The useful version is context, not just more data
- See containers as part of a chain: image, pod, node, service, dependency, and request.
- Collect metrics, logs, traces, and orchestration events together, then correlate them.
- Alert on symptoms that users feel, not only on raw resource usage.
- Keep labels and dimensions disciplined so dashboards stay readable.
- Use a collector or pipeline to standardise telemetry before it reaches your backend.
What container visibility really means in practice
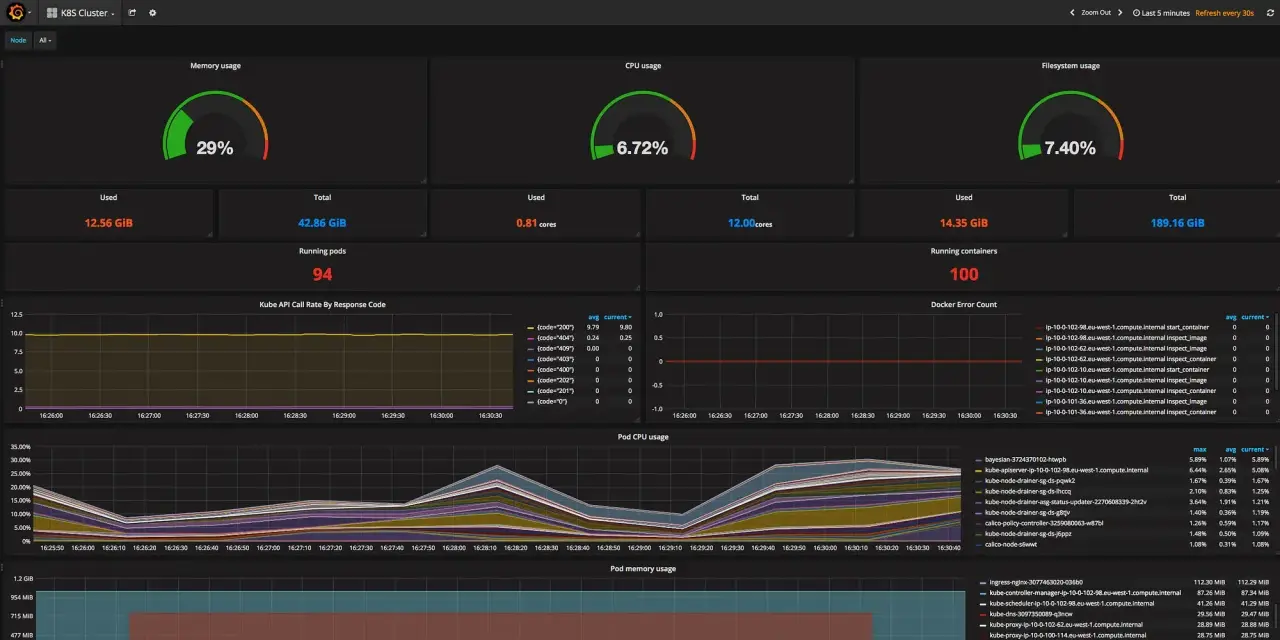
At a practical level, this is not about flooding a dashboard with every available signal. It is about being able to answer a few hard questions quickly: is the container healthy, is the pod scheduled correctly, is the node under strain, and is the application actually serving users? Kubernetes documentation frames observability as the collection and analysis of metrics, logs, and traces, which is the right mental model here because it keeps the focus on understanding rather than just counting.
I usually split the problem into layers. The container runtime tells me whether the process is alive and how it is behaving. The orchestration layer tells me whether Kubernetes is restarting, rescheduling, or throttling the workload. The application layer tells me whether requests are succeeding. And the dependency layer tells me whether the real fault is somewhere else entirely. Once those layers are separate, a service can look “up” while still being effectively broken.
| Layer | What it tells you | The question it answers |
|---|---|---|
| Container runtime | Process health, restarts, resource use, exit behaviour | Is the workload actually running? |
| Orchestration | Scheduling, pod status, rollout progress, node pressure | Is Kubernetes the thing causing the trouble? |
| Application | Request success, latency, errors, business actions | Are users feeling the failure? |
| Dependency chain | Timeouts, retries, downstream saturation, external failures | What else in the path is dragging the service down? |
That distinction matters because basic monitoring often only sees one layer clearly. The next problem is that containerised systems hide failure patterns very well, which is why simple health checks rarely tell the full story.
