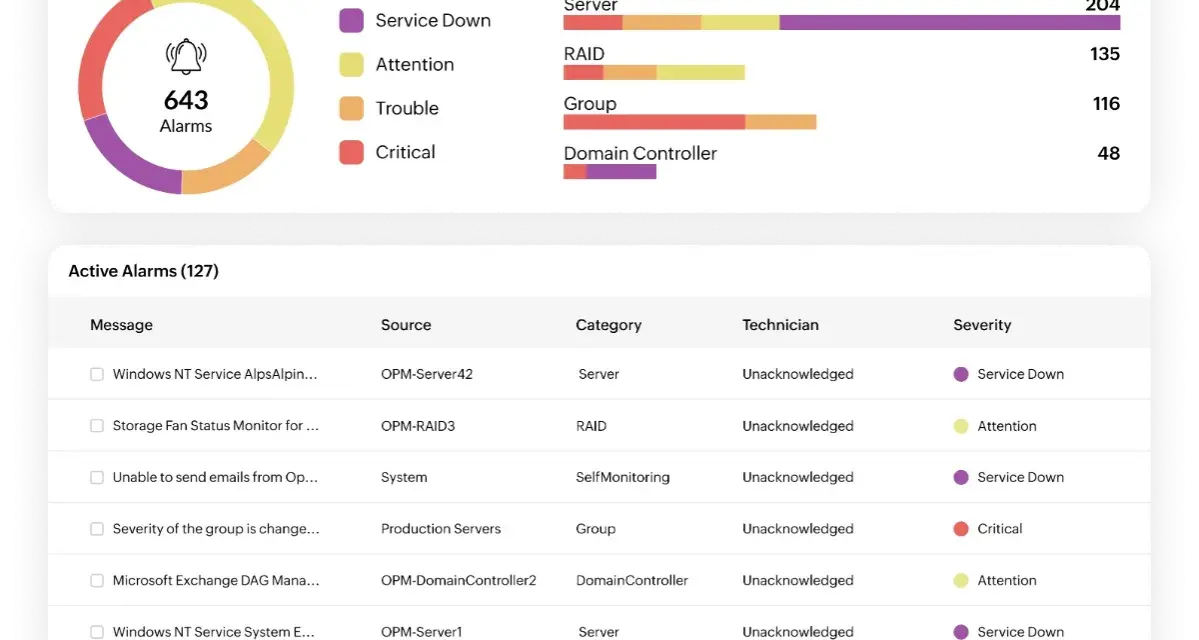
Monitoring a network is only useful when it tells you what changed, where it changed, and how quickly you can prove it. In this guide, I focus on the signals that actually help: device health, traffic flow, synthetic checks, alert design, and the observability habits that turn raw telemetry into decisions. I also cover the trade-offs that matter in UK environments, where privacy, cloud links, office circuits, and remote users often sit in the same estate.
What matters most before you add another tool
- Start with questions, not dashboards. Decide whether you need uptime, path quality, capacity, or incident detection first.
- Use more than one signal type. Metrics, logs, flows, and synthetic checks each answer a different question.
- Watch baselines, not just thresholds. A link at 70% utilisation may be fine at one time of day and risky at another.
- Keep alerts calm. A sustained breach is more useful than a burst of noise that clears on its own.
- Govern the data. In the UK, IP-based telemetry and logs can fall under UK GDPR, so retention and access controls matter.
What good network monitoring should answer
Good network monitoring should answer three practical questions fast: is the service reachable, where is the slowdown, and what changed first? If I cannot answer those, I do not really have operational visibility. I just have charts.That is where observability earns its keep. Monitoring tells you that latency rose or packets dropped. Observability helps you connect that change to a queue building on a switch, a routing flap, a DNS failure, or a noisy neighbour on a shared circuit. The point is not to stare at more data; the point is to reduce the time between symptom and cause.
I usually frame the problem this way: can I see the path, can I measure the path, and can I explain the path? If the answer is yes, the rest of the stack becomes much easier to design. Once those questions are clear, the next step is choosing the signals that matter most.
