The practical reality is that dynatrace ports usually boil down to a short list: 443 for the platform, 9999 for the main ActiveGate listener, and a few extra listeners when you move into Kubernetes or OpenTelemetry. I’m going to unpack what each port does, when the defaults change, and how to build firewall rules that do not collapse the first time traffic takes a fallback path. That is the useful part here: not a list of numbers, but a working network model you can actually apply.
The shortest useful version is a small, configurable port set
- 9999 is the core listener for Environment ActiveGate traffic from OneAgents and other gateway-to-gateway connections.
- 443 is the outbound path to Dynatrace SaaS or Managed from ActiveGate and the default SaaS OTLP endpoint.
- Kubernetes adds control-plane and probe ports such as 8443, 8080, 10080, 9808, 10090, and 53.
- ActiveGate can be reconfigured, so the safe rule is always the one that matches your actual topology.
- Proxies, reverse proxies, and load balancers need explicit configuration; they are not inferred automatically.
The default port map I start with
I start with three questions: where does traffic enter, where does it leave, and which hop is optional. On a classic host install, ActiveGate listens on 9999 for OneAgents and other ActiveGates, accepts Dynatrace API traffic on the same port, and then connects outbound to 443 on Dynatrace SaaS or Managed. That pattern repeats for OTLP: SaaS uses 443, while Environment ActiveGate uses 9999.
| Path | Default port | Direction | Why it matters |
|---|---|---|---|
| OneAgent or another ActiveGate to Environment ActiveGate | 9999 | Inbound to ActiveGate | Main secure listener for host traffic and local gateway hops |
| ActiveGate to Dynatrace SaaS or Managed | 443 | Outbound | Platform communication, updates, and cloud access |
| OTLP exporters to Dynatrace SaaS | 443 | Outbound | Native OpenTelemetry ingest without a local gateway |
| OTLP exporters to Environment ActiveGate | 9999 | Outbound to ActiveGate | Local ingest path when you want traffic to stay inside the network |
If I need to harden the edge, I keep 9999 limited to the networks that actually host agents or application pods. I would not expose it broadly just because it is convenient to remember; the safe rule is the one that mirrors your topology. That core map is the easy part, though. The interesting questions start when traffic chooses a path, not just a port.
