Modern infrastructure rarely fails in one neat place. A slow DNS lookup can look like an application bug, a permissions change can look like a capacity problem, and a noisy alert can hide the real incident entirely. That is why infrastructure visibility matters: it gives operators a live picture of health, dependencies, and failure paths so they can act before customers feel the outage.
The short version for operators and platform teams
- Useful visibility combines metrics, logs, traces, dependency data, and change context.
- Monitoring tells you that something is wrong; observability helps explain why.
- Hybrid estates create blind spots at the boundaries between cloud, on-prem, edge, and SaaS.
- The fastest wins usually come from better alert quality, clearer ownership, and dependency mapping.
- A dashboard is only valuable if it helps you make a decision quickly.
What visibility means in practice
When I talk about operational visibility, I mean something much tighter than “we have a dashboard.” I mean the ability to answer, quickly and with confidence, four questions: what is healthy, what is degraded, what changed, and what is at risk. That covers infrastructure layers such as compute, storage, network, identity, and the services sitting on top of them.In practice, that also means I can follow a request across the environment without guessing. If checkout slows down, I want to know whether the bottleneck is in a database, a container cluster, a service dependency, a load balancer, or a third-party API. The system should show me the path, not just the symptom.
I also care about context. A CPU spike is interesting; a CPU spike on a payment node right after a deployment is useful. The second one tells me where to look first and whether I need to roll back, scale, or investigate a wider failure domain. Once you define visibility that way, the next question is why so many environments still struggle to achieve it.
Why modern estates hide problems so easily
By 2026, most teams are running mixed environments. Public cloud, private data centres, SaaS platforms, branch connectivity, and containerised services all sit in the same operational picture. That mix is powerful, but it also breaks the old assumption that one tool can tell you everything.
The hardest part is that modern infrastructure is dynamic. Virtual machines get replaced, containers disappear and reappear, autoscaling shifts load in the background, and managed services hide the lower layers entirely. You may see the effect of a problem long before you see the cause. That is especially true when identity, DNS, or network policy sits between the user and the application.
For UK organisations, the pattern is familiar: a single incident can cross a London office network, a cloud region, and a SaaS identity provider in a few seconds. The failure may belong to one team, but the impact belongs to all of them. The result is not just slower troubleshooting. It is false confidence, because the estate looks “up” until a customer journey breaks.
That is why the design of the telemetry stack matters more than the brand of the tool. If the signals are fragmented, the environment stays opaque even when every component is technically reporting data. The next section is the one I use to check whether a stack is actually giving me the truth.
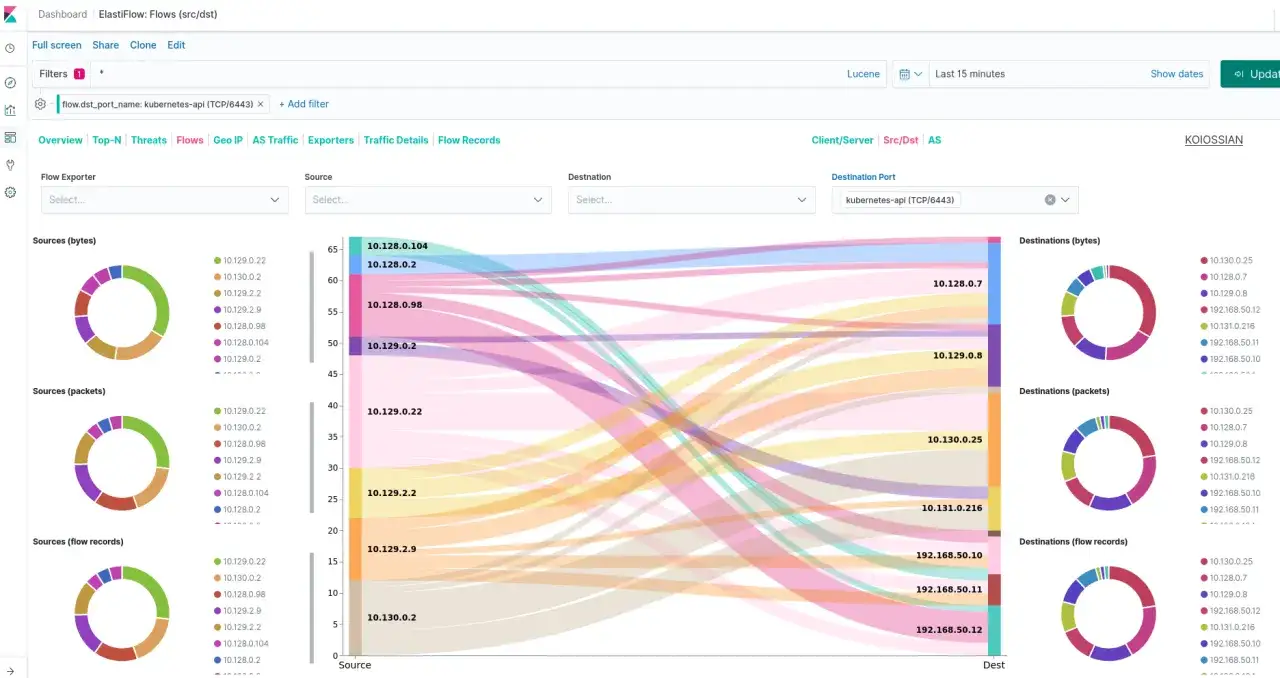
What a useful telemetry stack should show
I usually think of telemetry as a ladder. Metrics tell me something is off, logs explain what happened, traces show where the request travelled, and dependency data shows what the affected system relies on. A good stack gives me all four, plus enough context to connect them.
