
Modern connectivity is built from network infrastructure technologies that decide how traffic moves, where it fails, and how safely it reaches users. The real challenge is not picking one shiny product; it is choosing the mix of fibre, Ethernet, wireless, routing, cloud control, and security that matches the site, the workload, and the budget. This article breaks that stack down in practical terms, with a UK lens and the decisions that matter in 2026.
What matters most when you design the network stack
- Physical capacity still sets the ceiling: if the cabling, fibre, or access circuit is weak, no software layer will fully fix it.
- Wi-Fi 7, Ethernet upgrades, and 5G backup solve different problems; they are not interchangeable.
- SD-WAN and SASE simplify branch and cloud connectivity when you have multiple sites or mixed transport links.
- Security now belongs inside the architecture, especially through segmentation, identity checks, and encrypted traffic flows.
- In the UK, broadband coverage is broad but uneven, so resilient design still depends on local availability and fallback options.
What sits inside a modern network stack
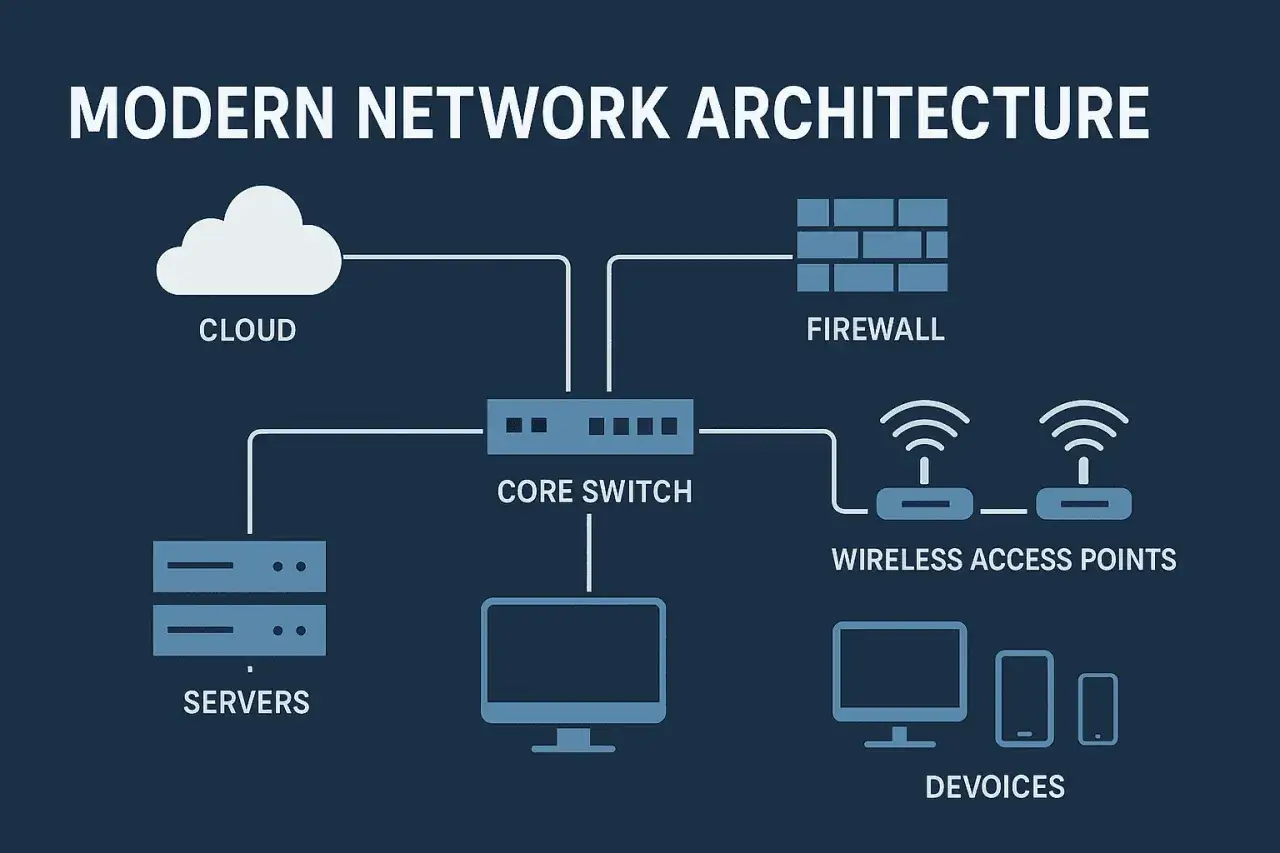
I look at network design as a layered system rather than a single product category. Each layer has a different job: moving bits, switching frames, routing packets, applying policy, or enforcing security. If one layer is overspecified and another is neglected, the user experience still suffers.