The signals that matter most
For network health, I care about a small set of signals more than anything else. They are boring in the best possible way: interface errors, latency, jitter, packet loss, utilisation, route state, and traffic patterns. Those tell you whether the network is moving cleanly, where it is getting tight, and whether the problem is local or distributed.
| Signal | What it tells you | Best use | Main limitation |
|---|---|---|---|
| Interface counters and errors | Physical and link-level trouble, drops, CRC issues, flaps | Finding failing ports, bad cabling, or duplex problems | Can look healthy while the user path is still slow |
| Latency, jitter, and packet loss | Whether traffic is still usable, not just technically “up” | Voice, video, SaaS, and remote access quality | Needs a baseline, otherwise normal variation looks like an incident |
| Throughput and utilisation | Capacity pressure and saturation trends | Planning upgrades and spotting busy windows | High utilisation does not always mean user impact |
| Routing and adjacency state | Whether the network can actually reach its intended paths | BGP, OSPF, VPNs, SD-WAN, and failover checks | Can be stable while upstream performance is poor |
| Logs and syslog events | What changed, when it changed, and which device complained | Root-cause work and security investigation | Noisy unless you parse and filter them carefully |
| Flow data such as NetFlow or IPFIX | Who is talking to whom, how much, and over which path | Top talkers, application mix, traffic spikes, anomaly hunting | Sampling can hide short-lived details |
| Synthetic checks | What an outside user or branch actually experiences | Internet breakout, SaaS access, DNS, TLS, VPN, and API reachability | Only shows sampled journeys, not every real transaction |
Metrics tell you the shape of the problem. Logs tell you the event trail. Flows tell you the conversation. Traces are useful when you want to follow a request across services, and profiles matter when a host or gateway is CPU-bound rather than network-bound. I treat those as complementary views, not interchangeable ones. That distinction matters when you build the tooling around them.
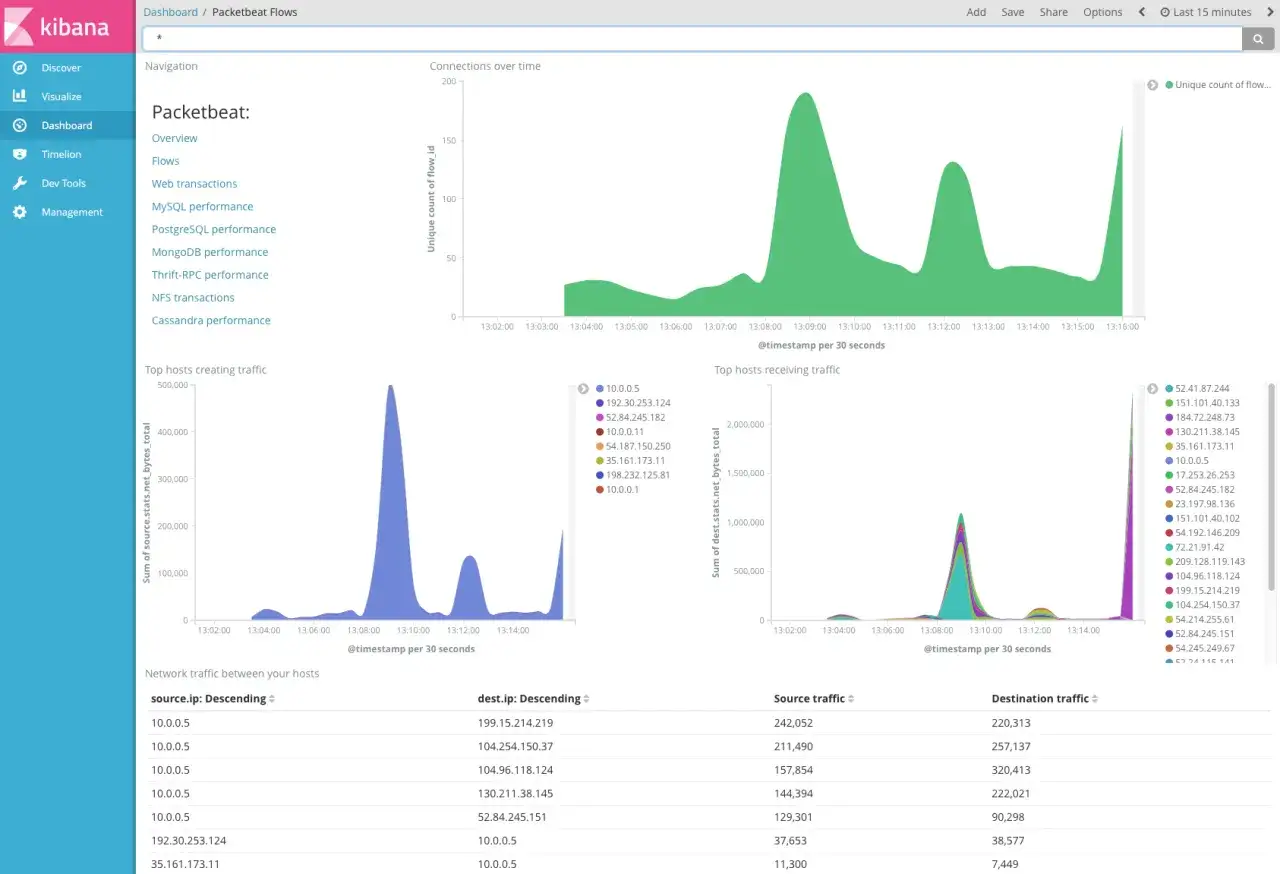
The tool stack I would use for a modern network
In 2026, I would not build this around SNMP alone. A workable stack usually combines legacy polling, streaming telemetry, flow export, synthetic checks, and one place where everything is correlated. Cisco’s telemetry guidance reflects this mix well: you want data from routers, switches, firewalls, servers, and cloud services, not just one layer of the stack.
| Tool or method | Best for | What it misses |
