Key takeaways for using flow telemetry well
- Flow records describe conversations, not payloads, so they are compact enough to scale across large estates.
- They are strongest for baselining, anomaly detection, capacity planning, and fast triage of traffic changes.
- They sit between metrics and packet capture, which makes them useful for both operations and security.
- Export quality, enrichment, and retention policy matter more than the dashboard skin.
- In UK environments, access control and retention discipline matter because flow records can still reveal sensitive business behaviour.
What flow records actually capture
At its simplest, flow telemetry is a compact record of a conversation between endpoints. A single record usually includes source and destination IP addresses, source and destination ports, protocol, timestamps, byte counts, packet counts, direction, and the device or interface that observed the traffic. Cisco’s current guidance describes this kind of export as metadata for each flow that crosses a device, which is the right mental model: you get enough context to understand movement, but not the payload itself.
That difference matters. A flow record is not a packet capture, and it is not an application log. It is a summary of communication, which is exactly why it scales so well.
| Field | Why it matters |
|---|---|
| 5-tuple | Identifies the conversation by source, destination, ports, and protocol. |
| Start and end time | Shows duration, burstiness, and whether a connection was short-lived or persistent. |
| Bytes and packets | Separates chatty control traffic from heavy data movement. |
| Interface, device, or zone | Helps you see where the traffic entered, exited, or crossed boundaries. |
| Application or tenant tags | Adds business context so IP addresses do not remain anonymous for too long. |
| Sampling and exporter metadata | Tells you how much trust to place in the record and how complete the view is. |
Why observability teams still rely on it
OpenTelemetry’s framing is useful here: observability is about asking questions about a system from the outside. Flow data gives network and platform teams one of the cleanest outside-in views available. I use it when I want to know whether a slowdown is caused by a path change, a saturated link, a noisy service, an unexpected dependency, or traffic that simply should not be there.
It is especially helpful because it fills the gap between coarse metrics and detailed logs. Metrics tell you that something changed. Logs tell you what a component said while it changed. Flow records tell you how communication moved across the network while everything else was happening.
| Signal | Best at | Weak at | Typical question answered |
|---|---|---|---|
| Flow records | Traffic patterns, dependencies, anomalies, capacity trends | Payload, protocol internals, packet loss details | Who talked to whom, how much, and for how long? |
| Metrics | Health, saturation, latency, error trends | Traffic lineage and peer relationships | Is the service or link healthy right now? |
| Logs | Application events, decisions, failures, identity context | Network-wide structure and volume trends | What did the application think happened? |
| Packet capture | Wire-level proof, protocol detail, retransmissions, payload issues | Scale and long retention | What exactly was on the wire? |
In practice, I do not treat these as competing tools. I treat them as layers. Flow telemetry gives me the shape of movement, and the other signals explain the state of the system around it. Once that is clear, the real work becomes building a pipeline that preserves the useful parts without drowning you in noise.
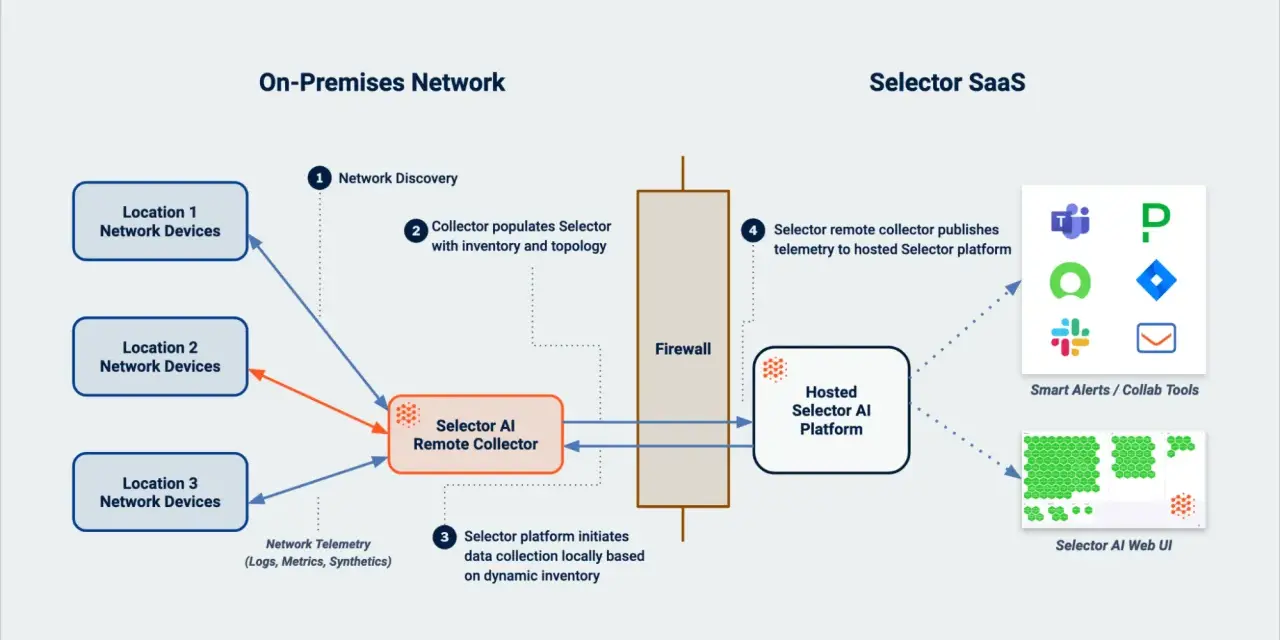
How to build a useful flow monitoring pipeline
A good pipeline is more important than a pretty dashboard. If the exporter is noisy, the collector drops records, or enrichment is inconsistent, your analysis will be brittle no matter how polished the UI looks. I usually design the pipeline in five steps.