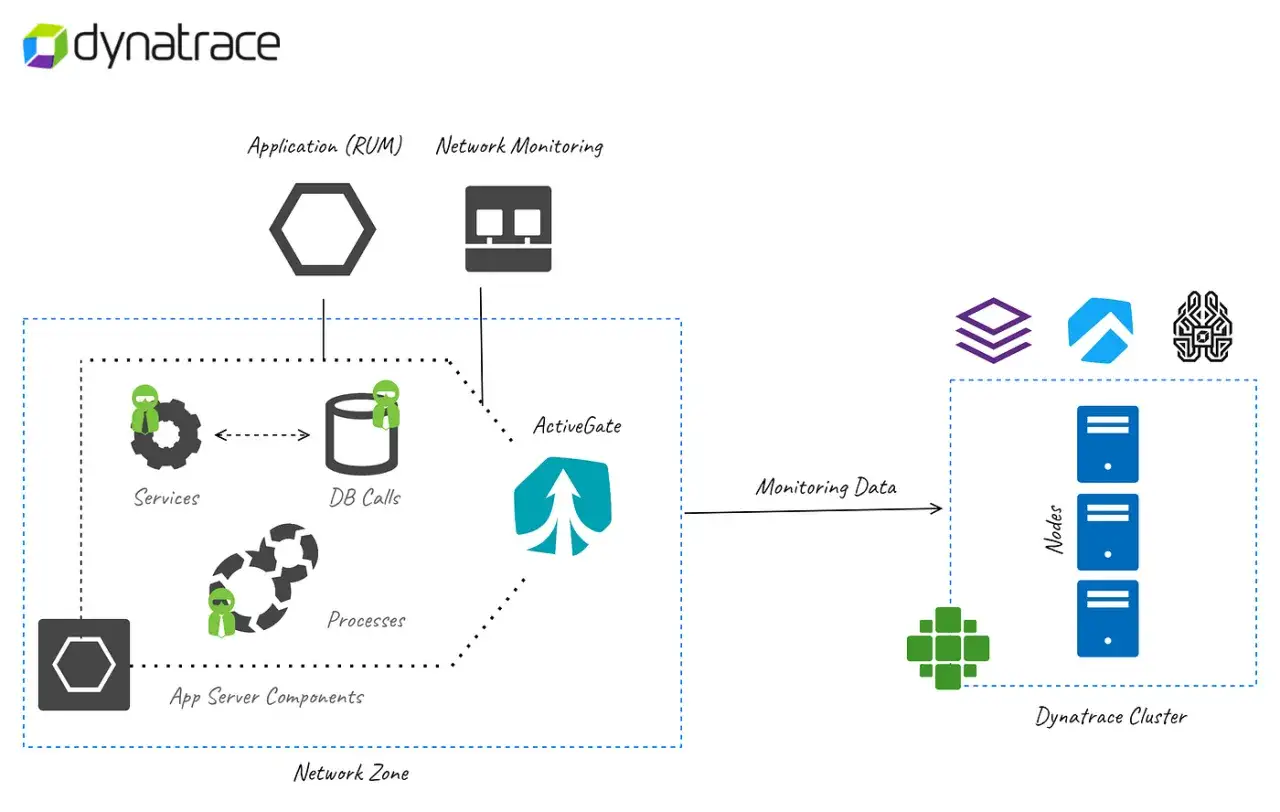
How traffic actually flows between agents and the platform
I treat ActiveGate less like a service endpoint and more like a local traffic broker. Dynatrace prefers the Environment ActiveGate when it is available, and OneAgents can fall back to the SaaS cluster directly if they cannot reach one. The direction matters: it is the component that initiates the connection that drives the firewall rule, not the label on the box.
That is also why proxies and load balancers need explicit treatment. Dynatrace does not magically infer a reverse proxy in front of ActiveGate, so if you place one there, you have to tell the platform where the real entry point lives. The same logic applies to private Synthetic locations and extensions: the gateway needs access to the monitored resource, not merely to Dynatrace itself.
In other words, topology decides the rule set. Once you understand that direction of travel, the next question is whether you should ever move the listener away from its defaults.
When I change a port and when I do not
My default answer is to leave the ports alone. Moving the HTTPS listener only makes sense when a platform standard, a reverse proxy design, or a hard collision forces it. ActiveGate exposes an HTTPS port setting you can change with agctl ssl-port, and the configuration is explicitly designed to allow that customisation.
There are a few practical exceptions. Containerised ActiveGate still opens HTTPS on 9999 by default, but plain HTTP can be enabled explicitly and then runs on 8888. I only use that path when I genuinely need HTTP inside a controlled environment; otherwise I prefer to keep everything on TLS and avoid creating a second rule set to maintain.
If you do move the listener, update the OTLP base URL, the firewall documentation, any synthetic or extension notes, and any health checks that still expect the old value. A port change that is not propagated everywhere is just a future outage with better formatting. After that, Kubernetes is where the same product exposes a wider control-plane surface.
The Kubernetes ports that matter most
Kubernetes broadens the picture because Dynatrace Operator, the webhook, the CSI driver, ActiveGate, and sometimes Extension Execution Controller each own a different slice of traffic. Most of those listeners are control-plane or health ports, not data-plane ports, so I separate them from the normal agent-to-gateway flow when I document the network.
