security picture. That is why I compare the model against the whole operating approach, not just against one product category.
| Model | Best when | Strength | Trade-off |
|---|---|---|---|
| Self-built network | You need maximum control and already have a strong network team | Deep customisation and full ownership of design choices | Heavy capital spend, more tooling, and more specialist labour |
| Managed network services | You want to offload day-to-day operations but keep a familiar architecture | Lower internal workload and simpler adoption | You may still juggle separate vendors and static network patterns |
| Service-based network platform | You need fast scaling, central policy, and easier multi-site change | Operational agility and less hardware to manage directly | Recurring subscription cost and stronger dependency on the provider |
| SD-WAN only | You mainly need smarter traffic steering between links | Better path selection and branch performance | It is not a complete network operating model on its own |
This is also where budgets can become misleading. Subscription pricing shifts spend from CapEx to OpEx, but recurring bandwidth, egress, premium support, and add-on security modules can make a supposedly simple service more expensive than a well-used private network. I always tell people to compare the full running cost, not just the entry price.
What UK buyers need to check first
In the UK, I would treat data handling as part of the network design, not a separate legal review. If telemetry, support tickets, packet captures, or backups move outside the UK, UK GDPR and the Data Protection Act 2018 become relevant immediately, and the ICO’s transfer guidance is the checklist I would use before approving those flows.- Data location. Confirm where logs, telemetry, support data, and backups are stored, processed, and retained.
- Transfers and subprocessors. Ask whether the provider or any subprocessors sit outside the UK, and how those transfers are documented.
- Resilience. Check carrier diversity, route diversity, and power diversity for branch and cloud connections.
- Support coverage. Make sure incident handling matches your operating hours, not just the vendor’s timezone.
- Audit and exit. Demand exportable configurations, clear retention settings, and a clean transition plan if you leave.
UK buyers often discover that the hard part is not buying connectivity, but proving where support data travels and who can touch it. Once those basics are clear, the selection process gets much less fuzzy.
How I would evaluate a provider before rollout
When I compare providers, I ask the same five questions every time because they expose whether the platform is genuinely operable or just well marketed.
| Question | What a good answer looks like | Red flag |
|---|---|---|
| Can I change policy without opening a ticket? | Portal or API control with an audit trail | Manual change requests for every small adjustment |
| What is included in the base price? | Clear separation between bandwidth, security, support, and usage charges | Opaque add-ons for routine tasks |
| Can I see routes and incidents? | Useful telemetry, route visibility, and post-incident notes | Black-box reporting that only shows uptime percentages |
| How does failover work? | Documented failover paths and tested recovery procedures | “Resilient by design” with no proof |
| Can I leave cleanly? | Exportable configurations, data retention rules, and contract exit steps | Proprietary dependencies that force a painful unwind |
I would rather see boring transparency than elegant automation I cannot inspect. If the provider cannot explain what happens during failure, it has not earned a place in a production network.
The rollout pattern that keeps the service honest
If I were introducing this into a UK environment, I would start with one branch, one cloud connection, and one repeatable failure scenario. That gives you a real test of provisioning speed, observability, and failover without betting the whole estate on a new operating model.
- Measure how long it takes to provision and change policy.
- Measure whether incident response gets faster or just more polite.
- Measure whether users notice fewer outages, not just prettier dashboards.
The best versions of this model make the network feel calmer, more visible, and easier to change. The weak ones hide complexity behind a subscription, which is a packaging change, not an operational improvement.