Why basic monitoring is not enough in containerised systems
Containers are short-lived, replicated, and easy to replace. That is useful for resilience, but it also means a fault can disappear before anyone has time to inspect it. A pod can restart, move to another node, and leave behind only a few weak clues unless the telemetry is captured and correlated in time.
Host-level monitoring adds another trap. CPU and memory graphs may look normal while a container is being throttled by limits, suffering from noisy neighbours, or waiting on a downstream service that is quietly timing out. I also see teams underestimate how often autoscaling masks the original problem: a broken release can trigger a scale-out event and make the cluster look active even as every new pod inherits the same defect.
| Symptom | Why simple monitoring misses it | What visibility adds |
|---|---|---|
| Restart loops | The pod keeps coming back, so the cluster looks superficially healthy | Exit codes, crash logs, and rollout timing reveal the real failure |
| Latency spikes | Average CPU can stay low while one dependency slows everything down | Traces show where time is spent and which hop is expanding |
| Service is “up” but unusable | Liveness checks pass even when the application cannot complete requests | Request logs and error rates show user-facing failure, not just process health |
| Sudden resource pressure | Autoscaling may hide the first sign of strain | Per-container metrics expose throttling, memory growth, and noisy neighbours |
| Suspicious activity | Generic logs do not always show process launches or unusual network behaviour | Platform events and security telemetry add the missing context |
Once you see these patterns, the important question becomes which signals deserve attention first, because not every source of data is equally useful in practice.
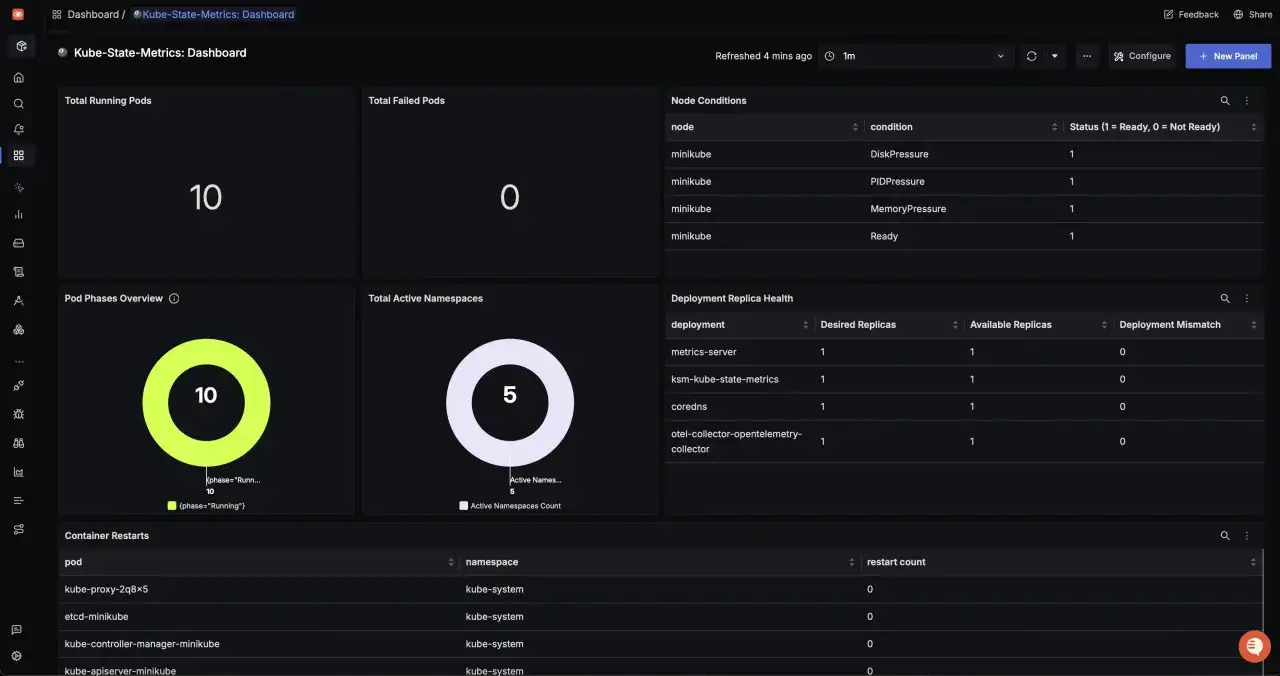
The signals that matter most from each container
OpenTelemetry is useful here because it is vendor-neutral and built around traces, metrics, and logs. That matters in container environments because you want the freedom to collect from many runtimes and send data to the backend that fits your stack, not the other way round. I like to think of the signals as answering different questions rather than competing with each other.