| Component | Port | Direction | Why I care |
|---|---|---|---|
| Dynatrace Webhook from kube-apiserver | 8443 | Inbound to webhook | Admission controller traffic for inject, label, and validate operations |
| Dynatrace Operator and webhook health checks | 10080 | Inbound | Liveness and readiness probes from kubelet |
| Operator and webhook metrics | 8080 | Inbound, optional | Prometheus scraping when you want operator metrics |
| CSI driver health checks | 9808 and 10090 | Inbound | Container probes for the server and provisioner containers |
| Application pods to ActiveGate | 9999 | Outbound from pods | Default HTTPS port for ingest and API access |
| Application pods to ActiveGate | 9998 | Outbound from pods | Default HTTP port, used only when you intentionally enable it |
| DNS resolution for the operator namespace | 53 TCP and UDP | Outbound | Service discovery and hostname resolution |
| ActiveGate to Dynatrace server or communication endpoints | 443 and 9999 | Outbound | Observability data, cluster communication, and fallback connectivity |
The detail I would not skip is DNS. If the operator namespace cannot resolve names, the rest of the port list becomes irrelevant because the components cannot even find the endpoints they are meant to reach. That is one of the quietest failure modes in a segmented cluster. With that surface in mind, the real design work becomes deciding what to allow and from where.
Firewall rules that keep the setup predictable
I prefer a least-privilege allowlist that follows the flow of data rather than a broad “allow Dynatrace” rule. In practice, that means outbound 443 from ActiveGate to the SaaS or Managed endpoint, inbound 9999 only from the subnets that truly host agents or application pods, and DNS on 53 TCP/UDP wherever Kubernetes components need it.
- Allow 443 outbound from ActiveGate to the platform if you use SaaS, Managed, or OTLP to SaaS.
- Allow 9999 inbound only from trusted workloads that legitimately talk to Environment ActiveGate.
- Allow 8443 inbound to the webhook only when you run the Kubernetes admission controller.
- Allow 8080, 9808, and 10090 only if you scrape those health or metrics endpoints.
- Allow 9998 only when you intentionally enable plain HTTP on ActiveGate.
- Model proxies and load balancers explicitly so the allowlist matches the real hop, not the idealised one.
I also keep private Synthetic in its own mental bucket. A gateway that can reach Dynatrace but cannot reach the target application is technically healthy and operationally useless. That distinction saves time during rollout reviews.
When something still fails, I move from design to diagnosis.
What I check first when telemetry stops flowing
Most port incidents are not mysterious. They are either a blocked listener, a hostname mismatch, or a configuration change that was never propagated. I start by asking which hop failed first, because that tells me whether I am dealing with a network issue, a TLS issue, or a URL issue.
| Symptom | Likely first suspect | What I check |
|---|---|---|
| OneAgent stops reporting | 9999 is blocked or ActiveGate listener moved | ActiveGate health, firewall rule, port setting, DNS, certificate trust |
| OTLP ingest fails | Wrong SaaS or ActiveGate base URL, or blocked 443/9999 | Endpoint host, port, token, and any accidental .apps typo in the SaaS URL |
| Kubernetes webhook errors | 8443 is blocked | kube-apiserver reachability to the webhook |
| Metrics do not appear | 8080 scrape path is not allowed or not enabled | Scraper configuration and service exposure |
| TLS errors after a change | Certificate chain or trust store issue | Hostname, CA bundle, and custom certificate configuration |
If the failure appears only after you changed a listener, assume the stale reference first. I have seen teams spend hours on packet captures when the real issue was that one OTLP exporter still pointed at the old 9999 endpoint. The simplest explanation is often the correct one. From there, the cleanest answer is usually a tighter, well-documented allowlist rather than a bigger one.
The smallest safe allowlist I would keep in most estates
If I were standardising this for a UK estate with segmented networks, I would begin with a compact baseline and only add what the deployment actually uses. The baseline is simple: 443 outbound to Dynatrace SaaS or Managed, 9999 for ActiveGate listener traffic, and 53 for DNS where Kubernetes is involved. Everything else is conditional.
- Add 8443 only if the Kubernetes webhook is in play.
- Add 8080, 9808, and 10090 only if your probes or metrics scrapers need them.
- Add 9998 only if you have a deliberate HTTP path on ActiveGate.
- Document any proxy or load balancer in the same runbook as the port rule, because they are part of the control plane, not an implementation detail.
- Re-test after upgrades, especially when you change ActiveGate purpose, add synthetic monitoring, or move to a new Kubernetes operator version.
The best port strategy is the one that stays boring after the first deployment: few exceptions, explicit ownership, and no guesswork about which component is allowed to talk to whom.