The practical value of that view is simple. It stops teams from buying a faster-looking solution for the wrong layer. A better firewall will not fix poor wireless coverage, and a better Wi-Fi deployment will not save a brittle WAN design.
| Layer | What it does | Typical technologies | Main trade-off |
|---|---|---|---|
| Physical | Moves signals across cable, fibre, or radio | Fibre, copper, optics, PoE | Capacity and reliability depend on the medium itself |
| Link and access | Connects devices on the local network | Ethernet, switches, VLANs, Wi-Fi, 802.1X | Fast access is useless if coverage or segmentation is poor |
| Network and routing | Moves traffic between subnets, sites, and providers | IP, IPv6, OSPF, BGP, route policies | Good routing improves resilience, but bad design is hard to troubleshoot |
| Transport and delivery | Shapes session behaviour and application flow | TCP, UDP, QUIC, load balancing, DNS, DHCP | Performance depends on both latency and congestion handling |
| Control and policy | Centralises configuration and path selection | SD-WAN, orchestration, controllers, automation | Automation reduces toil only if the team can operate it well |
| Security | Limits who can reach what, and under which conditions | Firewalls, NAC, segmentation, zero trust, VPNs | Security adds friction, so it has to be applied with precision |
My rule of thumb is to treat DNS, DHCP, and routing as first-class infrastructure, not background utilities. When those services fail, the whole environment can look broken even when the links are fine. Once the layers are clear, the next question is which transport medium sets the ceiling in your environment.
The transport layer still decides most of the experience
For most organisations, the biggest practical difference comes from the way traffic enters and leaves the network. Fibre, Ethernet, Wi-Fi, 5G, and satellite all solve different problems. The mistake I see most often is assuming that wireless can compensate for an undersized core or that more bandwidth automatically means better service.
Ethernet remains the workhorse in offices and data centres because it is predictable. Fibre is the obvious choice when you need higher capacity, lower jitter, or a cleaner path for critical services. Wi-Fi 7 is a genuine upgrade for dense workplaces because wider channels and multi-link operation improve performance under load, but it only pays off when the wired backhaul and switching are ready. PoE, or Power over Ethernet, still matters because it lets access points, phones, and cameras run from a single cable and a centrally backed-up power domain.
| Technology | Best fit | Strength | Trade-off |
|---|---|---|---|
| Full-fibre or leased Ethernet | Head offices, critical branches, data-centre links | High capacity, stable latency, strong reliability | Cost and lead time can be significant |
| Wi-Fi 7 | Dense offices, collaboration spaces, mobility-heavy environments | Better throughput and latency in crowded conditions | Needs modern clients and a properly sized wired core |
| 5G or fixed wireless access | Temporary sites, quick turn-ups, backup connectivity | Fast deployment and a useful diverse path | Performance varies with signal quality and local congestion |
| Satellite | Remote locations and resilience backup | Reaches places that are hard to wire | Latency and consistency are usually weaker than terrestrial links |
If you only remember one thing here, make it this: the access layer should match the application mix, not the marketing sheet. Voice, video, point-of-sale traffic, industrial sensors, and guest browsing do not all need the same treatment. When the physical layer is in place, the real gains come from controlling traffic consistently across sites and clouds.
Why software-defined control matters now
Once a network stretches across branches, cloud services, remote workers, and mobile users, manual configuration stops scaling. That is where SD-WAN, orchestration, and policy automation become genuinely useful. An overlay is simply a logical path built on top of multiple physical circuits, and it lets you steer traffic without pretending every link behaves the same way.
I would not buy SD-WAN just because it sounds modern. I would buy it when I need one policy model across fibre, broadband, and mobile backup, or when I need to turn up a branch quickly without stitching together three separate management planes. The same logic applies to SASE, which combines wide-area connectivity with cloud-delivered security so users can reach applications with fewer manual handoffs.
- Telemetry gives you continuous measurements from switches, routers, and endpoints instead of occasional snapshots.
- AIOps, or AI-assisted operations, helps correlate those measurements and surface anomalies faster than a human can scan dashboards.
- Automation reduces change windows and repeatable errors, which is useful only when the underlying design is already disciplined.
The catch is operational maturity. A controller does not cure bad architecture; it only manages it more efficiently. If the team cannot explain the traffic paths, ownership, and fallback behaviour, software-defined control adds another moving part rather than simplifying the system. That is why security design has to be part of the architecture itself, not bolted on later.