|---|---|---|
| SNMP polling | Broad compatibility and stable counters on older and mixed fleets | Short spikes and near-real-time changes |
| Streaming telemetry | Faster state changes and richer device data | Takes more design work and schema discipline |
| NetFlow, IPFIX, or sFlow | Traffic analysis, top talkers, and path usage | Deep packet detail and perfect per-flow precision |
| Syslog and event pipelines | Faults, authentication events, config changes, and security clues | Clean trend analysis unless you normalise the data |
| Prometheus-style metrics | Fast querying, alerting, and time-series analysis | Traffic conversation details on their own |
| Grafana-style dashboards | Correlation across metrics, logs, and flow views | They are only as good as the data underneath |
| Synthetic monitoring | User-path health from outside the network | Device internals and fine-grained root cause |
Prometheus is strongest when you expose metrics cleanly and keep them well labelled. Its recording rules are useful when a dashboard keeps recalculating the same expensive query, because precomputing those results keeps the interface responsive. That matters more than people think once an estate grows.
If I need one sentence for the architecture, it is this: use exporters or collectors for metrics, flow export for traffic behaviour, logs for events, and dashboards for correlation. A good exporter is simply a translator that turns another system’s data into something your monitoring stack can scrape. Without that translation layer, a lot of useful telemetry stays trapped in vendor-specific corners. From there, the real challenge becomes alerting without noise.
How to set alerts and baselines that people trust
The fastest way to ruin a monitoring programme is to turn every chart into a page. I prefer alerts that are tied to user impact or clear operational risk, and I prefer them to fire only after a condition has been sustained long enough to matter. As a starting point, a 5 to 10 minute window for paging is usually more useful than a one-off spike, while a 15 to 30 minute warning is often better for capacity drift and early degradation.
Baselines matter more than raw thresholds. A branch link at 70 percent utilisation during office hours may be fine, but the same number during a backup window or a software rollout can mean something very different. I usually separate baselines by site, time of day, and traffic class. If you only compare everything to one global threshold, you will either miss real problems or drown in false positives.
- Deduplicate aggressively. One failing circuit can trigger ten symptoms. Collapse them into one incident.