- Export from the right choke points. Start with internet edges, VPN concentrators, WAN links, cloud gateways, inter-zone boundaries, and critical service tiers. You do not need every port if the goal is observability, not forensic exhaust.
- Normalise the records. Standardise field names, timestamp formats, sampling metadata, and protocol labels so different devices do not produce incompatible views.
- Enrich immediately. Add site, tenant, workload, owner, environment, and business service tags while the context is still available. Without enrichment, you end up staring at IPs instead of systems.
- Baseline before you alert. A seven-day rolling view is useful for incident detection, while a 30-day view is better for capacity planning and seasonal change. I would not alert on a spike until I know what “normal” looks like for that site or service.
- Keep the retention split sensible. A practical starting point is 14-30 days of raw records and 90 days of aggregated summaries. That is not a universal rule, but it is a workable default for many teams if compliance and storage costs are in play.
There is one operational detail I would not ignore: monitor the collectors themselves. Queue growth, template decode failures, exporter gaps, and record drops can quietly poison every downstream dashboard. If the telemetry pipe is sick, the story you see is only partly true. With the pipeline in place, the next step is deciding which problems it should answer first.
The incidents it helps you catch first
Flow records are at their best when something changed and nobody can yet explain why. I reach for them first in five situations:
- Capacity pressure. A branch link sitting above 80% of committed capacity for 10-15 minutes is not just “busy”; it is usually a sign that user experience is about to degrade.
- Unexpected service chatter. When a deployment suddenly multiplies east-west traffic, I want to know whether a service became chatty, fell back to a slower path, or started retrying aggressively.
- Suspicious destinations. New geographies, uncommon ports, and services talking to destinations they never used before are all worth a look, especially when the pattern appears outside business hours.
- Hybrid and SaaS path issues. In UK estates with branch offices, remote workers, and cloud services spread across London, Dublin, or farther afield, flow changes often reveal whether the path, not the app, is the real problem.
- Cost and dependency drift. A workload that suddenly shifts traffic to a more expensive region or starts depending on an extra upstream service is usually a sign of either architecture drift or a release issue.
What I like here is the speed of triage. Even when I do not know the root cause yet, I can usually narrow the blast radius in minutes: one service, one segment, one time window, one change. That said, there are clear limits to what the records can prove, and ignoring those limits is how teams overtrust the tool.
Where it stops being enough
Flow telemetry is powerful, but it is still summary data. It cannot show payloads, it cannot explain every retransmission, and it may miss short-lived bursts if the exporter is sampled too aggressively. It also becomes less transparent when NAT, tunnels, overlays, or encryption sit between the original sender and receiver. The record tells you that traffic moved; it does not always tell you why it behaved that way.
| Situation | What flow records tell you | What to add |
|---|---|---|
| TLS handshake fails | Which hosts tried to connect and how much traffic moved | Application logs and, if needed, packet capture |
| Intermittent packet loss | Volume changes and timing patterns | Interface counters, host telemetry, and packet analysis |
| Protocol parsing errors | That a conversation exists, not whether the payload was valid | Application logs or wire-level captures |
| Identity or authorisation issues | Traffic path and destination use | Authentication and access logs |
| Very short burst traffic on a sampled exporter | Possibly nothing, depending on the sample rate | Lower sampling, targeted mirroring, or local packet capture |
My rule is simple: if the question depends on flags, retransmissions, payload validity, or exact protocol state, I do not stop at flows. They are an excellent compass, not the whole map. That leaves one final question: what should stay visible on the dashboard so the next incident is easier to catch?
The signals I would keep visible before the next incident
If I had to keep only a small set of views live, I would choose the ones that answer three questions fast: what changed, where did it change, and is it a network issue or a service issue?
- Collector health with drop rate, lag, and decode errors.
- Top talkers by site, tenant, workload, and service, not just by IP.
- New destinations for each critical workload, because unfamiliar peers often matter more than total volume.
- East-west versus north-south ratios so you can see whether traffic is staying inside the platform or spilling out to the internet or WAN.
- 95th percentile utilisation for links and gateways, which is far more useful than a single peak.
- Deviation from baseline using a 7-day comparison for operations and a 30-day view for planning.
- Denied or unusual ports for security teams that need a clean view of policy drift and odd behaviour.
I would also keep retention and access controls tight enough to respect internal governance and UK privacy expectations. Flow records are less invasive than payload capture, but they still reveal business behaviour, user movement, and service relationships. The best setup is the one that gives operators enough context to act quickly without turning the monitoring stack into a liability. If you keep that balance, the data becomes genuinely useful: not just a feed of traffic, but a working model of how the network behaves when it is healthy, stressed, or quietly drifting out of shape.