| Signal | What it tells you | Where it helps most |
|---|---|---|
| Metrics | Trends in latency, error rates, saturation, and throughput | Early warning, SLO tracking, and capacity drift |
| Logs | Detailed event records and error messages | Root cause analysis and exact failure detail |
| Traces | The path a request takes through services | Distributed systems, microservices, and bottleneck hunting |
| Events | What changed and when | Deployments, config changes, patching, and incident correlation |
| Topology data | Which component depends on what | Blast-radius analysis and ownership routing |
| Synthetic checks | How the system behaves from the outside | User-facing availability, login flows, and API validation |
In the real world, the missing piece is often change data. I want to see what was deployed, what was patched, what configuration shifted, and what dependency was added or removed. Without that, teams spend too long staring at normal-looking graphs while the actual problem sits in the last release. I also like to include identity and network signals, because authentication failures and routing issues often masquerade as application bugs.
That mix of signals is what turns raw data into something actionable. Once you know what should be visible, the practical question becomes how to build that capability without creating another expensive, noisy layer of tooling.
How I would build the stack from scratch
If I were rolling this out for a platform team, I would start with the journeys that matter most to the business, not with the prettiest dashboard. The first goal is to make the critical path visible, because that is where outages hurt and where fast feedback pays off.
- Pick the top user journeys. Choose the flows that most affect revenue, support load, or customer trust, such as sign-in, checkout, API access, or data sync.
- Define service level objectives, or SLOs. These are the internal reliability targets that tell you whether a service is meeting expectations, not just whether it is running.
- Instrument the estate consistently. Use a vendor-neutral approach such as OpenTelemetry, which is a standard for collecting and exporting telemetry, so you are not locked into one platform’s view of the world.
- Correlate signals end to end. Add request IDs, service names, environment tags, and deployment markers so a metric spike can be tied to a request path and a change event.
- Turn alerts into actions. Every important alert should have an owner, a clear threshold, and a runbook, which is a step-by-step response guide for the on-call team.
- Review and prune after incidents. If an alert did not help a human make a better decision, remove it or rewrite it. Alert noise is one of the fastest ways to destroy trust in the system.
Two habits make this work better than most teams expect. First, I anchor alerts to business impact instead of raw thresholds alone, because a resource warning is not always a customer problem. Second, I use synthetic checks from the outside as a sanity test, because internal health can look fine while the user journey is broken. That distinction is easy to miss until the first real incident.
Once the basics are in place, you can add automation and AI-assisted triage, but I would treat those as accelerators rather than foundations. Clean telemetry and clear ownership still matter more than clever assistance.
Monitoring versus observability and why both still matter
I treat monitoring as the tripwire and observability as the map. Monitoring is best at detecting known failure patterns and alerting the right people quickly. Observability is better at explaining unfamiliar behaviour, especially when several components interact in ways you did not model in advance.They are not competing ideas, and one does not replace the other. If you only monitor, you often know that something is broken but not why. If you only chase observability, you can end up with rich data and weak operational discipline. The best teams combine both.
| Aspect | Monitoring | Observability |
|---|---|---|
| Main job | Detect known issues | Explain unknown or complex issues |
| Typical output | Alerts, thresholds, dashboards | Correlated telemetry, traces, investigation context |
| Best use case | Watching service health and SLOs | Root cause analysis and dependency analysis |
| Main weakness | Can miss hidden failure modes | Can become expensive or noisy without discipline |
In other words, monitoring tells you where to look first; observability helps you understand what you are seeing. I would not remove either from a serious operations stack. I would make sure each one has a clear job, because confusion between them is one of the reasons teams build expensive systems that still feel blind. The next pitfall is even more common: dashboards that look healthy while the estate is quietly drifting out of control.
The mistakes that make dashboards look better than reality
- Measuring everything except the critical path. A wide dashboard can hide the one service that actually matters to the user journey.
- Alerting on raw thresholds alone. High CPU or memory can be a symptom, not a cause, and often needs context before anyone should wake up.
- Ignoring change events. If you cannot see deployments, patches, and config changes next to your telemetry, incidents take longer to explain.
- Collecting logs without curating them. Retaining every noisy line is not the same as having the right evidence when the incident starts.
- Leaving network, identity, and third-party services out of the picture. Those are frequent failure points, and they often look like application problems from the outside.
- Letting alerts float without an owner. If nobody is accountable for response and escalation, the alert is just background noise.
- Assuming a green dashboard means a healthy service. A dashboard that cannot answer a support question in five minutes is decoration, not operational control.
The fix is usually not another tool. It is better signal design, better ownership, and better correlation. That leads to a final question: what should you prioritise first if you are trying to improve the estate without boiling the ocean?
The minimum baseline I would ship first
If I had to improve a platform quickly, I would focus on five moves. They are simple, but they tend to create more value than a long list of disconnected upgrades.
- Map the most important user journeys and their dependencies.
- Set a small number of SLOs that reflect actual business risk.
- Standardise telemetry so metrics, logs, traces, and events can be linked.
- Attach every critical alert to an owner and a runbook.
- Validate availability from the outside with synthetic checks.
That baseline will not solve every incident, but it will cut through a lot of confusion. If your team can answer, within minutes, what is affected, what changed, who owns it, and whether customers are seeing it, you have a workable operational model. Anything less is just data collection with a nicer interface.