Security is part of the architecture, not an add-on
The cleanest mental model here is zero trust, and NIST’s guidance is useful because it removes the old assumption that anything inside the perimeter is automatically safe. In practice, that means access decisions are made per request, based on identity, device posture, and context, rather than on network location alone.
The network technologies that support that model are practical, not mystical. Network access control checks whether a device should be allowed on the network and what role it should receive. Segmentation splits traffic into zones so a compromise in one area does not spread everywhere. Microsegmentation takes that idea further inside data centres or cloud workloads. Encryption through IPsec or TLS protects traffic across links you do not fully trust.
The mistake I see most often is perimeter thinking: one firewall at the edge, then a flat internal network with broad trust. That might have been tolerable when most systems lived in one building. It is a weak fit for hybrid environments, SaaS-heavy estates, and distributed teams. A better design assumes that east-west traffic needs just as much scrutiny as north-south traffic.
That becomes especially important when you choose the access mix for the UK market, because the best security model still has to run on circuits you can actually order.
How UK organisations should choose their access mix
Ofcom’s Spring 2026 update puts gigabit-capable access at 87% and full-fibre coverage at 78% across the UK, which is enough to make fibre the default starting point in many places, but not enough to make it universal. The practical lesson is that location still matters. What you can deploy in London or Manchester may look very different from what you can justify in a rural office, warehouse, or temporary site.
For most UK organisations, I would compare the main access options like this:
| Option | Best for | Why it works | What to watch |
|---|---|---|---|
| Full-fibre leased line | Critical sites, headquarters, latency-sensitive operations | Predictable performance, strong service guarantees, cleaner symmetrical capacity | Higher cost and longer lead times |
| Business broadband over fibre | Standard offices and smaller branches | Good enough for many cloud-first workloads and usually easier to source | Shared capacity and weaker guarantees than a dedicated circuit |
| MPLS or managed WAN | Organisations that still want tightly governed site-to-site routing | Central policy and predictable paths | Less flexible than internet-based designs and often harder to justify on cost |
| 5G or fixed wireless access | Back-up links, pop-up sites, places that need speed of deployment | Fast to activate and useful as a diverse path | Variable performance and signal dependence |
| Satellite | Remote continuity planning and hard-to-reach locations | Works where terrestrial options are limited | Latency and consistency are usually weaker than wired options |
Private 5G has its place too, but I would keep it targeted. It makes sense in factories, ports, logistics hubs, and campuses where coverage, device density, or mobility justify the investment. For a normal office, it is usually more ambition than answer. The better question is whether you need a fast primary circuit, a diverse backup path, or both. Once that is clear, the upgrade plan gets much simpler.
How I would plan an upgrade in 2026
The strongest network projects usually begin with application requirements, not hardware shopping. I would start by mapping which services are sensitive to latency, jitter, or outage, then decide what level of resilience each one really needs. A video-call platform, a trading application, a warehouse scanner network, and a guest Wi-Fi service should not be given the same design priority.
- Measure real traffic peaks, not just average usage, and include expected growth from cloud apps, remote work, and AI-enabled tools.
- Set resilience targets first, including how long the business can tolerate an outage and what happens when one link fails.
- Separate traffic types with VLANs, firewall zones, or similar controls so guest, corporate, and device traffic do not share the same trust level.
- Design for two failures, not one: a link failure and an edge-device failure are both common enough to plan for.
- Check power, cooling, rack space, and spare optics before you approve the hardware order.
- Test monitoring, failover, and rollback before production cutover, because the first outage is a terrible time to discover a weak assumption.
I see too many teams upgrade bandwidth before they upgrade visibility. That is usually backwards. Better monitoring, cleaner segmentation, and a realistic failover plan often deliver more value than a raw speed increase. Once those basics are set, it becomes much easier to judge which next-wave technologies are worth attention.
What deserves attention after the next refresh
The next cycle of network change is less about chasing novelty and more about improving both throughput and operational clarity. In the data centre, higher-speed Ethernet keeps moving upward, which matters because back-end traffic keeps growing even when office traffic looks stable. In the workplace, Wi-Fi 7 will matter most where many users and devices compete for airtime in the same room.AI-assisted operations will also keep improving, but I would treat them as a multiplier rather than a foundation. They help when the telemetry is clean and the topology is well understood. They are much less impressive when the network itself is poorly documented. The same caution applies to edge computing, private wireless, and any other technology that sounds transformative but still depends on boring fundamentals like addressing, power, cooling, and support ownership.
If there is one principle I would keep, it is this: choose the simplest architecture that still meets the performance, resilience, and security requirements. A network that is easy to explain is usually easier to support, easier to secure, and cheaper to grow. That is the standard I would use before buying the next switch, circuit, or wireless platform.