- Attach ownership. Every alert should point to a team, a runbook, and a likely next check.
- Suppress known work. Maintenance windows and change tickets should mute expected noise.
- Use recording rules or cached queries. Expensive dashboard expressions should not hammer your backend every refresh.
- Mix detection styles. Use rate-of-change alerts for capacity, and state-based alerts for outages.
Synthetic checks deserve their own cadence. For core internet-facing services, checking every 1 to 5 minutes is usually enough to catch real trouble without flooding the system. For critical internal services, I often pair those checks with a path-level metric so I can see whether the pain is in the network, the service, or the dependency chain. That is where observability becomes more than a buzzword.
Common mistakes that waste time and hide problems
The most common mistake is monitoring only the core and ignoring the edge. Branch circuits, VPN concentrators, wireless controllers, ISP handoffs, and cloud interconnects are often where users feel the pain first. If those links are invisible, the core can look healthy right up until the help desk gets overwhelmed.
Another mistake is relying on a single threshold. Utilisation alone is a weak signal unless you pair it with latency, loss, and trends. I also see teams over-collect raw data and under-invest in analysis. High-cardinality labels, meaning metrics broken down into too many unique values, can make dashboards slow and storage expensive without improving decisions.- Too many alerts, too little context. Noise trains people to ignore the system.
- Green dashboards that hide user pain. A chart can look fine while SaaS access is still broken.
- No retention plan. Raw telemetry kept forever becomes a cost problem and a privacy problem.
- No change correlation. If you cannot line up incidents with config changes, you lose the quickest path to root cause.
- No access control. Logs and network metadata often reveal far more than teams expect.
In the UK, I also treat telemetry governance as part of the design, not an afterthought. The ICO’s guidance is clear that monitoring, logging, regular review, and protection of logs are all part of good security practice. That matters because IP addresses, online identifiers, and other network data can be personal data, so retention and access need real ownership. Once the obvious mistakes are removed, you can roll the system out in a way that scales.
A rollout plan for a UK network estate
If I were starting from zero, I would not begin with every device. I would begin with the paths that matter most: office-to-cloud connectivity, site-to-site connectivity, internet breakout, VPN access, and the services that support them. That gives you a map of actual user risk instead of a wall of graphs.
- Map the critical paths. List the top applications, sites, and links that would hurt most if they failed.
- Enable the smallest useful telemetry set. Start with interface counters, routing state, syslog, and one active check per critical path.
- Baseline for at least 1 to 2 weeks. Capture weekdays, weekends, and any scheduled maintenance or backup windows.
- Add flow data where traffic questions remain. Use NetFlow, IPFIX, or sFlow when you need to know who is generating load.
- Connect alerts to ownership. Every key path should have a named responder and a short runbook.
- Review weekly. Remove alerts that did not help and tune the ones that did.
For UK estates specifically, I would keep separate baselines for branches, headquarters, and remote workers. A 50-seat office on a business circuit does not behave like a home user on consumer broadband, and a cloud region link does not behave like either of them. When you treat those as one population, your alert quality drops quickly. If the environment is mixed, the baselines must be mixed too.
Retention should also be intentional. I usually keep raw high-volume telemetry for 7 to 30 days, then keep rolled-up metrics for 90 to 180 days if the budget and compliance posture allow it. That is not a universal rule, but it is a sensible starting point for teams that want enough history to spot trends without turning storage into a second project.
What to keep visible after the first month
Once the first wave of dashboards is live, the job changes. You are no longer asking, “Can we see anything?” You are asking, “What do we keep because it changes decisions?” I would keep the top degraded links, the top noisy alerts, the current capacity forecast, the health of critical routes, and the last few incidents that teach the team something useful.
- Top degraded paths. These usually tell you where the next user complaint will come from.
- Capacity trend lines. Forecasting 30, 60, or 90 days ahead is often more valuable than a static usage chart.
- Incident-to-change links. If you can connect a problem to a rollout, you shorten root cause time.
- Security-relevant events. Authentication anomalies, config changes, and unusual flows deserve special attention.