| Signal | What it tells you | Best used for |
|---|---|---|
| Metrics | How the system behaves over time | Load, saturation, error rate, restart counts, throttling, and trend detection |
| Logs | What happened at a specific moment | Debugging crashes, configuration mistakes, and application-level errors |
| Traces | Where a request spent its time | Latency breakdowns, dependency mapping, and cross-service correlation |
| Events | What changed in the platform | Rollouts, rescheduling, image updates, and node pressure |
The part that is often missed is resource context. A log line is far more useful when it carries pod, namespace, deployment, image, and node metadata. OpenTelemetry’s logging model explicitly supports correlation through resource context, which is exactly what makes container-level troubleshooting much faster. Without that context, each signal sits in isolation and the operator has to stitch the story together by hand.
That is why I prefer to treat telemetry as a joined dataset rather than four separate tools. Once the signals are clear, the architecture around them should make collection, enrichment, and routing boring in the best possible way.
How to build a stack that scales with Kubernetes
I rarely start with a dashboard. I start with the path the data takes. OpenTelemetry with Kubernetes is a good reference point because the ecosystem now expects collectors and auto-instrumentation to sit near the workloads, not to be bolted on afterwards. The OpenTelemetry Operator for Kubernetes exists for exactly that reason: it can manage collectors and handle auto-instrumentation for workloads that need it.
- Instrument the application first. If the service cannot emit useful traces, metrics, or structured logs, no backend will fix that later.
- Run a collector close to the workloads. A collector gives you one place to batch, enrich, filter, sample, and redact before data leaves the cluster.
- Attach stable metadata. Service name, namespace, deployment version, node, and environment should be consistent enough to support filtering without creating label chaos.
- Send telemetry to backends that can correlate it. A strong backend is not just storage; it is the layer that lets you jump from an alert to a trace to the relevant logs without losing time.
- Alert on user impact. I would rather get one alert that reflects failed requests or prolonged latency than ten alerts for raw CPU drift.
The reason this works is simple: it keeps the observability pipeline under control. You can still add specialised tooling later, but the foundation should already support correlation, enrichment, and reasonable retention. If that foundation is weak, every additional tool just adds another place where the truth can fragment.
The mistakes that quietly break observability
Most weak setups do not fail because the team chose the wrong dashboard. They fail because the data model is noisy, incomplete, or too expensive to sustain. I see the same mistakes over and over, and they are usually avoidable with a little discipline up front.
- High-cardinality labels - If every pod name, request ID, or container ID becomes a metric label, the backend starts to work for the storage engine instead of the team.
- Logs without structure - Free-form log lines are hard to filter, correlate, and alert on. Structured logs are not glamorous, but they save time every week.
- Only watching resource usage - CPU and memory matter, but they are not a substitute for service-level signals such as error rate, tail latency, and failed dependency calls.
- Ignoring restart reasons - A restarted container is not the same as a healthy container. Exit codes, OOM kills, and rollout history matter.
- Skipping security context - Process launches, unusual network connections, and privilege changes often sit outside the usual performance dashboard, but they are part of operational visibility.
- Collecting everything forever - Retention should match the value of the signal. Keep what you investigate, and drop what only creates cost and confusion.
A green dashboard can still hide a broken service. The cleaner the telemetry model, the easier it is to trust what you see and act on it without second-guessing every alert.
A rollout order that keeps the signal useful
If I were introducing this in a UK production environment, I would prioritise service impact, data handling, and operational habits before chasing fancy visualisations. Strong container visibility depends on discipline as much as it depends on tooling, and that is especially true when telemetry may contain customer identifiers, internal IPs, or other data you do not want spread across every console.
- Pick one critical service and define the user outcomes you care about most, such as availability, latency, and error rate.
- Standardise naming and labels before the system grows. Make service, namespace, version, owner, and environment consistent.
- Add logs, metrics, and traces through one pipeline so that correlation becomes a default behaviour, not a manual task.
- Wire alerts to real impact, then test them with a genuine incident scenario or a rehearsal that simulates one.
- Set retention, access control, and redaction rules early. Operational data can become sensitive very quickly in a container estate.
- Review what each alert actually led to. If an alert never changes a decision, it is probably noise.
Done well, this gives you the visibility you need without forcing the team to juggle disconnected tools during an incident. Start with one service, prove that the signals line up, and then expand the pattern only after it is genuinely useful.